





潭主这两年跟踪了一些新技术,图数据库就是其中之一。
学习期间产出过两篇文章,一篇提及了TigerGraph,另一篇则是关于Neo4j,对当下原生图和分布式均有涉及。
目前,各大云厂商都已经在图数据库市场上做了布局,蚂蚁发布了TuGraph,腾讯则是TGDB。
数据库这个市场越来越诡异,也越来越混乱。
不过,今天潭主打算分享另一个“新”产品,NebulaGraph。
为什么要聊NebulaGraph
前些天,潭主听腾讯分享了他们的TGDB,感觉又是一通吹。
这边TGDB话音未落,那边微信里就有人跑来跟潭主调研Nebula。
知道公司有团队在用这个产品,所以潭主自然不能错过这次和NebulaGraph的切磋。
Nebula的中文意思是星云,不由想起了《圣斗士星矢》中瞬的绝技——星云锁链(Nebula Chain)。
接下来,让我们一起燃烧小宇宙吧。
什么是NebualGraph
NebulaGraph是一款开源、分布式、易扩展的原生图数据库,官方说其能够承载千亿个点和万亿条边的超大规模图,并且提供毫秒级查询。
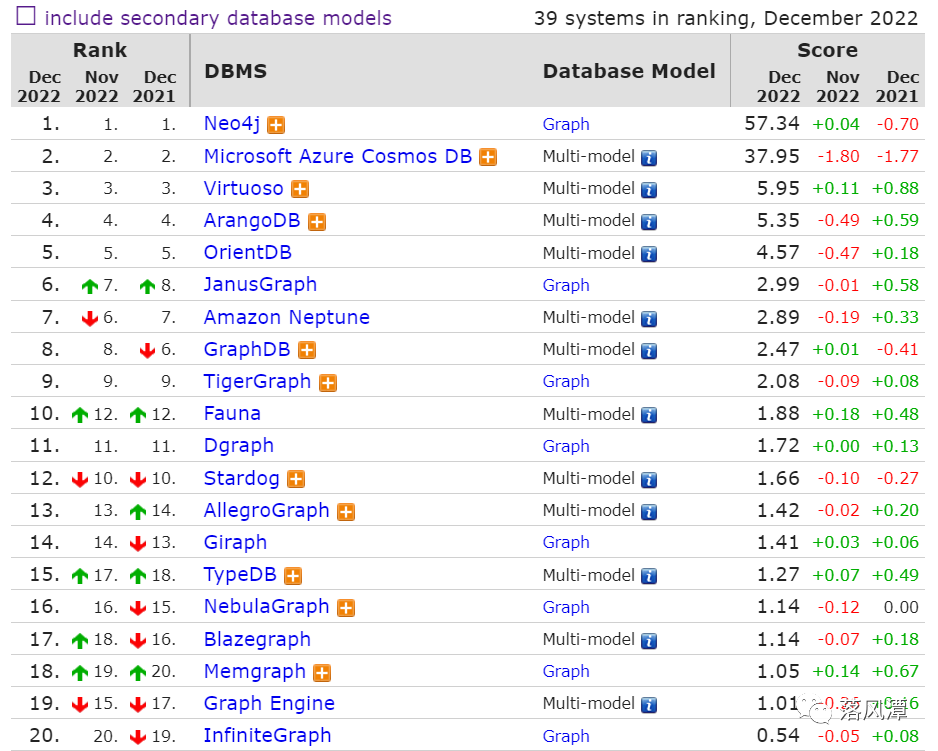
下图是潭主查的最新的图数据库的排名,从国产和专业Graph的角度看,排名还可以。
之前,潭主用最简单的Neo4j Desktop版本帮同事处理过一些关于医疗知识图谱的事,通过实战对Neo4j的Cepher语法有了一定的经验,相比传统SQL还是有些不太一样。
这次学习NebulaGraph,除了产品架构,最大的收获就是增加了对GQL语法的了解。
NebulaGraph的数据模型
通俗讲,图数据库可以看成是由若干个顶点和边组成的图形,用来表示事物之间复杂的关系。
虽说图数据库都是基于图论的实现,产品在概念上也大同小异,但在技术实现细节上还是有很大的差异。
这是潭主看过Nebula之后的第一感觉,至少和Neo4j在使用体验上差别很大。
NebulaGraph用到的6种数据模型:
点(Vertex):用来保存实体对象,用VID(Vertex ID)标识。 标签(Tag):可以理解成关于点的表结构(Table Schema),由一组事先预定义的属性构成。 边(Edge):边用来连接点,表示两个点之间的关系或行为。 边类型(Edge Type):相对于Vertex的Tag,Edge Type可以理解成边的表模式,也由一组事先定义的属性构成。 属性(Property):以Key-Value形式表示的信息。
VID在同一图空间中具有唯一性(类似唯一索引),VID是int64或者fixed_string(N)的类型,需要在创建图空间时进行设定。
点的VID必须由用户自行指定,VID通常被LSM-Tree索引并缓存在内存中,提升效率的同时,也会面临Compaction的问题。
一个Vertex可以有多个Tag。
两个点之间可以有多条边,边是有方向的,边的四元组的特性<起点VID,Edge Type,Edge Rank,终点VID>可用于唯一标识一条边,
一条边只有一个Type,一条边也只有一个Int64类型、默认值为“0”的Rank。
对于基础数据模型,Nebula的很多操作更贴近MySQL,而不是图,这个印象来自于nGQL。
nGQL(NebulaGraph Query Language)是NebulaGraph使用的声明式图查询语言,属于类SQL查询语言,也兼容部分openCypher语法。
重新理解图的路径
图论中还有一个非常重要的概念叫路径,路径是指一个有限或无限的边序列,这些边连接着一系列的点。
之前学习图数据库,因为不涉及应用开发,所以对于路径的概念不够清晰,这次在Nebula的学习过程中,对图的路径有了新的认知。
Nebula图路径类型分为三类:
Walk路径:由有限或无限的边序列构成,遍历时点和边可以重复。
Trail路径:由有限的边序列构成。遍历时只有点可以重复,边不可以重复。
Path路径:由有限的边序列构成,遍历时点和边都不可以重复。
在Trail类型中,还有Cycle和Circuit两种特殊的路径类型:
Cycle :是封闭的 trail 类型的路径,遍历时边不可以重复,起点和终点重复,并且没有其他点重复。
Circuit:也是封闭的 trail 类型的路径,遍历时边不可以重复,除起点和终点重复外,可能存在其他点重复。
不同的路径支持不同的nGQL语句。
GO语句采用的是walk类型路径,而MATCH、FIND PATH和GET SUBGRAPH语句采用的是trail类型路径。
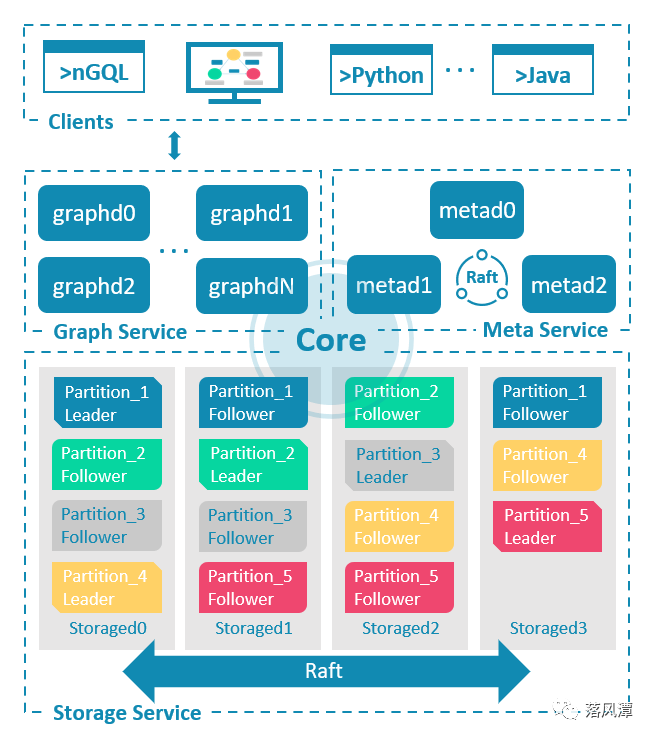
NebulaGraph的架构
NebulaGraph由三种服务构成:Meta、Graph和Storage,属于存算分离的架构,跟TiDB的系统架构很像。
Meta服务
元数据的存储和管理,类似TiDB中的Placement Driver,对应nebula-metad进程,基于Raft协议组成集群,用于执行Schema操作、存储和管理数据信息分片信息、用户权限等集群管理工作。
Graph服务:
计算引擎,对应nebula-graphd进程,负责语法语义的解析和执行,无状态、可扩展。对应TiDB中的TiDB模块。
Storage服务
存储引擎,对应nebula-storaged进程,对应TiDB中的TiKV,Storage服务自身也分三层。
存储接口层( Interface):定义了一系列和图相关的 API,API请求在这一层被翻译成一组针对分片的K-V操作。
存储共识层(Consensus):通过Raft协议确保数据的一致性和可靠性,
存储引擎层(Engine):使用的RockDB存储K-V。
NebulaGraph的生态体系
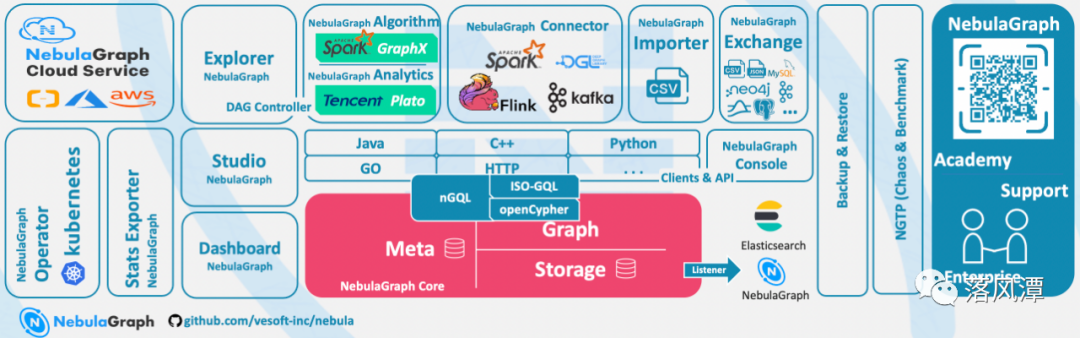
NebulaGraph有一众生态工具,如Studio、Dashboard、Explorer、Console、Importer和Exchange,用于实现模式设计、运维监控、数据探查、控制台操作和数据交换 等功能。
此外,NebulaGraph也能与Spark、Flink和HBase等产品进行集成。
潭主挑了几个组件试用了一下,对产品有了一个简单直观的感受。
试用NebulaGraph的几点感受
潭主搭了一个Nebula的测试环境,体验了7001的Studio,7002的Explorer和7003的Dashboard。
分享一下测试后的几点感受:
产品组件过于零散,很多工具需要单独安装和部署,略显费劲,不过对了解产品有一定的帮助。
Nebula跟Neo4j在使用上有一定的差别,之前做OMAHA医疗知识图谱的经验在Nebula上大多不适用,只能边学边适应。
Nebula的Import工具,虽然Web界面有一定的便捷性,但感觉不如Neo4j的load命令行来得简单。
过程中也踩了几个坑,不过售前技术支持的同学比较给力,帮潭主答疑解惑,总体而言,本次Nebula的学习实践还是挺有收获的。
在Nebula上还有一些后续测试,之后也还有其他图数据库的PoC,等有了心得再做分享。
- END -
感谢阅读。如果觉得写得还不错,就请点个赞或“在看”吧。
公众号所有文章仅代表个人观点,与供职单位无关。

