




本文介绍了中国传媒大学本科课程《自然语言处理技术》的一次作业,作者李蔚。任务要求写一个基于web的题库建设系统,该系统允许从浏览器端上传题目并存入数据库,并且提供自动组卷的功能。
本次任务是一个更大任务的组成部分,更大的任务是做一个基于题库的重复题目判别系统。在题库建设中,不同的人录入的题目可能有重复或高度相似,这样的重复或高度相似题目在题库中显然需要删重。当题库容量非常大的时候,自动判断题目是否有重复就变得非常有必要。判断重复题目,其实是NLP领域的文本相似性判定的一个应用。
1
成果展示
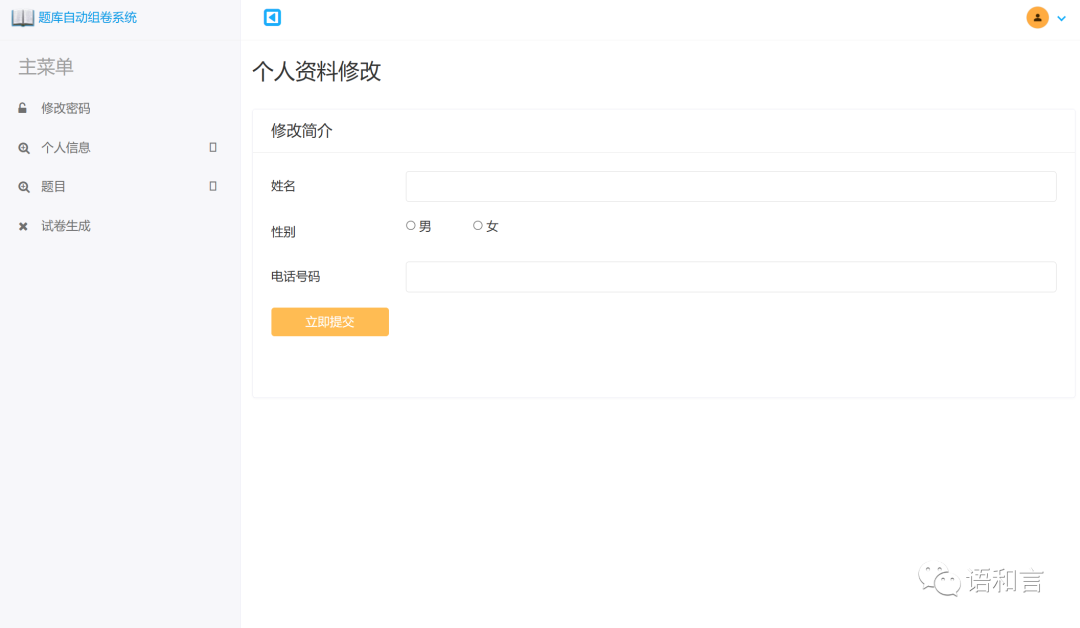
本题库系统具体有登录、个人资料修改、上传试题、自动组卷等功能。个人信息可以查看和进行修改,题目上传分为选择、填空、简答、判断以及名词解释,并且可以在组卷功能中设置生成试卷中各个题型的数量。
登录页面
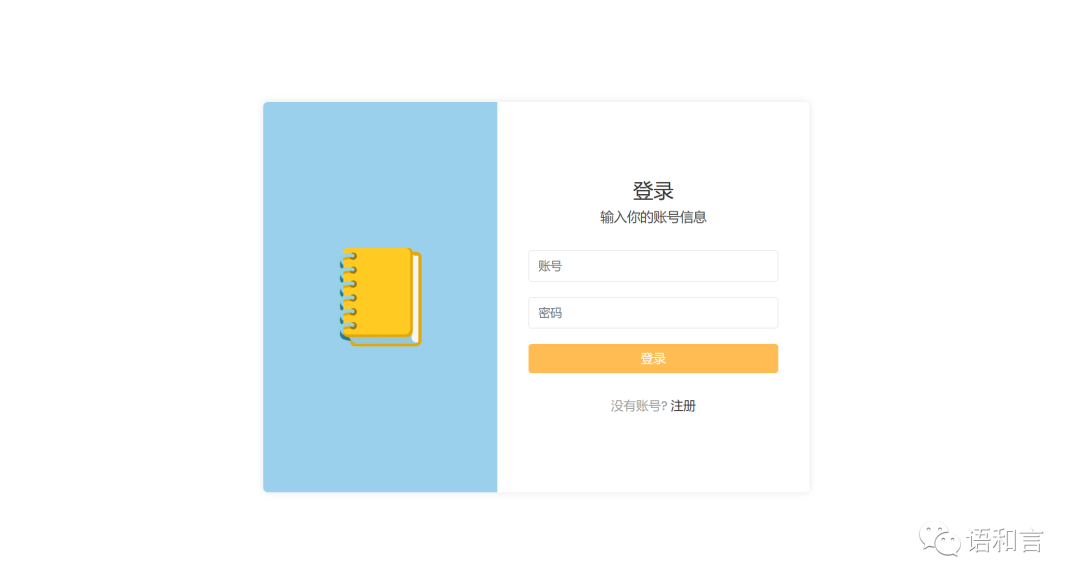
修改密码
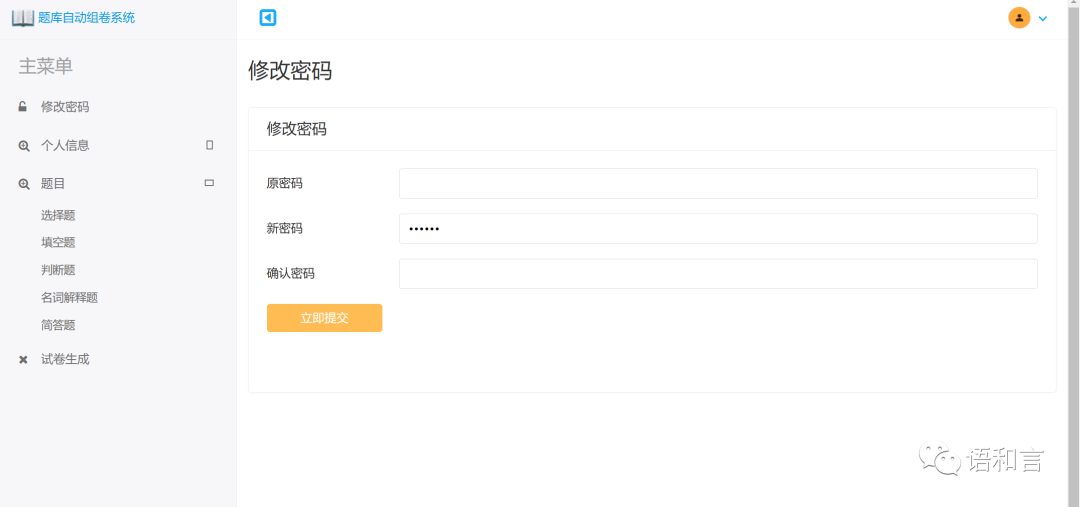
录入题集
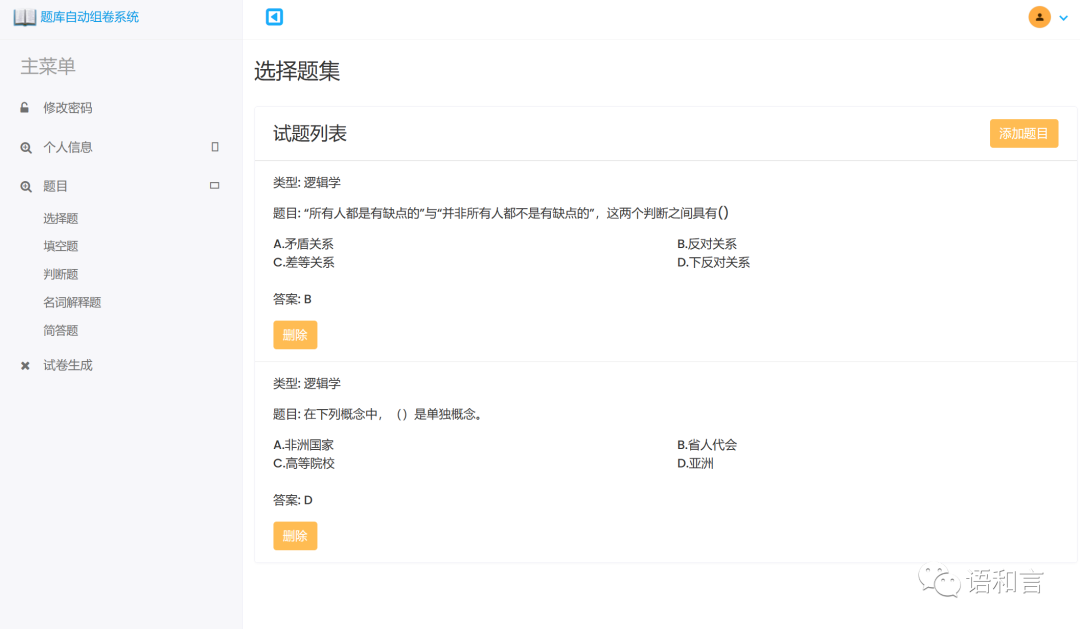
生成试卷
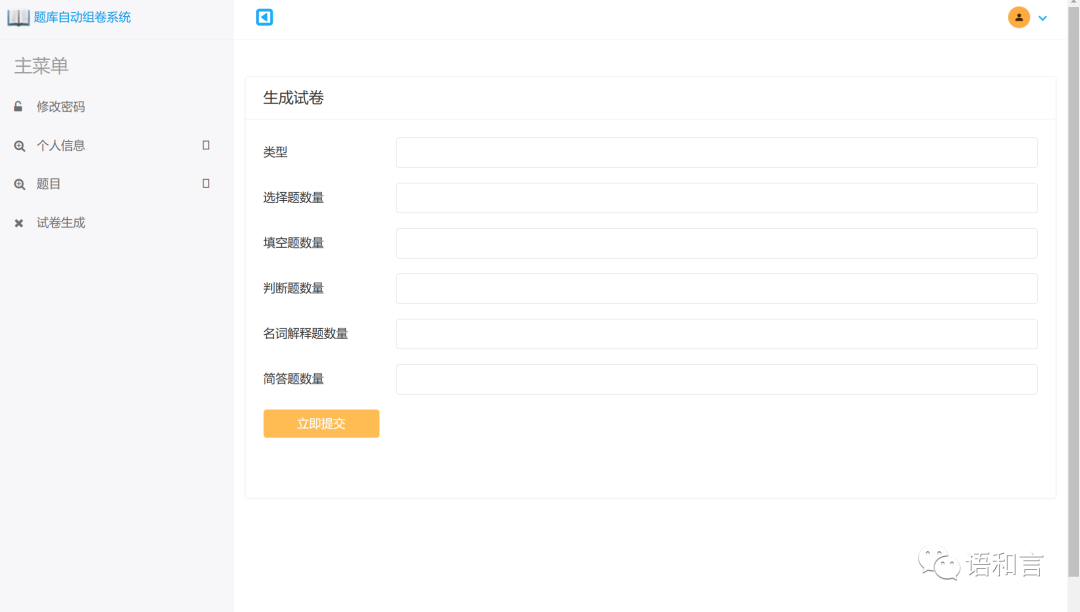
资料修改
2
使用说明
1. 安装好python,并且设置环境变量
2. 安装django和python-docx拓展
安装django,在cmd里输入
pip install -i https://pypi.douban.com/simple django
将django设置环境变量
详细可参考
https://blog.csdn.net/qq_44816302/article/details/120749662
安装python-docx拓展,在cmd里输入:pip install python-docx
详细可参考胡老师介绍的快速安装拓展库的方法:
以上准备完成后,就可以成功运行我们的题库系统了
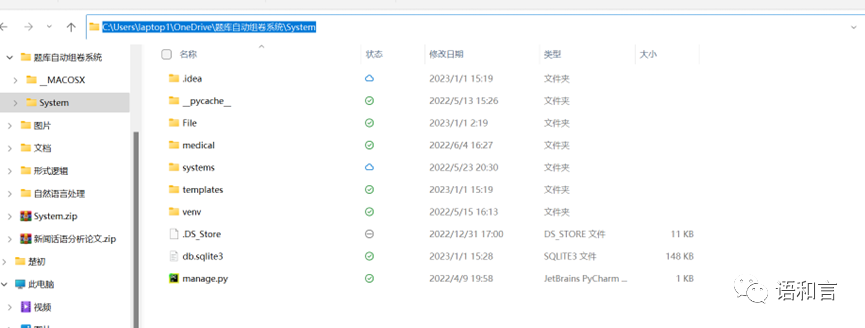
在命令指示符中输入python manage.py runserver
成功运行后会有得到浏览器地址http://127.0.0.1:8000/
在浏览器中输入即可访问
3
框架设计
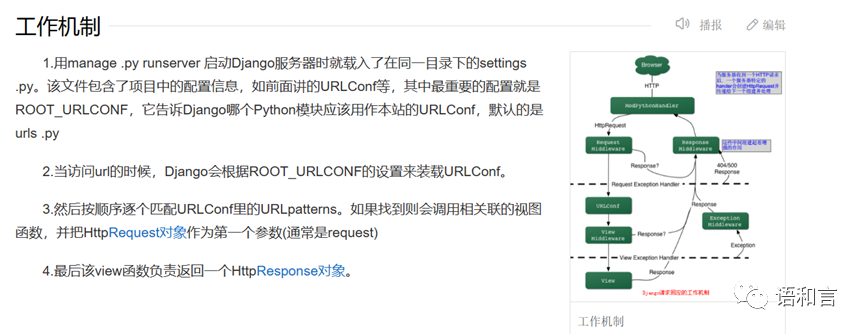
web框架用的是django,它的工作机制我们用来自百度百科页面的一个截图来说明:
总体框架如图,参考了网络上的一个仓库系统:https://b23.tv/n6gfXK5,感谢原作者“就叫小王八儿”
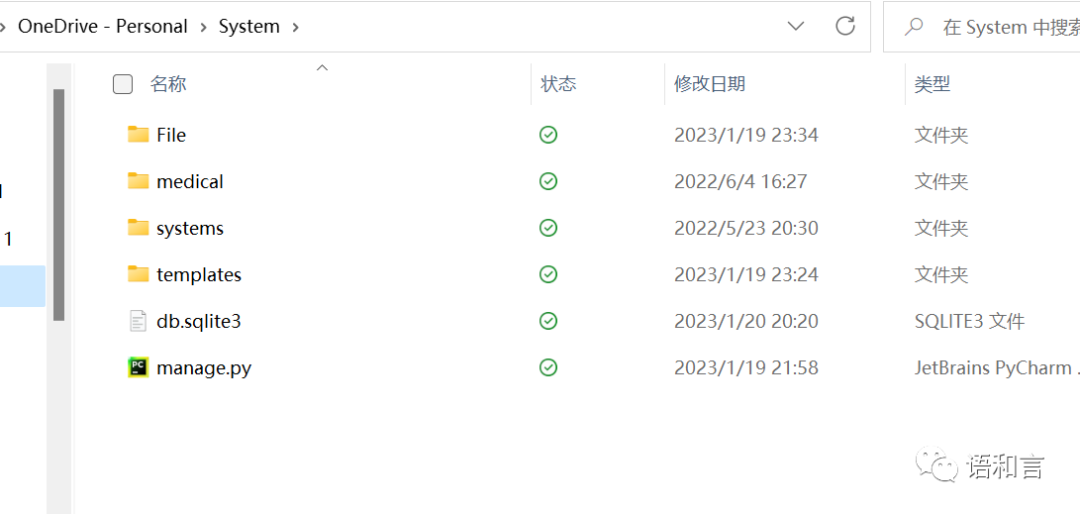
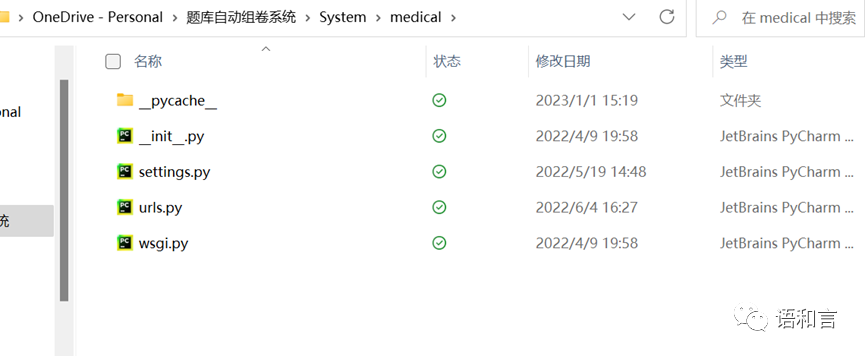
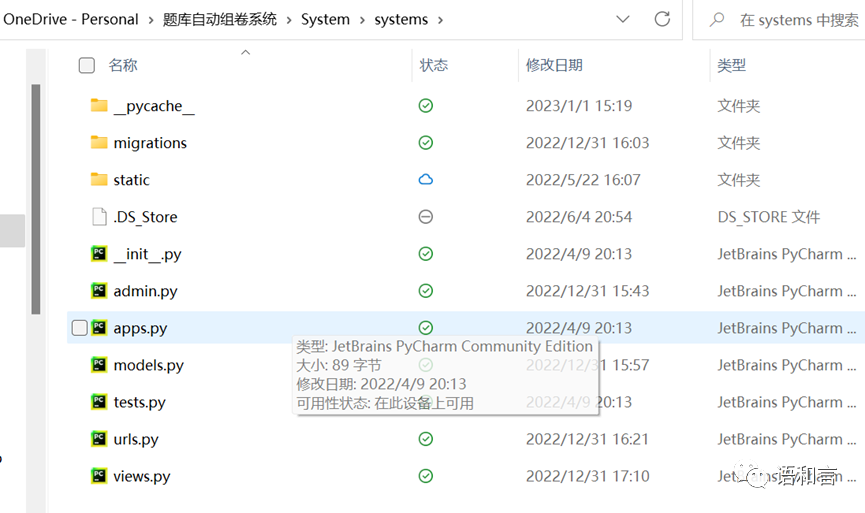
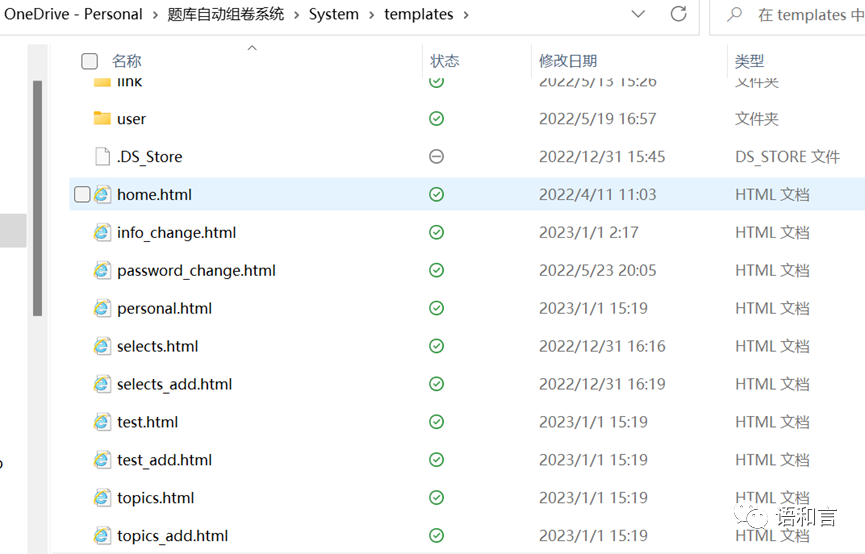
manage.py:django项目的主管或入口文件,django项目启动时也是通过该入口启动
setting.py:全项目的配置文件,配置的参数作用范围是全局的(改动时需参考文献)
urls.py:所有地址/url/http请求和视图逻辑层具体函数的关联,定义某个url应该打开的是哪个文件
migrations文件夹:存放数据同步历史的地方、
admin.py:django自带后台数据库管理页面的控制
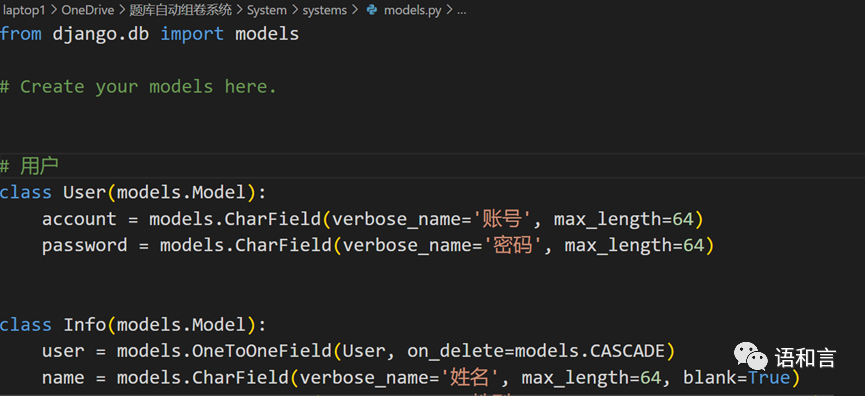
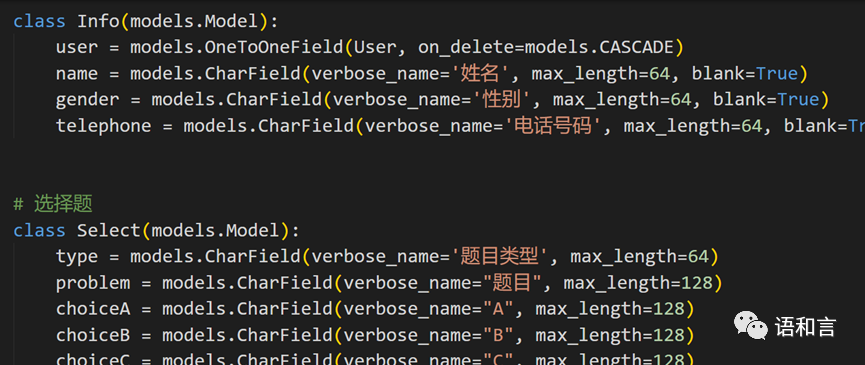
models.py:设置数据库表和字段的文件
test.py:django用来进行单元测试的文件
view.py:视图逻辑层 - 用来接收浏览器数据并清洗,整理后传递给业务层(若项目内没有新建业务层,则该文件默认用来接收前端数据并写后端代码)
业务层:写后端的具体代码
apps:当django项目有很多个app时,在此设置app的参数,控制各app是否启用
一个完整网页= 后台数据+ html模板+ 静态资源(可用/可不用)
templates为html模板文件夹,static为静态资源文件夹
4
关键代码
数据连接到数据库
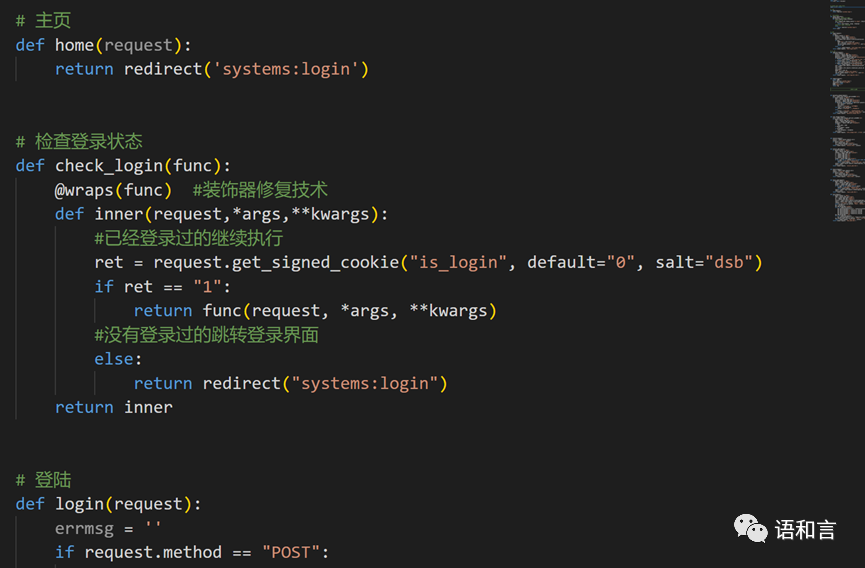
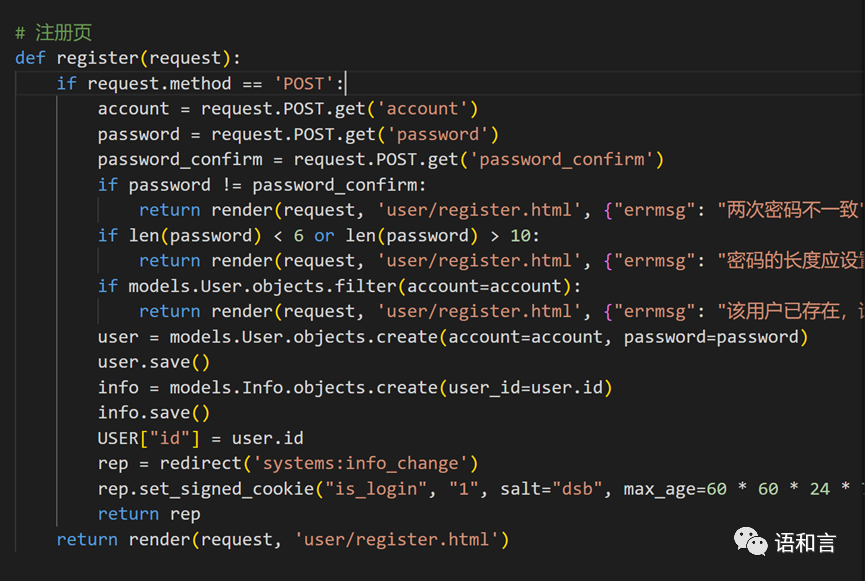
主页配置
自动组卷
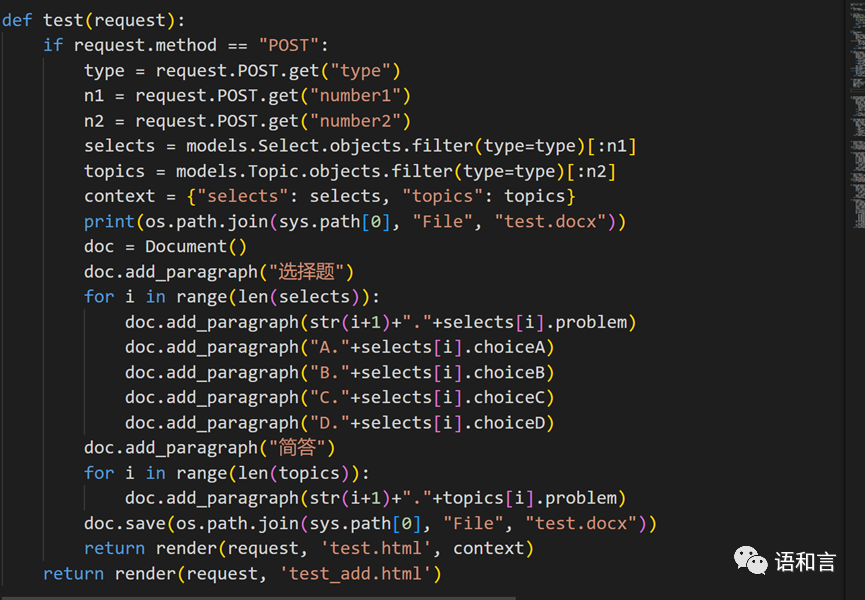
5
数据演示
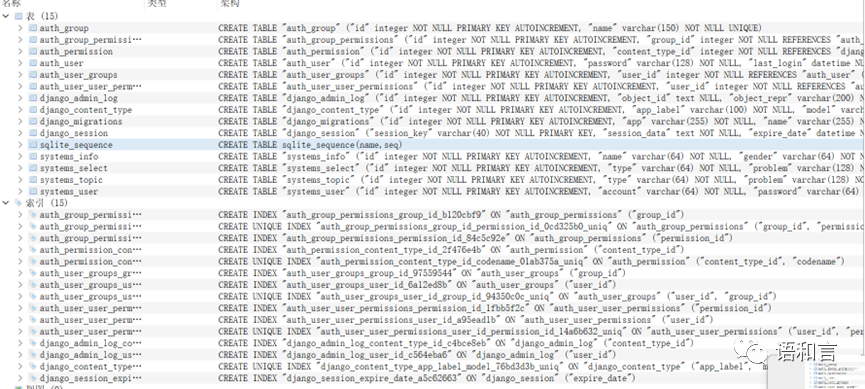
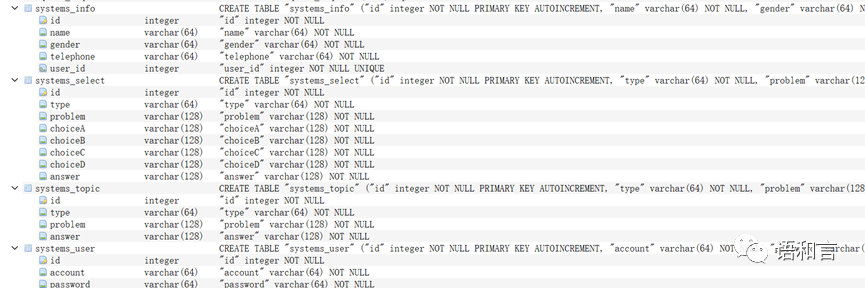
本次课程设计完成了用Python 语言编程实现了一个初步的题库系统,web框架用的是django,主要实现添加试题、用户注册、自动组卷等功能。未来可进一步优化扩充系统功能,为重复题目判别系统的研制提供重要的题库资源,我们用视频展示一下最终效果。
