




我们在使用ChatGPT等类似的AI产品时,可能会遇到比较冷门的内容或者定制化的内容,AI答不上来。
这时候,我们就可以通过llama_index给AI传一些特有的数据。这样,当AI回答我们的问题时,会结合AI知道的和我们上传的数据,从而返回我们想知道的答案。
use martin;create table student_info (id int auto_increment primary key,name varchar(10),address varchar(10),score int);insert into student_info(name,address,score)values('a','beijing',90),('b','shanghai',88),('c','beijing',86),('d','shanghai',92);
CREATE USER 'martin'@'localhost' IDENTIFIED BY 'uqatcdaT12';grant select on martin.student_info to 'martin'@'localhost';
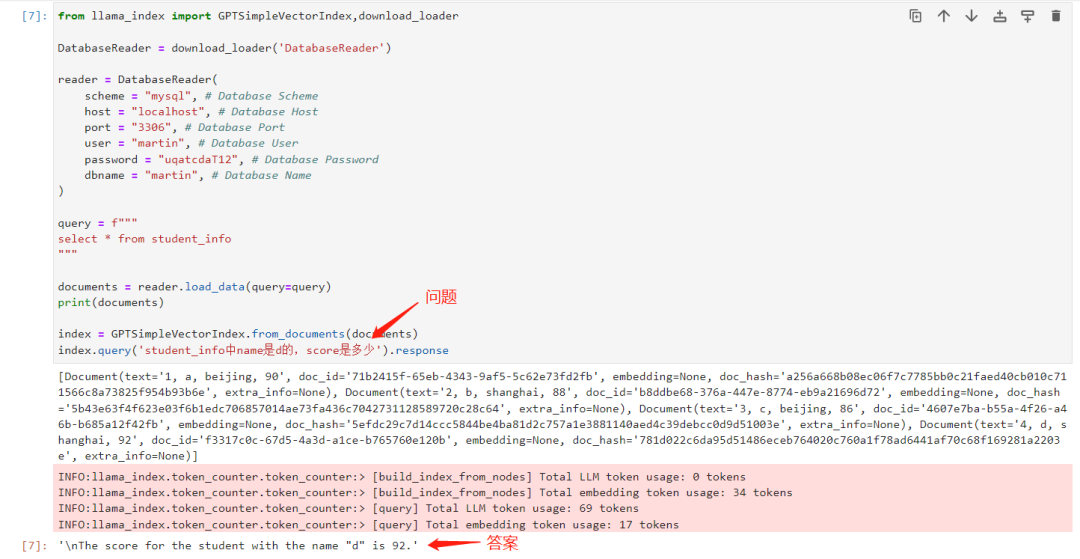
from llama_index import GPTSimpleVectorIndex,download_loaderDatabaseReader = download_loader('DatabaseReader')reader = DatabaseReader(scheme = "mysql", # Database Schemehost = "localhost", # Database Hostport = "3306", # Database Portuser = "martin", # Database Userpassword = "uqatcdaT12", # Database Passworddbname = "martin", # Database Name)query = f"""select * from student_info"""documents = reader.load_data(query=query)print(documents)index = GPTSimpleVectorIndex.from_documents(documents)index.query('student_info中name是d的,score是多少').response
mysql> select * from student_info;+----+------+----------+-------+| id | name | address | score |+----+------+----------+-------+| 1 | a | beijing | 90 || 2 | b | shanghai | 88 || 3 | c | beijing | 86 || 4 | d | shanghai | 92 |+----+------+----------+-------+4 rows in set (0.01 sec)
student_info中name是d的,score是多少?
The score for the student with the name "d" is 92.
我们成功获取到数据库里的特有信息。
 )。
)。定制化机器人客服,哪些地方不配送之类的数据写在数据库中,跟上面例子一样,结合AI使用; 论文解读,逻辑就可以使用llama_index分析本地文件,再使用ChatGPT的思维能力来总结论文内容; SQL审核或者评分,结合ChatGPT有的SQL评分能力,加上公司内部特有的SQL规范,比如违反某个规范多扣多少分。 如果你还能想到其他场景,欢迎在文章下方留言。


文章转载自MySQL数据库联盟,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
