




一、引言
环境:64位Win 10中文版 + 64位Python 3.7.6

本书配套的电子版图书中的编码和文本处理知识也可以作为理工科教师和科研人员处理文本数据的参考资料之一,毕竟专门开辟章节介绍国家标准《通用规范汉字表》汉字处理的程序设计图书并不多见。



三、简单读取
假设有一个文本文件“一二三四五.txt”,内容如下:
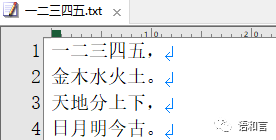

上述程序结果如下:

现在出于某种需要,我们想读取第二遍,于是改成如下的代码:

上述程序结果如下:
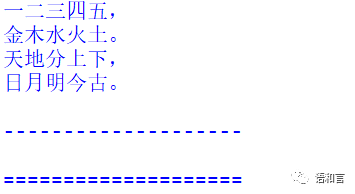
我们发现,第二次读取到的内容为空字符串。
四、重复读取
为了能够重新读取到内容,我们需要在上面第5行程序代码
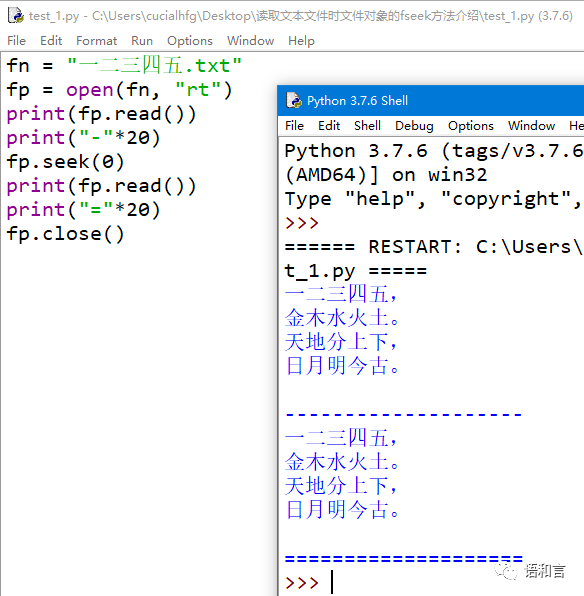
我们还可以用文件对象的seek方法定位到任何一个汉字,然后从该汉字开始读取文件内容,例如:

上述代码在第一次读取文件内容之后,把读写位置定位到汉字“水”所在的文件,然后第二次就从“水”开始读取剩余的文件内容。程序的运行结果如下:

“水”在文件中的读写位置跟18有什么关系呢?为什么 fp.seek(18) 就能定位到“水”的位置?为了理解这种关系,我们需要介绍一下文件对象的seek方法。
五、文件对象的fseek方法介绍
首先,我们对准文件“一二三四五.txt”图标点鼠标右键,选属性,发现这个文件的内容占了56个字节,如下图所示:
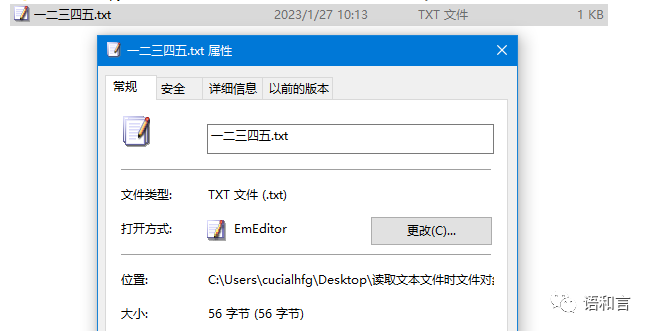
由于文件是用ANSI编码的,每个汉字(因为这些汉字都是常用汉字)都是用两个字节保存的,又因为是在Windows系统中,每个换行符被保存为回车换行两个字符,所以文件“一二三四五.txt”连同换行符在内一共28个字符,每个字符都用两个字节存储,所以整个文件的内容就用了56个字节来存储。我们用UltraEdit软件的十六进制编辑功能,可以很方便地看到这56个字节对应的汉字和回车换行符,如下图所示:

我们把上述56个字节从0开始编号,显然,最后一个字节的编号是55。汉字串“一二三四五,”对应的12个字节编号是0~11,后面的回车换行符对应的两个字节编号是12~13。金和木这两个汉字对应的四个字节编号是14~17,水这个汉字对应的两个字节编号是18~19。
如果我们用Python打开这个文件,文件对象的当前读取位置(我们可以形象地称之为文件指针,它指向下一个要读取的字节的位置)就在第0号字节这里,用fp.read()读取全部内容之后,文件指针指向的位置是56,显然,这个位置已经是文件的结束位置了。这个时候再用fp.read()读取全部内容,就读取不到任何内容。
如果想二次读取,就需要把文件指针移动到文件的第0个字节处,这就需要用到fp对象的seek方法。seek方法有两个参数:
seek(offset, whence=0)
第一个参数是相对于基准位置的偏移量,第二个参数是基准位置:
whence=0 表示基准位置为文件头(第0个字节),0是第二个参数的默认值;
whence=1 表示基准位置为当前的文件指针的当前位置;
whence=2 表示基准位置为文件尾(最后一个字节后面的位置)。
注意:用文件对象的seek方法是以字节为单位定位的。
前面重复读取那一节的最后一个程序,执行语句 fp.seek(18) 之后,文件指针指向了第18个字节,也就是汉字水的第一个字节。下一步 用 fp.read() 读取全部内容,就是读取从当前文件指针位置到文件末尾的所有内容。
我们也可以从文件当前位置读取指定个数的字符,看下面的例子:

这段代码会读取出“水火”这两个汉字输出到屏幕上。
注意:读取文本文件时,虽然文件对象的seek方法是以字节为单位定位的,但文件对象的read()方法读取时却是以字符为单位的。
这种不一致有可能会造成一些不方便,例如下面的代码:

上面的代码在运行时会报错:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xfe in position 2: illegal multibyte sequence
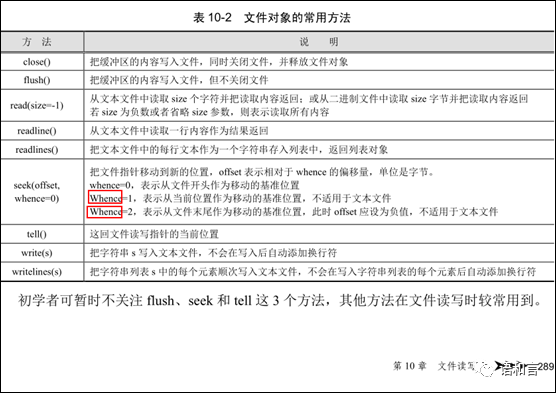
这个表的倒数第4个表格行(seek那一行)第2列,后两个文本行whence的大小写有误,应该全是小写字母,不能大写第一个字母。
八、图书目录
图书《Python程序设计(基于计算思维和新文科建设)》目录如下(手机端可以用手指上下滑动下面灰色区域的文字来查看全部目录,电脑端可以用鼠标滚动滚轮或拖动下面文本框右边的滚动条来浏览全部目录):
参考文献
