





智能化转型背景下,如何以更小的算力成本承载更多的AI应用成为业界关注的重要课题。本文结合光大银行全栈云异构算力平台建设实践,在深入分析GPU池化技术演进路线及主流技术方案的基础上,总结梳理了全栈云异构算力建平台的技术特点与实际成效,并进一步展望了全栈云异构算力平台的未来发展方向。
数字经济背景下,人工智能技术正深度融入到各行各业的转型进程当中,为企业提升服务质效、实现高质量发展提供了强大助力。然而,人工智能在展现出巨大潜力的同时,其高昂的算力成本也让很多企业望而却步。以近期火爆出圈的Chat GPT为例,其实际参数规模可能已经达到千亿级别,预计要使用约3000个或者更多的A100 GPU芯片,若在云端训练,拥有1750亿个参数的GPT-3单次训练成本或将近500万美元。鉴于上述实际,有效降低算力成本已成为企业打造更高阶AI应用亟须解决的问题。
针对这一领域,光大银行基于GPU资源池化建设思路,创新研制了全栈云异构算力建设方案。该方案不仅可以支持本地GPU虚拟化,而且还能让AI应用无需修改代码即可透明地使用其他物理机上的远程GPU资源,从而实现数据中心级的GPU资源池化管理和弹性调度,并基于热迁移等功能显著增强了业务可靠性与管理便利性。

GPU池化技术演进路线与主流技术方案
1. GPU池化技术的演进路线
结合业界探索与优化实践,从GPU虚拟化演进到GPU资源池化主要经历了四个阶段:一是简单虚拟化阶段,即将物理GPU按固定比例切分成多个虚拟GPU,每个虚拟GPU的显存相等,算力轮询。二是任意虚拟化阶段,即支持按照算力和显存两个维度进行任意切分,应用更为灵活。三是远程调用阶段,即开始支持GPU的跨物理节点调用,即便没有应用服务器,也可以远程调用其他服务器上的GPU资源。四是资源池化阶段,即借助远程调用功能,实现多台GPU服务器的资源池化,并进一步叠加了灵活调度、弹性伸缩、动态释放、监控管理等实用功能。GPU池化技术演进路线如图1所示。
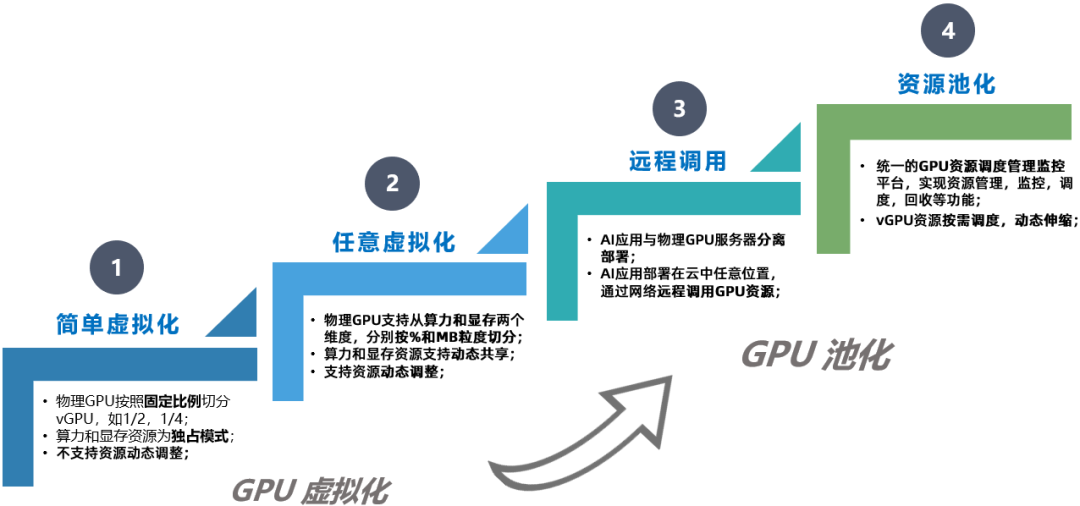
图1 GPU池化技术演进路线
2.主流技术方案分析
当前,业界主流的GPU池化技术方案主要包括硬件层隔离、Driver层虚拟化、API截获、API remoting等,其特点分析如下:
一是硬件层隔离方案,该方案采用硬件底层切分GPU的方式,具有所有方案无可比拟的隔离度,但同时也失去了灵活、动态、任意调节的能力,而且目前只能在英伟达的部分GPU上使用,局限性很大,不适合大规模GPU资源池推广。
二是Driver层虚拟化方案,该方案隔离度较好,但灵活性较低,且目前只能绑定自家云厂商使用,有较大的局限性,同样不适合大规模使用。
三是API截获方案,该方案普遍具有良好的隔离度与灵活性,但此类方案目前仍属于单机范畴的虚拟化,无法做到资源池化,而且维护起来需耗费较多精力,不具备大规模使用的特性。
四是API remoting方案, 该方案初步具备了资源池化所需的全部特性,属于比较合适的技术路线,而且业界也有成熟的商业方案,不仅支持主流云厂商虚拟化方案,开放度与包容度更高,且原生支持GPU资源池化,功能更新较快,适用于构建大规模GPU资源池。

光大银行全栈云异构算力平台
建设方案
经细致调研后,光大银行综合考量GPU虚拟化程度高、隔离度好、灵活性高、适应性强等特性,最终选定基于远程调用实现GPU池化的技术方案,并将其与全栈云容器云平台无缝集成,推动光大银行全栈云平台进入异构计算时代。
1.平台整体架构
全栈云异构算力平台通过在基础设施之上增加软件层,将AI应用与物理GPU解耦,实现了多重建设目标:一是实现GPU资源池化,支持原生容器、K8S、虚拟机、裸金属服务器和物理机等多元化部署场景;二是实现GPU远程调用,支持多机多卡聚合,以及按显存、算力两个维度进行任意切分;三是基于软件层实现了更好的兼容性和扩展性,不但支持CUDA持续更新,还支持不同GPU芯片适配,为实现全栈云异构算力平台安全可控奠定了良好基础。全栈云异构算力平台整体架构如图2所示。
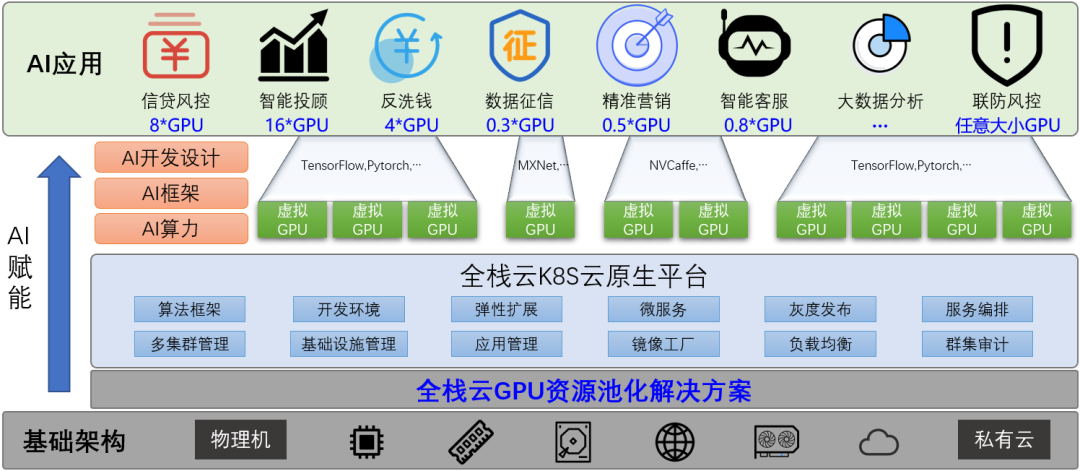
图2 全栈云异构算力平台整体架构
2.平台技术特性
通过软件定义GPU,光大银行全栈云异构算力平台重点实现了如下能力:
一是实现GPU资源远程调用(适用于对CPU 、GPU均有较高要求的场景),支持在一台普通CPU机器上部署AI任务,即可先基于本机CPU进行数据预处理,再远程调用GPU进行算力加持。
二是支持GPU资源聚合(适用于训练场景),即通过将多机多卡快速聚合到一个任务,可免去复杂的调度过程与模型拆分过程,实现快速交付。
三是支持GPU细粒度切分(适用于推理场景),即通过将GPU按需切分给多个推理任务,实现多个任务同时并发、相互隔离,进而提高资源利用率、增加业务规模。
四是支持资源动态伸缩,即所有虚拟GPU资源的分配与回收都保持动态运转,并可以按需调整、无需重启。
五是支持调用内存补充显存(适用于长尾应用叠加场景),即当GPU面临显存不足时,可以调用系统内存补充显存。
六是支持资源动态分配和释放(适用于AI算法开发场景),即仅当有AI编译程序需要运行时,才会占用物理GPU资源,并在程序执行完毕后,执行资源动态释放,从而实现GPU动态共享。
3.典型应用场景
光大银行全栈云异构算力平台上线后,AI业务将可在容器云平台基于“按需调用,动态挂载”的方式申请资源。在此模式下,虚拟GPU支持从显存和算力两个维度进行切分,当业务申请虚拟GPU资源时,将可按需配置显存和算力参数(显存最小颗粒度可设置为1MB,算力最小可设置为1%),且对于较大模型还可以指定多个虚拟GPU资源。该模式支持所有业务同时部署,并能够为其指定不同大小的算力或显存。实际操作中,并发的虚拟GPU资源申请将全部被客户端(GPU池化组件)截获并转发至GPU资源控制器(GPU池化组件),然后根据用户指定的调度策略,为其分配相应的虚拟GPU资源。默认情况下,GPU资源控制器只有在业务客户端发起资源申请时才会将虚拟GPU资源挂载到相应的业务POD(资源管理组件),并在计算任务结束时即刻释放,进而真正实现“按需调用,动态挂载”(如图3所示)。

图3 GPU资源动态挂载示意
基于上述功能,全栈云异构算力平台从根源上消除了AI应用对GPU资源的独占,可以显著提高GPU利用率;同时,借助细颗粒度的GPU切分,支持对每个业务所需的算力、显存等进行精细化控制和严格隔离,从而可将不同业务叠加在一张物理卡上,在保障资源隔离度的前提下,大幅提高资源的灵活性和使用效率。
4.成效总结
截至目前,光大银行AI中台已在全栈云异构算力平台上成功投产,并在一年多的建设与推广过程中取得显著成效:一是通过GPU资源池化,AI业务运行效率显著提高,整体GPU资源利用率大幅提升,同时结合任意切分和按需分配机制,在同等GPU数量的前提下,实现了数倍业务量的弹性扩展。二是基于自助申请、动态分配设计,支持不同业务实现资源共享,有效避免算力孤岛,大幅提高算力资源利用率,有效降低了硬件采购成本。三是通过构建高效、灵活、弹性的异构算力资源池,支持用较少的芯片(耗能)来支持更多的AI业务,助力实现碳达峰、碳中和目标。GPU资源池化前后的利用率对比如图4所示。
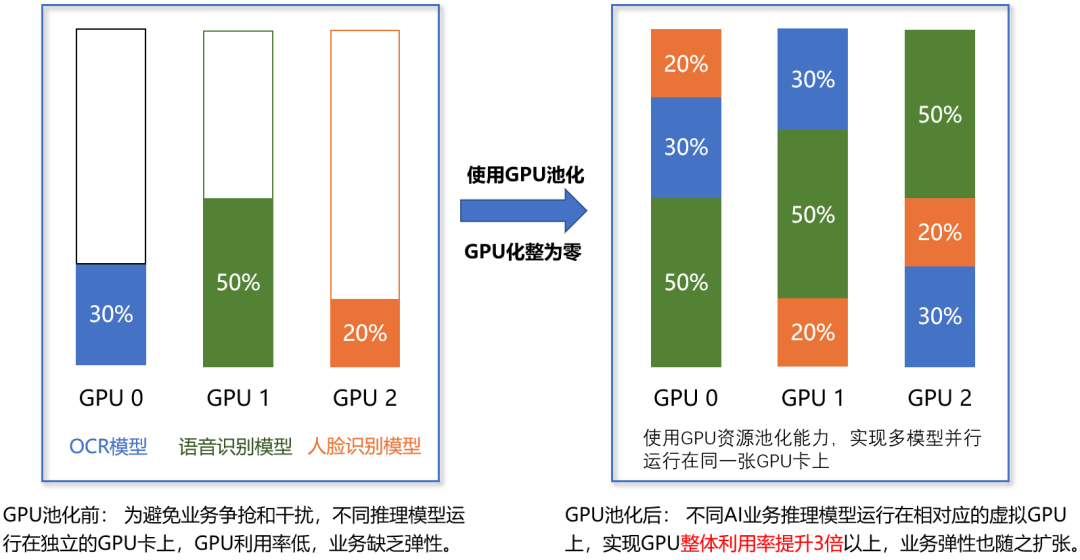
图4 GPU池化前后资源利用率对比

未来展望
后续,面向大模型、大算力等发展趋势,光大银行将继续探索优化资源调度策略、提高资源利用率的可行路径与方法,如结合不同业务的昼夜峰值特性,探索实现昼夜切换分时复用,以及针对在线、离线业务的算力差异,探索在线与离线混合部署,减少算力碎片,进一步提高GPU利用率;同时,积极参与GPU生态共建,结合业务演进需求与金融AI场景落地,努力探索安全可控的GPU替代方案,更好助力光大银行实现智能化转型与高水平发展。

来源 | 中国金融电脑+
视觉 | 王朋玉
统筹 | 郑 洁



