




但是如果想部署一个自己的文件分析系统,并且暂时只有ChatGPT3.5,就可以通过本节内容来实现。
这一节,我们会介绍如何开发一个ChatGPT的应用,大致功能是左边上传本地文件,再输入关于这个文件内容的相关问题,使用ChatGPT进行分析之后,右边给出用户答案。
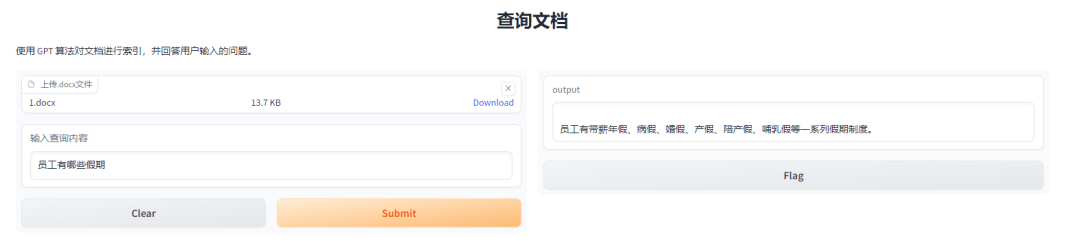
1 先看效果
2 安装依赖
pip3 install gradio
3 设置环境变量
把OpenAI 的 API key 加入到环境变量:
Windows环境
setx OPENAI_API_KEY xxx
linux环境
export OPENAI_API_KEY xxx
4 编写代码
实际自己不用编辑多少代码,首先去https://llamahub.ai/ 找 docx 的数据源,如果有其他类似数据源,方法也差不多
目前支持的数据源有:图片、Office 三件套、PDF、CSV、ES、主流数据库、markdown、json等。
使用docx 数据源的方法地址如下:
https://llamahub.ai/l/file-docx
代码是:
from pathlib import Pathfrom llama_index import download_loaderDocxReader = download_loader("DocxReader")loader = DocxReader()documents = loader.load_data(file=Path('./homework.docx'))
再让ChatGPT帮我们完善代码,实现前端页面:
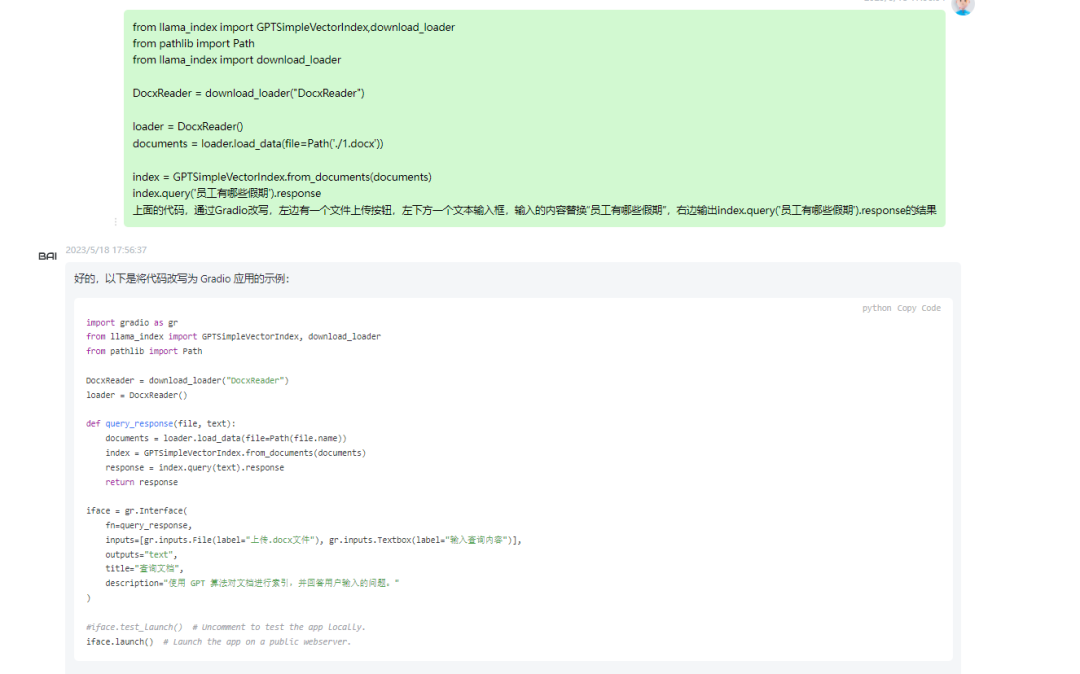
最终生成的代码如下:
(我只增加了server_name、端口、用户名、密码)
import gradio as grfrom llama_index import GPTSimpleVectorIndex, download_loaderfrom pathlib import PathDocxReader = download_loader("DocxReader")loader = DocxReader()def query_response(file, text):documents = loader.load_data(file=Path(file.name))index = GPTSimpleVectorIndex.from_documents(documents)response = index.query(text).responsereturn responseiface = gr.Interface(fn=query_response,inputs=[gr.inputs.File(label="上传.docx文件"), gr.inputs.Textbox(label="输入查询内容")],outputs="text",title="查询文档",description="使用 GPT 算法对文档进行索引,并回答用户输入的问题。")#iface.test_launch() # Uncomment to test the app locally.iface.launch(server_name='0.0.0.0', server_port=6688, auth=("admin", "Udiagc81GC")) # Launch the app on a public webserver.
5 使用
运行上面代码之后,登录IP:6688
会进入到如下页面:

上传一个docx文件,docx文件内容如下(也是ChatGPT生成的):

输入:员工的福利有哪些?
输出如下:
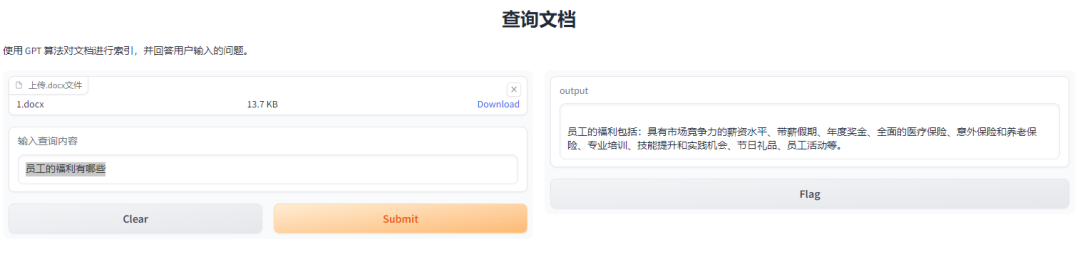
这样就完成了一个简单的文件分析系统。
最后介绍一下我们的AI星球:
星球目前已经有6个AI领域的高质量专栏,更多干货内容还在持续更新中。
犹豫的朋友们也可以先进星球看一下,看我们写的内容是否适合你,如果觉得不满意,星球支持三天内全额退款的,你也不会有任何损失。
再送一张28元的优惠券,券后60元年费(相当于每天0.16元),限量10张,先到先得。

如果想获得PDF文件分析的代码,可以关注公众号“AI应用航海”,回复“PDF分析”。
文章转载自MySQL数据库联盟,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
