





近年来,随着金融行业数字化转型的不断深入,银行的业务场景也更加丰富,随之而来的是各类精细化和多样化的数据,以及衍生出的创新型数据分析场景。为满足一些场景对于实时数据的分析需求,银行需要改变传统数据湖T+1时效的批量数据处理和分析。本文介绍了应对实时数据分析场景下,实时数据湖相关技术的发展和特性,以及应用场景的探索与实践。

数据湖技术的现状及问题
数据仓库和数据湖经过多年的发展,其整体处理流程是从源系统以离线文件的方式获取到数据,然后以批量的方式进行数据的逻辑加工处理,最后的结果才能给数据集市以及数据科学家提供使用。随着实时营销、实时反欺诈等对于数据实时分析的诉求,现有的数据处理方式已不能满足业务要求。
为了应对实时数据的处理,业界首先提出了Lambda架构,同时发挥批处理和流处理的优势。通过批处理提供全面、准确的数据,通过流处理提供低延迟的数据。在使用数据时,为了满足下游系统的即席查询,需要将批处理和流处理的结果进行合并。但在Lambda架构的具体实现过程中,会存在同一套处理逻辑分别实现批和流的程序代码导致的数据口径问题,开发维护的复杂性等一些问题。
针对Lambda架构的缺陷,业界提出了Kappa架构,在处理流程中去掉了批处理层,用消息队列替代了数据通道,整体技术以流处理为主,当需要进行离线分析或者再次运算的时候,则将数据湖的数据再次经过消息队列重播一次则可。Kappa架构的优势只需要维护一套实时处理模块,无需进行批流数据整合操作。但缺点是消息中间件的缓存和回溯能力存在性能瓶颈,同时在多条数据流进行关联操作时,严重依赖实时计算处理能力,可能因为数据流的先后顺序问题导致逻辑错误。

实时数据湖技术特性
为了解决Kafka架构中消息中间件缓存的性能缺陷,以及无法支持OLAP访问的问题,近两年开源界又衍生出改进版的Kappa架构——LakeHouse湖仓一体技术。从Gartner 2021年度数据管理领域的成熟度模型报告来看,无论是开源社区还是云厂商之间,对于Data Lake都已经有了成熟的解决方案,但对于LakeHouse,目前的一些开源技术还处于初步应用阶段,不论是国外还是国内互联网等行业,很多公司正在将其逐步应用到各自的业务系统中,并为业务带来了更多价值。
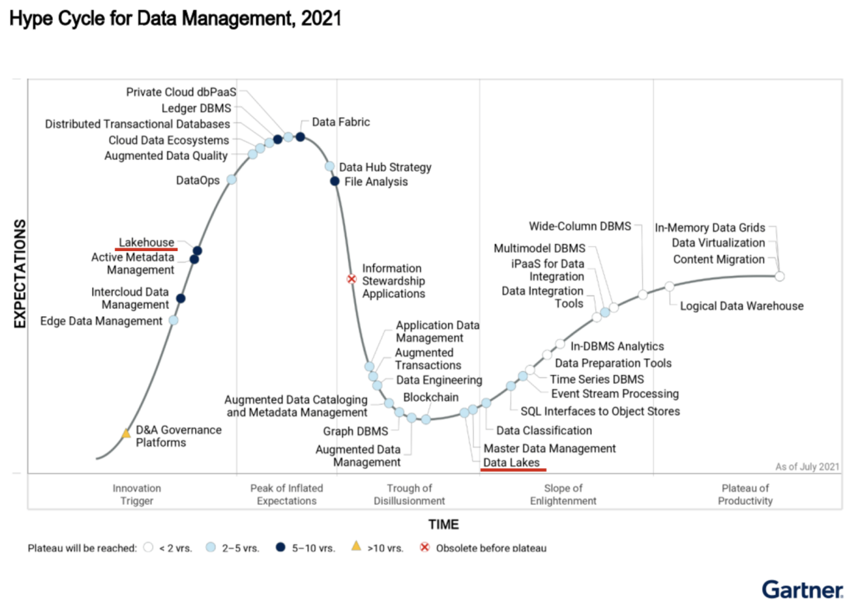
图1 Gartner 2021年度数据管理领域的成熟度模型报告
LakeHouse作为一种新的数据技术架构,它在数据湖的基础之上,吸收了数据仓库,数据库的一些特性。它提供了构建于存储格式之上的统一的数据组织方式,提供ACID语义,以及一定的事务特性和并发能力,同时支持多种查询分析引擎。
统一数据组织方式
在语义上引入table format层,将数据文件封装成有业务含义的table,底层存储格式能够支持Parquet/ORC列存格式,以及Avro等行存格式,最终将数据组织分类存放在HDFS的不同层级目录下,对外提供统一的查询和写入接口。此外对于HDFS上的小文件所引起的性能问题,需要提供文件合并和历史数据清理功能。
ACID语义和隔离级别支持
相比于传统的Hive数据库技术,湖仓一体技术需要提供ACID语义和事务支持,支持update/delete操作,同时提供Write Serialization、Snapshot Isolation等不同级别的隔离方式,此外,对用户可以提供一个时间点来查询对应时间上的表快照数据(Time Travel),也是一个必备特性。
支持多种分析引擎
提供统一的应用访问接口,能够对接并集成现有主流的大数据计算分析引擎组件,包括HIve、Spark、Flink、Presto等。
Schema变更设计和支持
在Schema方面,湖仓一体技术在设计上要能够兼容表级变更(重命名、修改属性),列级变更(增加、删除、重命名、修改属性),同时在具体的实现上也应该提供对应的Schema访问接口,而不应该绑定到具体的某个计算引擎之上。
查询性能优化
针对读多写少或者写多读少的不同业务场景,需要支持Copy On Write和Merge on Read的存储方式进行性能优化,同时在数据查询时提供Filter Pushdown、Indexing with partitions等优化技术。
在LakeHouse湖仓一体化技术的具体实现上,有三种主流的开源数据库技术,分别是Delta Lake、Apache Iceberg和Apache Hudi。每种技术所支持的功能完整性如下表格所示:
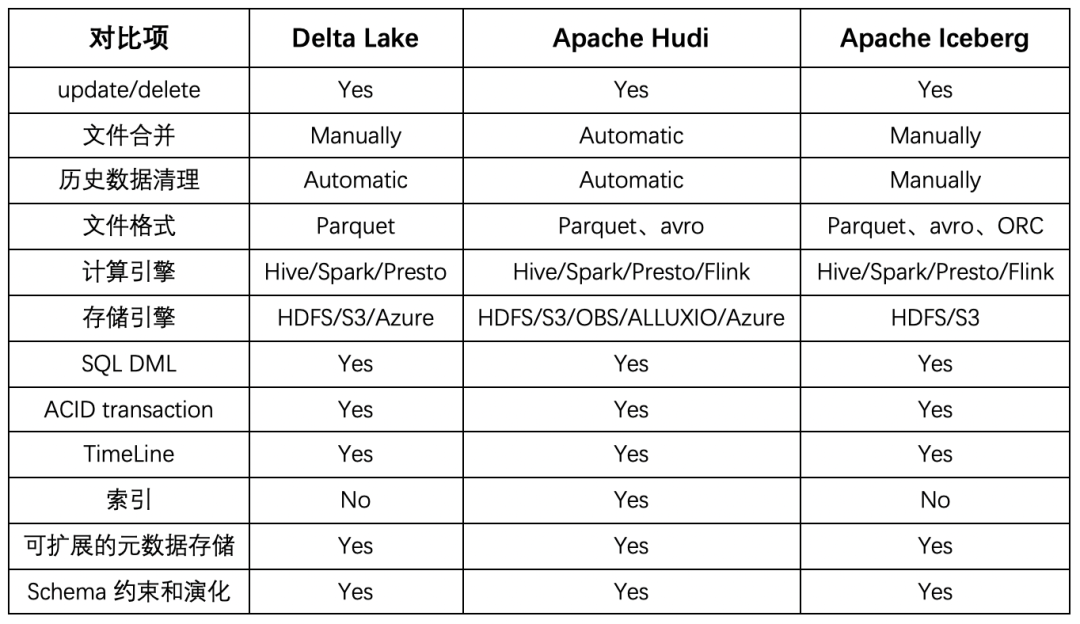
表1 开源湖仓技术功能对比
这三种开源数据湖技术在创立之初所侧重场景和功能上有所不同。Delta Lake定位于流批一体的数据处理,与Spark计算框架深度绑定,尤其是在写入路径层面上。Apache Iceberg定位在高性能的分析及数据管理上,它的亮点是有一个通用化设计的Table Format层,完美的解耦了计算引擎和底层的存储系统。Apache Hudi侧重在数据的增量更新上,在upsert和compaction两方面功能比价完善,解决了传统Hive最大的痛点。

实时数据湖技术的应用场景
近实时数据入湖
在现有的Hive技术上,不支持文件更新,想做到数据的实时读取基本不可能实现,在引入实时数据湖技术后,通过准实时数据平台的Kafka消息队列,可以不断获取增量数据进行数据的持续写入和更新,将现有数据湖T+1的时效性提升到分钟级别。
近实时数据的联机分析处理
近实时的数据通过实时数据湖技术入湖后,从底层统一了数据的存储。通过Spark,Presto等计算引擎,可以只使用一套代码进行近实时的数据分析处理。解决了之前准实时数据分析方案中的流批代码分离,以及借助于中间件进行分析和查询时的性能问题。
近实时数据的数据模型
通过获取到的增量的近实时数据,在一些特定场景下,数据仓库可以进行分钟级的ETL处理,来完成近实时的中间层和模型层的构建,处理后的结果可以满足数据集市系统对于中间层和模型层的近实时数据查询与分析需求。

总结
开源数据湖技术在经历了两三年的发展和演进后,解决了传统数据湖技术所带来的一些关键痛点,自身也引入了一些新的问题,后续各个实时数据湖技术框架需要在各类功能细节、读写性能、元数据管理等方面,更进一步的持续完善和优化。在具体实践中我们也将选择一些适合的业务场景,逐步开展实时数据湖技术的落地工作,为银行各类数据分析场景挖掘出实时数据的最大价值。

作者 | 刘 鉴
视觉 | 王朋玉
统筹 | 郑 洁



