




Mysql 主从复制涉及的参数比较多,而且比较细,有时候需要翻源码才明白所以.很多参数官方网站的解释都有点模拟两可.很多大佬的图也容易让人迷糊!
主要参数
+--------------------------------------------+-------+
|innodb_flush_log_at_trx_commit | 1 |
| sync_binlog | 1 |
|innodb_flush_method | |
|innodb_flush_neighbors | 1 |
|innodb_flush_sync | ON |
|binlog_group_commit_sync_delay | 80 |
|binlog_group_commit_sync_no_delay_count | 8 |
|innodb_use_fdatasync | OFF |
| sync_binlog | 1 |
半同步插件
#######安装半同步插件#########################################
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';
Query OK, 0 rows affected (0.19 sec)
mysql> show variables like '%semi%';
+-------------------------------------------+------------+--------------------------+
| Variable_name | Value | 中文解释 |
+-------------------------------------------+------------+--------------------------+
| rpl_semi_sync_master_enabled | OFF | 开启半同步 |
| rpl_semi_sync_master_timeout | 10000 | 毫秒 超时 |
| rpl_semi_sync_master_trace_level | 32 | 跟踪层次 |
| rpl_semi_sync_master_wait_for_slave_count | 1 | 等待从库数量 |
| rpl_semi_sync_master_wait_no_slave | ON |要等待丛库确认收到 |
| rpl_semi_sync_master_wait_point | AFTER_SYNC |到从库前不被其他会话可见 |
+-------------------------------------------+------------+--------------------------+
6 rows in set (0.00 sec)
REDO LOG
在线日志涉及一个参数: innodb_flush_log_at_trx_commit
官网解释:
· innodb_flush_log_at_trx_commit
Command-Line Format | --innodb-flush-log-at-trx-commit=# |
System Variable | innodb_flush_log_at_trx_commit |
Scope | Global |
Dynamic | Yes |
SET_VAR Hint Applies | No |
Type | Enumeration |
Default Value | 1 |
Valid Values | 0,1,2 |
· Controls the balance between strict ACID compliancefor commit operations and higher performance that is possiblewhen commit-related I/O operations are rearranged and done in batches. You canachieve better performance by changing the default value but then you can losetransactions in a crash.
o The default setting of 1 is required for full ACIDcompliance. Logs are written and flushed to disk at each transaction commit.
o With a setting of 0, logs are written and flushed to diskonce per second. Transactions for which logs have not been flushed can be lostin a crash.
o With a setting of 2, logs are written after eachtransaction commit and flushed to disk once per second. Transactions for whichlogs have not been flushed can be lost in a crash.
o For settings 0 and 2, once-per-second flushing is not100% guaranteed. Flushing may occur more frequently due to DDL changes andother internal InnoDB activitiesthat cause logs to be flushed independently of the innodb_flush_log_at_trx_commit setting,and sometimes less frequently due to scheduling issues. If logs are flushedonce per second, up to one second of transactions can be lost in a crash. Iflogs are flushed more or less frequently than once per second, the amount oftransactions that can be lost varies accordingly.
o Log flushing frequency is controlled by innodb_flush_log_at_timeout,which allows you to set log flushing frequency to N seconds (where N is 1 ... 2700, with a default value of 1). However,any unexpected mysqld process exitcan erase up to N seconds oftransactions.
o DDL changes and other internal InnoDB activities flush the logindependently of the innodb_flush_log_at_trx_commit setting.
o InnoDB crash recovery works regardless ofthe innodb_flush_log_at_trx_commit setting.Transactions are either applied entirely or erased entirely.
For durability and consistency in areplication setup that uses InnoDB withtransactions:
o If binary logging is enabled, set sync_binlog=1.
o Always set innodb_flush_log_at_trx_commit=1.
For information on the combination of settingson a replica that is most resilient to unexpected halts, see Section 17.4.2,“Handling an Unexpected Halt of a Replica”.
Caution
Many operating systems and some diskhardware fool the flush-to-disk operation. They may tell mysqld that theflush has taken place, even though it has not. In this case, the durability oftransactions is not guaranteed even with the recommended settings, and in theworst case, a power outage can corrupt InnoDB data. Using a battery-backed diskcache in the SCSI disk controller or in the disk itself speeds up file flushes,and makes the operation safer. You can also try to disable the caching of diskwrites in hardware caches.
看不懂不要紧我们从架构师抠图来看
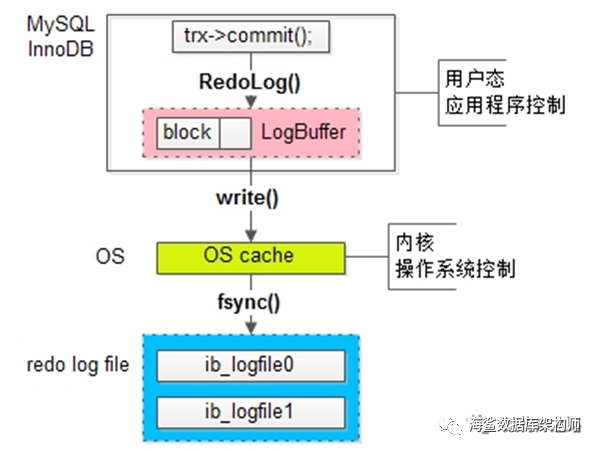
大意是日志写入日志文件ib_logfile0 和ib_logfile1 要经过OS操作系统的中间商的同意. 先从LOGBUFFER 通过write()函数写入OS CACHE里. 然后由中间商OS去写入文件,这里调用fsync() 操作系统函数也叫内核函数; 这个动作叫flush!
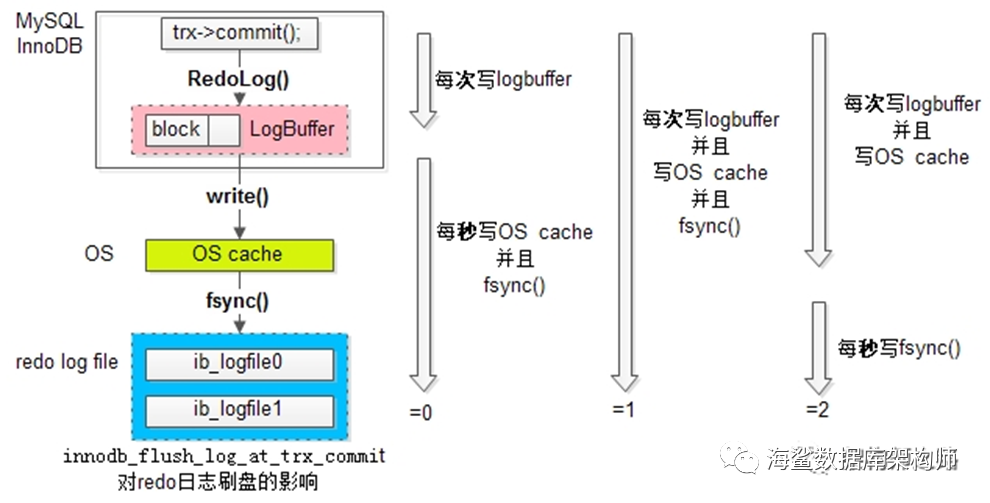
这个参数innodb_flush_log_at_trx_commit 有三个取向.注意这个图,其实它是三层,第一层是每次事务要写LOGBUF时通过REDOLOG()函数写,把本事务的日志写入BUF里;
第二层LOGBUF日志写入OS CACHE 通过WRITE() 函数;
第三层OS CACHE 里的日志写入日志文件.
策略一:最佳性能(innodb_flush_log_at_trx_commit=0)每隔一秒,MASTER线程才将Log Buffer中的数据批量write()入OS cache,
同时MySQL主动fsync。这种策略,如果数据库崩溃,有一秒的数据丢失。
策略二:强一致(innodb_flush_log_at_trx_commit=1)每次事务提交,MASTER线程都将Log Buffer中的数据write()入OS cache,
同时MySQL主动fsync。这种策略,是InnoDB的默认配置,为的是保证事务ACID特性。
策略三:折衷(innodb_flush_log_at_trx_commit=2)每次事务提交,都将Log Buffer中的数据write入OS cache;
每隔一秒,MySQL主动将OS cache中的数据批量fsync。
这里或许没有说得比较明白; 这里暗指是事务提交后,日志开始写; 事务日志写完后,这里指事务把自己的日志写入LOG BUF里; 然后由该参数控制该怎么写入日志文件.
其实事务运行期间都会产生日志,要么学ORACLE,每个事务都有私有日志BUF,当事务完成后一次性把私钥日志写入公共日志区LOG BUF; 如果每个回话没有自己的私有日志的话,那么上图trx->commit() 就是错误的; 按原理来说每个事务开始前都要申请到LOG BUF,然后每次产生日志时都要写入LOG BUF; 这样日志文件就会包含未提交的事务,日后就做回滚.
当然这个参数就是在事务提交的时候就被激发.
innodb_flush_log_at_trx_commit=0 事务提交被忽略由MASTER线程去完成;MASTER完成随后两层的操作WRITE()+FSYNC();
innodb_flush_log_at_trx_commit=1 事务提交后激发MASTER去干活并且等待它完成的消息; 三个步骤是联动的.
innodb_flush_log_at_trx_commit=2 事务提交后写入LOG BUF 并且写入OSCACHE; 然后由谁去同步到日志文件中;
这个2是事务本身线程写入OS CACHE ? 还是由MASTER去写? FSYNC()由哪个线程完成OS_CACHE到日志文件这步?由MASTER线程,还是OS自己去做?
源码翻看
/**********************************************************************//**
If required, flushes the log to disk based on the value ofinnodb_flush_log_at_trx_commit. */
Static void trx_flush_log_if_needed_low( lsn_t lsn) /*!< in: lsn up to which logs are to be flushed. */
{
#ifdef _WIN32
bool flush = true;
#else
bool flush = srv_unix_file_flush_method != SRV_UNIX_NOSYNC;
#endif /* _WIN32 */
switch (srv_flush_log_at_trx_commit) {
case 2:
/* Write the log but do not flush it to disk */
flush = false;
/* fall through */
case 1:
/* Write the log and optionally flush it to disk */
log_write_up_to(lsn, flush);
return;
case 0:
/* Do nothing */
return;
}
ut_error;
}
log_write_up_to()
log_write_flush_to_disk_low();
fil_flush(group->space_id); os_event_set(log_sys->flush_event);
源代码里没有说清楚,0 不做任何事; 2 不同步也没有调用其它函数;1 调用写函数且要求同步
BINLOG 相关参数
#****************BINLOGS SETTING*********************
log-bin=/u01/mysql8/binlog/binlog
binlog-checksum=CRC32
binlog_cache_size = 2M ##Per Sessions
binlog_format=row
max_binlog_size=512M ##日志文件大小
max_binlog_cache_size=2147483648 ##最大
max_binlog_stmt_cache_size ##非事务语句
#expire_logs_days=15 ##自动清理1天前的log文件
binlog_expire_logs_seconds= 1296000 ## 自动清理15前的log文件
sync_binlog=1 ##同步到磁盘上
binlog_group_commit_sync_delay = 80 ##80毫秒组提交
binlog_group_commit_sync_no_delay_count = 8 ##8个事务组提交
系统变量binlog_cache_size 表示为每个客户端分配binlog_cache_size大小的缓存,默认值32768。类似于ORACLE的LOGBUUFER,不过它是每个会话。
系统变量max_binlog_cache_size 二进制日志能够使用的最大cache内存大小。当执行多语句事务时,max_binlog_cache_size 如果不够大,系统可能会报出“Multi-statement transaction required more than‘max_binlog_cache_size’ bytes of storage”的错误。
系统变量max_binlog_stmt_cache_size
max_binlog_cache_size针对事务语句,max_binlog_stmt_cache_size针对非事务语句,当我们发现Binlog_cache_disk_use或者Binlog_stmt_cache_disk_use比较大时就需要考虑增大cache的大小
系统变量max_binlog_size,表示二进制日志的最大值,一般设置为512M或1GB,但不能超过1GB。该设置并不能严格控制二进制日志的大小,尤其是二进制日志比较靠近为不而又遇到一根比较大事务时, 为了保证事务的完整性,不可能做切换日志的动作,只能将该事务的所有SQL都记录进当前日志,直到事务结束。
系统变量binlog_checksum 用作复制的主从校检。NONE表示不生成checksum,CRC-32表示使用这个算法做校检。
系统变量sync_binlog,这个参数对于Mysql系统来说是至关重要的,它不仅影响到二进制日志文件对MySQL所带来的性能损耗,而且还影响到MySQL中数据的完整性。
sync_binlog=0,当事务提交后,Mysql仅仅是将binlog_cache中的数据写入binlog文件的系统缓存,但不执行fsync之类的磁盘同步指令通知文件系统将缓存刷新到磁盘,而是让Filesystem自行决定什么时候来做同步。MySQL中默认的设置是 sync_binlog=0,即不作任何强制性的磁盘刷新指令,这个设置性能是最好的,但风险也是最大的。一旦系统崩溃(Crash),在文件系统缓存中的所有二进制日志信息都会丢失。从而带来数据不完整问题。
sync_binlog=n,在进行n次事务提交以后,Mysql将执行一次fsync之类的磁盘同步指令,同时文件系统将Binlog文件缓存刷新到磁盘。
可以适当的调整sync_binlog,在牺牲一定的一致性下,获取更高的并发和性能。
INNODB_FLUSH_METHOD
该参数来控制INNODB引擎FLUSH行为; 包含日志和数据文件;
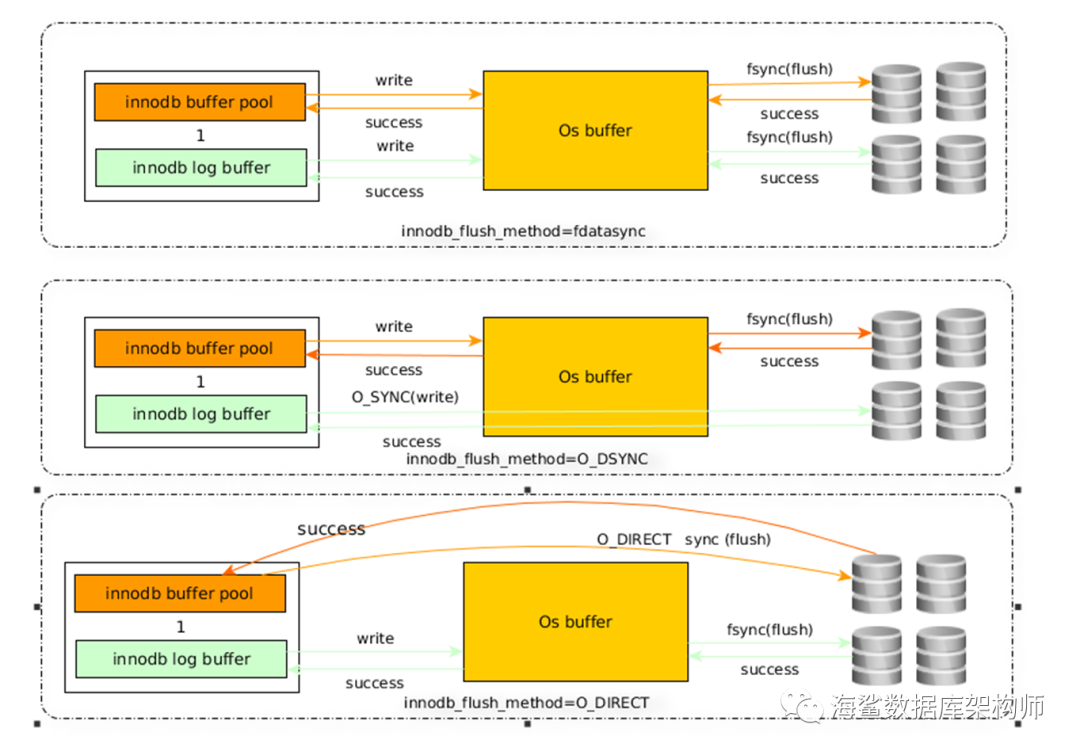
解释
innodb_flush_method=fdatasyncMYSQL 写入OSCACHE 后立马返回OK给用户(应用程序)这里包含日志和文件
innodb_flush_method=O_DSYNCMYSQL 写入OSCACHE 后如果是数据文件就立马返回OK给用户(应用程序),要是日志文件则等待正在写入磁盘上才返回OK
innodb_flush_method=O_DIRECTMYSQL 写入OSCACHE 后如果是日志文件就立马返回OK;数据文件则不写OSCACHE 直接读写文件,且同步数据文件元数据信息;
那么与innodb_flush_log_at_trx_commit参数控制日志FLUSH 行为发生冲突
innodb_flush_log_at_trx_commit=1& innodb_flush_method=fdatasync(fsync);
有人说innodb_flush_log_at_trx_commit 控制何时做,innodb_flush_method控制怎么做.
好像是怎么回事,不过又相互干涉了.它们两的排列组合
innodb_flush_log_at_trx_commit | innodb_flush_method | |
0 | fsync | 每隔1秒由master线程完成write+fsync (成功信息在两个函数之间传递) |
1 | fsync | 事务提交并等待由master线程完成write+fsync(成功信息在两个函数之间传递) |
2 | fsync | 事务提交不知道谁写入OS_CACHE[write],不知道谁每隔1秒fsync fsync成功信息返回不了上一层事务 |
0 | O_DSYNC | 每隔1秒由master线程完成write+fsync (write+fsync 是同步) |
1 | O_DSYNC | 事务提交并等待由master线程完成write+fsync (write+fsync 是同步) |
2 | O_DSYNC | 事务提交不知道谁写入OS_CACHE[write],不知道谁每隔1秒fsync 与 (write+fsync 是同步) 发生冲突 |
0 | O_DIRECT | 日志文件跟FSYNC模式一样,只是数据文件直接读写 |
1 | O_DIRECT | |
2 | O_DIRECT |
给人感觉确实相互干扰了,
innodb_flush_log_at_trx_commit=1& innodb_flush_method=O_DIRECT 就是标配了!
LINUX 下文件打开标志:
对象 | O_DIRECT | O_DSYNC/fdatasync() | O_SYNC/fsync() | |
page cache | 缓冲内存结构数据 | write bypass | write & flush | write & flush |
buffer cache | 缓冲内存块设备数据 | write bypass | write & flush | write & flush |
inode cache | 缓冲inode | write & no flush | write & no flush | write & flush |
dictory cache | 缓冲目录结构数据 | write & no flush | write & no flush | write & flush |
l O_DSYNC和fdatasync()的区别在于:是在每一个IO提交的时刻都针对对应的page cache和buffer cache进行刷新(即O_DSYNC,在write操作成功返回前已完成刷新);还是在一定数据的写操作以后调用fdatasync()的时刻对整个page cache和buffer cache进行刷新。O_SYNC和fsync()的区别同理。
l page cache和buffer cache的主要区别在于一个是面向实际文件数据,一个是面向块设备。在VFS上层使用open()方式打开那些使用mkfs做成文件系统的文件,你就会用到page cache和buffer cache,而如果你在Linux操作系统上使用dd这种方式来操作Linux的块设备,你就只会用到buffer cache。
l O_DSYNC和O_SYNC的区别在于:O_DSYNC告诉内核,当向文件写入数据的时候,只有当数据写到了磁盘时,写入操作才算完成(write才返回成功)。O_SYNC比O_DSYNC更严格,不仅要求数据已经写到了磁盘,而且对应的数据文件的属性(例如文件inode,相关的目录变化等)也需要更新完成才算write操作成功。可见O_SYNC较之O_DSYNC要多做一些操作。
l Open()的referense中还有一个O_ASYNC,它主要用于terminals, pseudoterminals, sockets, 和pipes/FIFOs,是信号驱动的IO,当设备可读写时发送一个信号(SIGIO),应用进程捕获这个信号来进行IO操作。
l O_SYNC和O_DIRECT都是同步写,也就是说只有写成功了才会返回。
回过头来,我们再来看innodb_flush_log_at_trx_commit的配置就比较好理解了。O_DIRECT直接IO绕过了pagecache/buffer cache以后为什么还需要fsync()了,就是为了把directory cache和inode cache元数据也刷新到存储设备上。
而由于内核和文件系统的更新,有些文件系统能够保证保证在O_DIRECT方式下不用fsync()同步元数据也不会导致数据安全性问题,所以InnoDB又提供了O_DIRECT_NO_FSYNC的方式。
当然,O_DIRECT对读和对写都是有效的,特别是对读,它可以保证读到的数据是从存储设备中读到的,而不是缓存中的。避免缓存中的数据和存储设备上的数据是不一致的情况(比如你通过DRBD将底层块设备的数据更新了,对于非分布式文件系统,缓存中的内容和存储设备上的数据就不一致了)。但是我们这里主要讨论缓冲(写buffer),就不深入讨论了。这个问题了。
3.2. O_DIRECT优劣势
在大部分的innodb_flush_method参数值的推荐中都会建议使用O_DIRECT,甚至在percona server分支中还提供了ALL_O_DIRECT,对日志文件也使用了O_DIRECT方式打开。
3.2.1. 优势:
l 节省操作系统内存:O_DIRECT直接绕过pagecache/buffer cache,这样避免InnoDB在读写数据少占用操作系统的内存,把更多的内存留个innodb buffer pool来使用。
l 节省CPU。另外,内存到存储设备的传输方式主要有poll,中断和DMA方式。使用O_DIRECT方式提示操作系统尽量使用DMA方式来进行存储设备操作,节省CPU。
3.2.2. 劣势
l 字节对齐。O_DIRECT方式要求写数据时,内存是字节对齐的(对齐的方式根据内核和文件系统的不同而不同)。这就要求数据在写的时候需要有额外的对齐操作。可以通过/sys/block/sda/queue/logical_block_size知道对齐的大小,一般都是512个字节。
l 无法进行IO合并。O_DIRECT绕过pagecache/buffer cache直接写存储设备,这样如果对同一块数据进行重复写就无法在内存中命中,page cache/buffer cache合并写的功能就无法生效了。
l 降低顺序读写效率。如果使用O_DIRECT打开文件,则读/写操作都会跳过cache,直接在存储设备上读/写。因为没有了cache,所以文件的顺序读写使用O_DIRECT这种小IO请求的方式效率是比较低的。
总的来说,使用O_DIRECT来设置innodb_flush_method并不是100%对所有应用和场景都是适用的。
BINLOG& REDO LOG 配合的两段提交
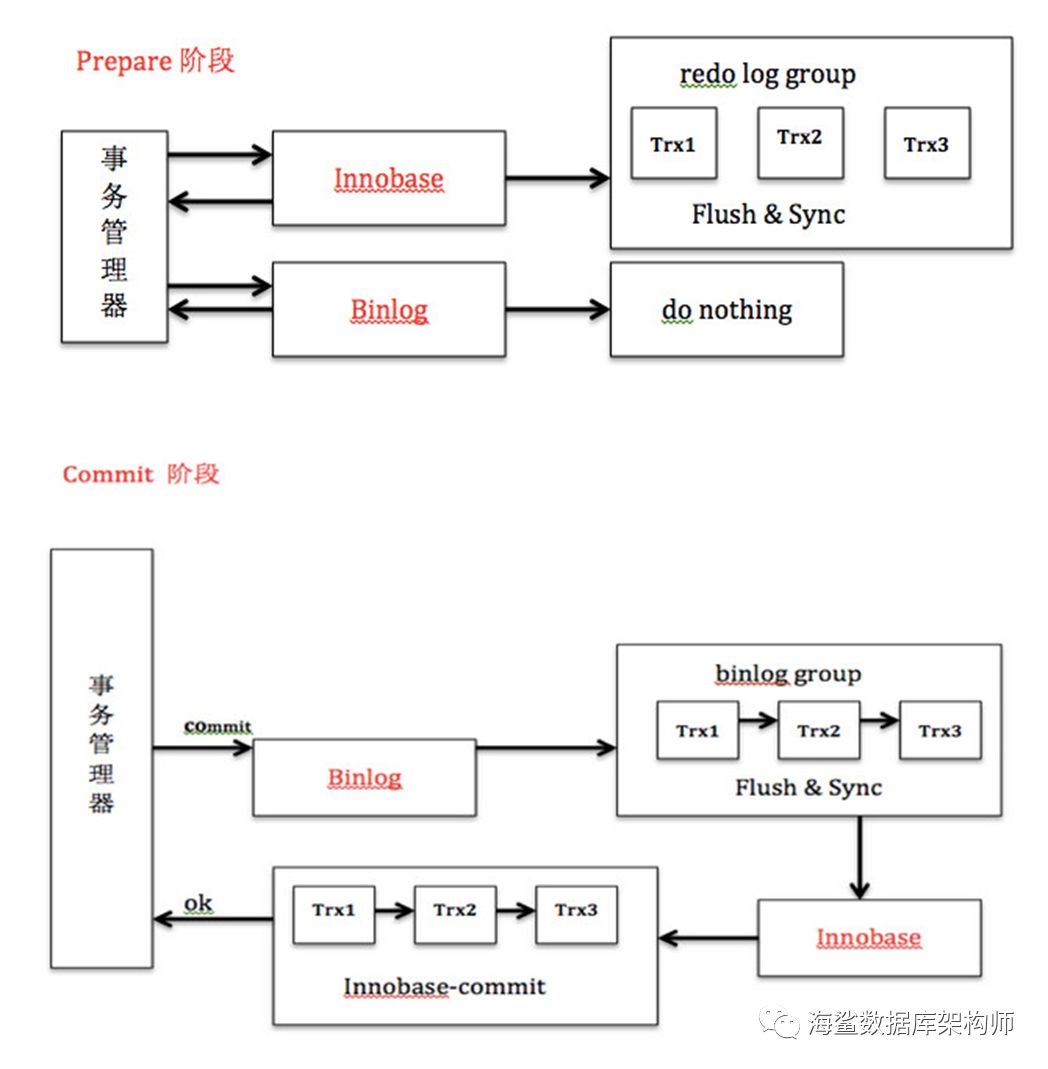
崩溃恢复机制
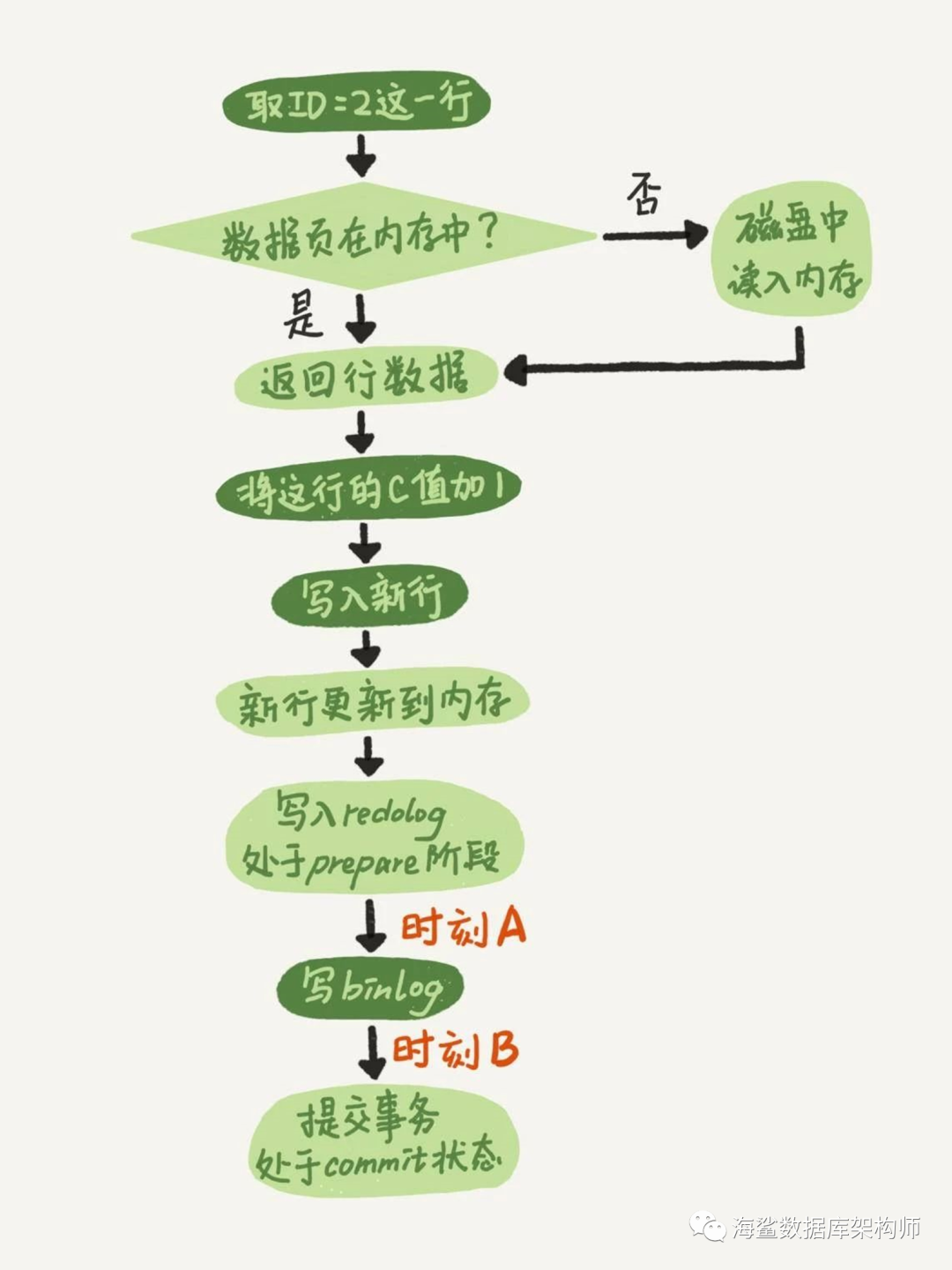
如果在图中时刻 A 的地方,也就是写入 redo log 处于 prepare 阶段之后、写 binlog 之前,发生了崩溃(crash),由于此时 binlog 还没写,redo log 也还没提交,所以崩溃恢复的时候,这个事务会回滚。这时候,binlog 还没写,所以也不会传到备库。到这里,大家都可以理解。
大家出现问题的地方,主要集中在时刻 B,也就是 binlog 写完,redo log 还没 commit 前发生 crash,那崩溃恢复的时候 MySQL 会怎么处理?
我们先来看一下崩溃恢复时的判断规则。
如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交;
如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整:
a. 如果是,则提交事务;
b. 否则,回滚事务。
这里,时刻 B 发生 crash 对应的就是 2(a) 的情况,崩溃恢复过程中事务会被提交。
一个事务的 binlog 是有完整格式的:
statement 格式的 binlog,最后会有 COMMIT;
row 格式的 binlog,最后会有一个 XID event。
另外,在 MySQL 5.6.2 版本以后,还引入了 binlog-checksum 参数,用来验证 binlog 内容的正确性。对于 binlog 日志由于磁盘原因,可能会在日志中间出错的情况,MySQL 可以通过校验 checksum 的结果来发现。所以,MySQL 还是有办法验证事务 binlog 的完整性的。
redo log 和 binlog 是怎么关联起来的?
它们有一个共同的数据字段,叫 XID。崩溃恢复的时候,会按顺序扫描 redo log:
如果碰到既有 prepare、又有 commit 的 redo log,就直接提交;
如果碰到只有 parepare、而没有 commit 的 redo log,就拿着 XID 去 binlog 找对应的事务。
为什么 prepare 阶段的 redo log 加上完整 binlog,重启就能恢复?
在时刻 B,也就是 binlog 写完以后 MySQL 发生崩溃,这时候 binlog 已经写入了,之后就会被从库使用。所以,在主库上也要提交这个事务。采用这个策略,主库和备库的数据就保证了一致性。
主从复制半同步插件
rpl_semi_sync_master_wait_point
MySQL5.7之前的版本半同步复制rpl_semi_sync_master_wait_point默认值为after_commit
MySQL5.7 半同步复制 rpl_semi_sync_master_wait_point默认值为after_sync
看一下官方文档怎么说
AFTER_SYNC (the default): The masterwrites each transaction to its binary log and the slave, and syncs the binarylog to disk. The master waits for slave acknowledgment of transaction receiptafter the sync. Upon receiving acknowledgment, the master commits thetransaction to the storage engine and returns a result to the client, whichthen can proceed.
AFTER_COMMIT : The master writes eachtransaction to its binary log and the slave, syncs the binary log, and commitsthe transaction to the storage engine. The master waits for slaveacknowledgment of transaction receipt after the commit. Upon receivingacknowledgment, the master returns a result to the client, which then canproceed.
For older versions of MySQL,semisynchronous master behavior is equivalent to a setting of AFTER_COMMIT.
The replication characteristics of thesesettings differ as follows:
With AFTER_SYNC, all clients see thecommitted transaction at the same time: After it has been acknowledged by theslave and committed to the storage engine on the master. Thus, all clients seethe same data on the master.
In the event of master failure, alltransactions committed on the master have been replicated to the slave (savedto its relay log). A crash of the master and failover to the slave is losslessbecause the slave is up to date.
With AFTER_COMMIT, the client issuingthe transaction gets a return status only after the server commits to thestorage engine and receives slave acknowledgment. After the commit and beforeslave acknowledgment, other clients can see the committed transaction beforethe committing client.
AFTER_SYNC (默认值):主服务器将每个事务写入其二进制日志和从服务器,并将二进制日志同步到磁盘。 在同步之后,主服务器等待从服务器确认接收的事务。 在接收到确认之后,主服务器将事务提交给存储引擎,并将结果返回给客户机,然后客户机就可以继续执行。
AFTER_COMMIT :主服务器将每个事务写入其二进制日志,从服务器同步二进制日志,并将事务提交到存储引擎。 在提交之后,主服务器等待从服务器对事务接收的确认。 在接收到确认之后,主程序将结果返回给客户端,然后客户端可以继续进行操作。
对于旧版本的MySQL,半同步主行为相当于设置AFTER_COMMIT。
这些设置的复制特征不同如下:
使用 AFTER_SYNC,所有客户端同时看到提交的事务:在从服务器确认并提交到主服务器上的存储引擎之后。 因此,所有客户端在主服务器上看到相同的数据。
在主服务器失败的情况下,在主服务器上提交的所有事务都被复制到从服务器(保存到它的中继日志中)。 主服务器的崩溃和到从服务器的故障转移是无损的,因为从服务器是最新的。
使用 AFTER_COMMIT,发出事务的客户端只有在服务器提交到存储引擎并收到从服务器的确认之后才会获得返回状态。 在提交之后和从确认之前,其他客户端可以在提交客户端之前看到提交的事务。
依旧如此所有官方文档都是说个大概,并没有说的很仔细.同样BINLOG 也有写OS CACHE 和FSYNC 同步到文件的问题.
官网关于两个参数都是 这句writes eachtransaction to its binary log and the slave, syncs the binary log
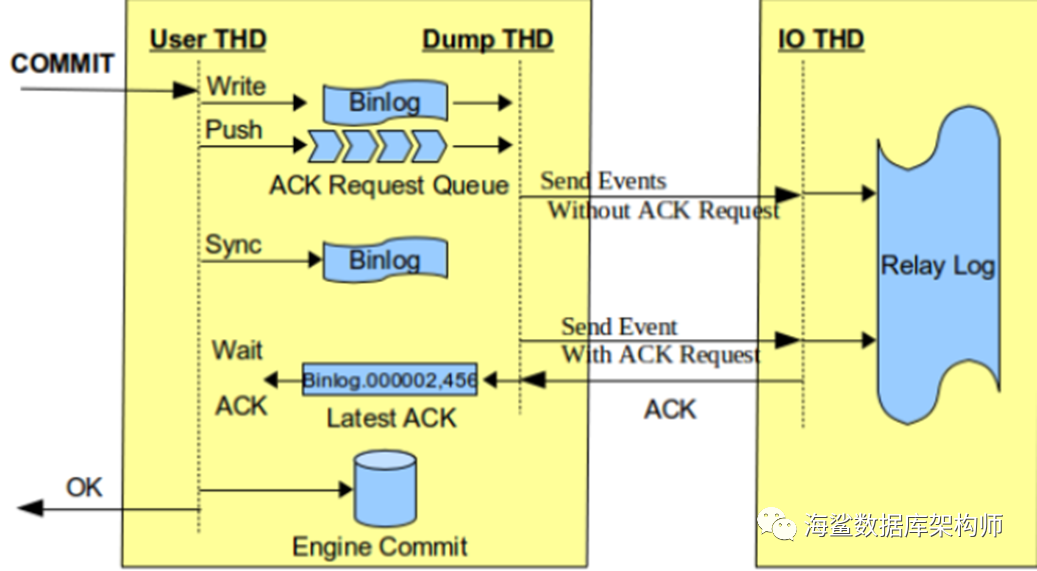
下图说明的是有ACK要求的是在SYNC 后才DUMP到从库, 如果没有ACK要求的话,是在WRITE OS_CAHCE 时DUMP到从库.
那就是说非增强半同步时候时WREITE OS_CACHE发, 增强半同步时是SYNC后发给从库.
AFTER_COMMIT 是增强半同步时发给从库后立马让REDO 标记COMMIT; 收到ACK后才告诉客户端OK
AFTER_SYNC是增强半同步时发给从库后等待从库ACK然后让REDO 标记COMMIT; 然后通知客户端OK
这个ACK 一前一后,唯一区别的是其它会话能否看得到事务提交的数据,时间差.
风险点在哪?
主要是 REDO LOG ; BIN LOG; 从库; 三者的关系,应该说三阶段提交;
外加上 OS_CACHE层,以及为了性能的组提交
下面是参数简化列表
REDO LOG | BIN LOG | Flush_meothod | 主从模式 | 组提交 | OS_CACHE 同步 |
log_at_trx_commit=0 | SYNC_BINLOG=0 | FSYNC | 异步 | binlog_group_commit_synccount | |
log_at_trx_commit=1 | SYNC_BINLOG=1 | O_DSYNC | 半同步 | binlog_group_commit_sync_delay | WRITE() |
log_at_trx_commit=2 | SYNC_BINLOG=N | O_DIRECT | 增强半同步 | FSYNC() |
风险点基本是在日志和数据都在内存缓存中,此时此刻断电那么就造成系统损坏,数据丢失,从库比主库少了数据,从库比主库多了数据.
在内存时断电:
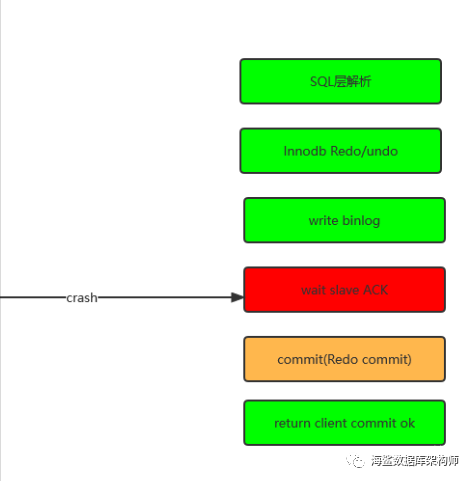
复杂的三段提交
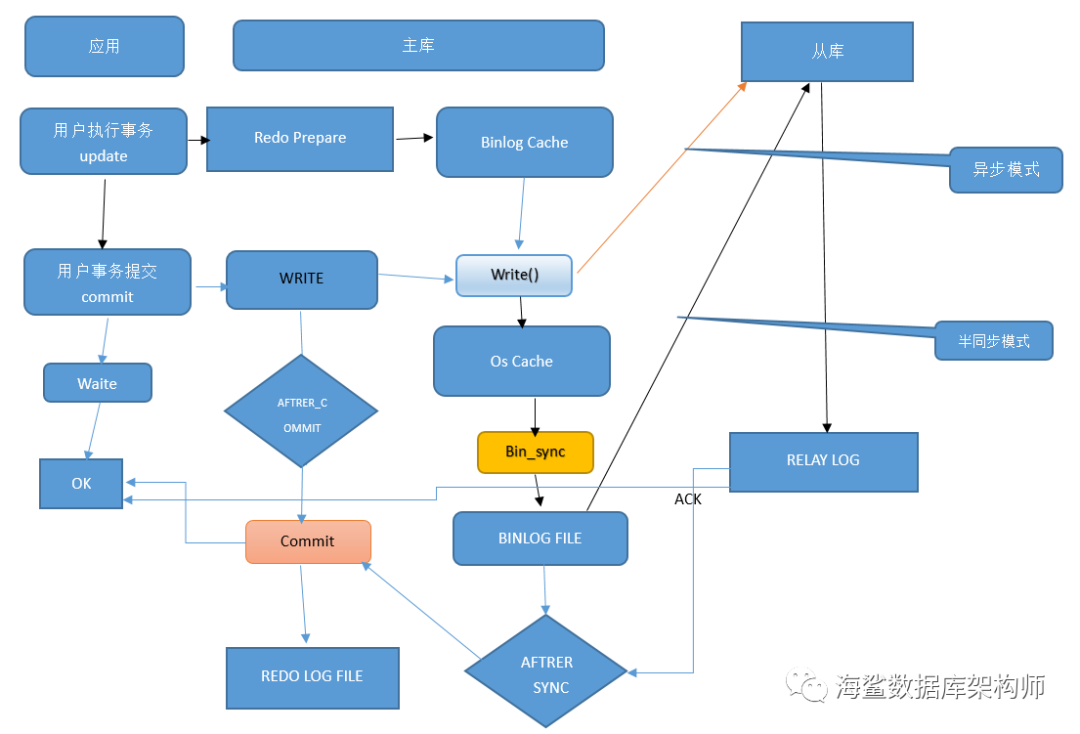
根据恢复模式, 只要REDO LOG有标记COMMIT; 或者对应的BINLOG是完整的.二者只要一种符合就可以恢复该事务.
风险点1:
设置了异步模式, BINLOG在OS_CACHE时 发给了从库,断电.从库多了数据.
风险点2:
半同步after_commit, 主库比从库多了一笔;
风险点3 ....................
算了 还是给出安全的参数配置
innodb_flush_log_at_trx_commit=1;
SYNC_BINLOG=1
主从模式 增强半同步 after_sync
组提交为0
innodb_Flush_meothod=O_DIRECT 数据文件和系统文件直接读写;
