




namenode:命名空间管理节点,负责HDFS元数据的管理,以及数据块读取和写入过程中的资源管理与分配等 datanode:数据任务节点,负责存储数据文件,负责与客户端之间、数据块之间的文件读取和写入 block:数据块,HDFS数据存储按照数据块(block)为单位,Hadoop2.x之后默认大小为128M packet:数据包,每次在管道中传输数据需要将数据封装成一个packet,默认为64KB,包含了packet包头、校验chunk和数据chunk pipeline:管道或流水线,应客户端请求,namenode提供存储block副本的datanodes,顺序建立数据副本传输管道,形成链式数据流的传输、存储和写入确认(ACK)
2、HDFS数据读取整体架构流
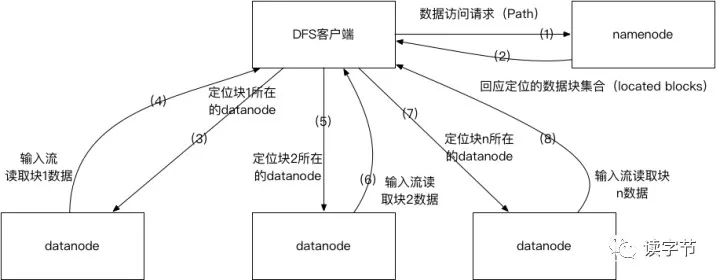
客户端向hdfs namenode节点发送Path文件路径的数据访问的请求 Namenode会根据文件路径收集所有数据块(block)的位置信息,并根据数据块在文件中的先后顺序,按次序组成数据块定位集合(located blocks),回应给客户端 客户端拿到数据块定位集合后,创建HDFS输入流,定位第一个数据块所在的位置,并读取datanode的数据流。之后根据读取偏移量定位下一个datanode并创建新的数据块读取数据流,以此类推,完成对HDFS文件的整个读取。
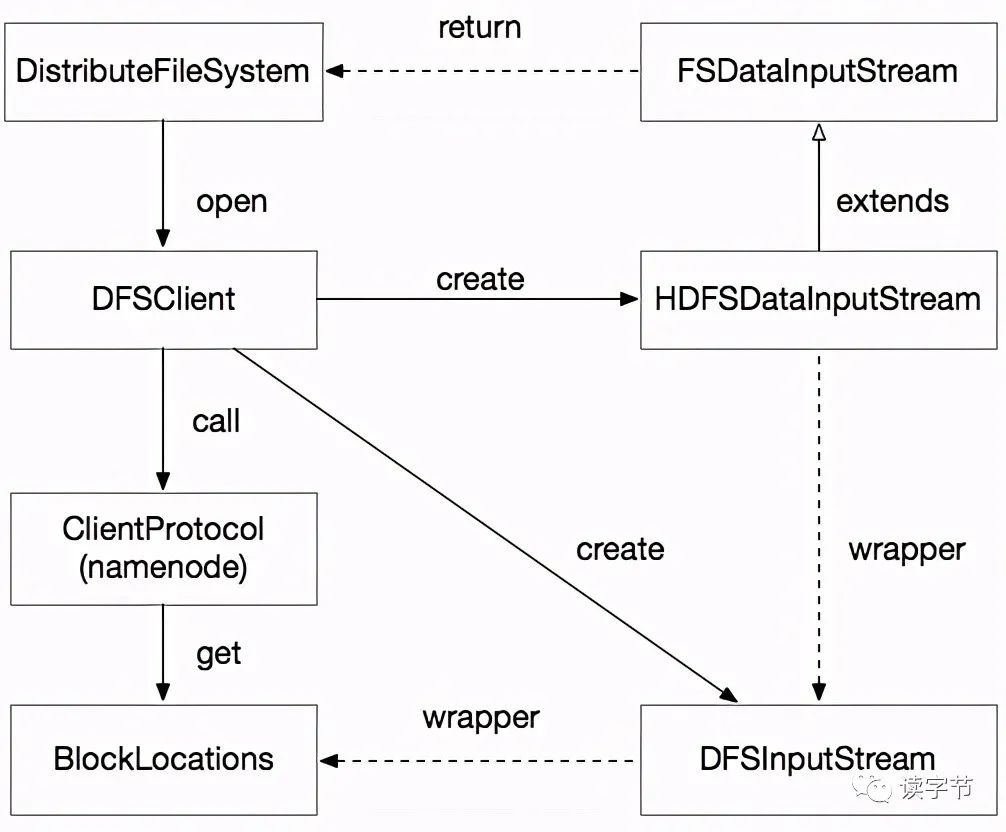
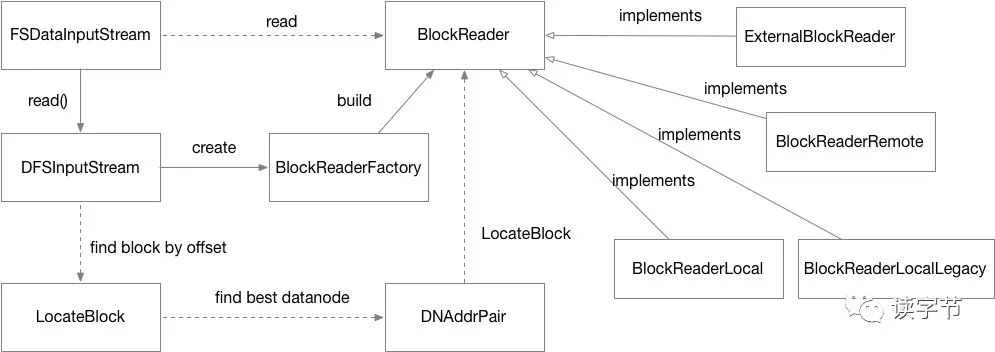
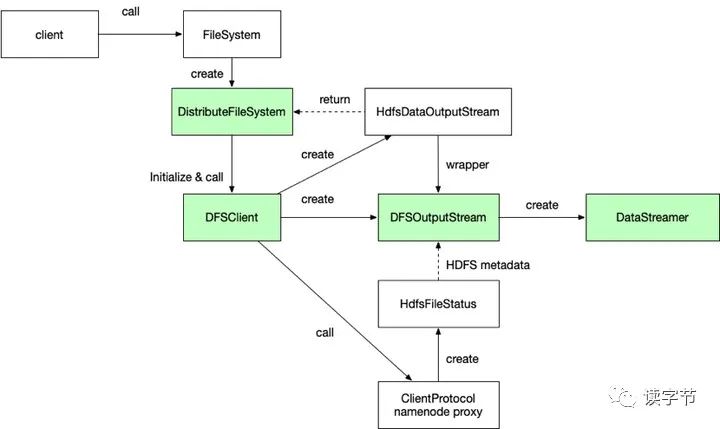
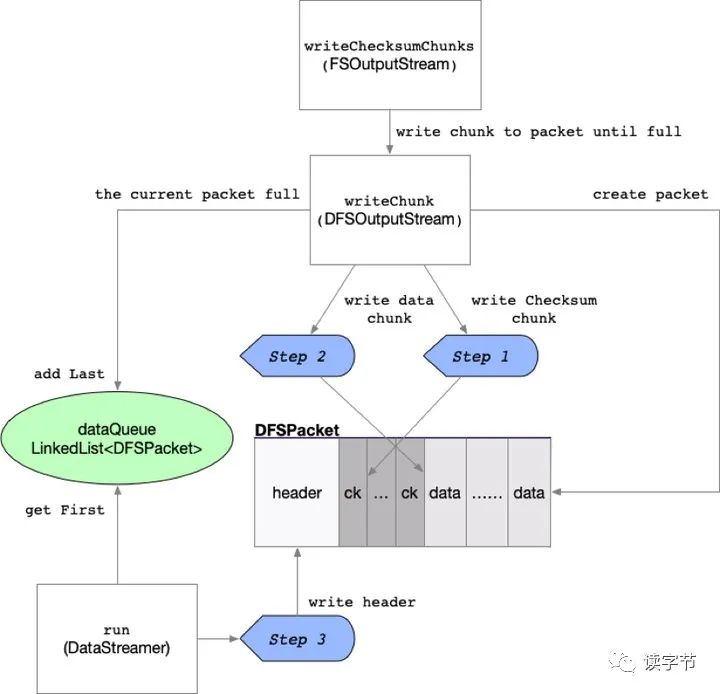
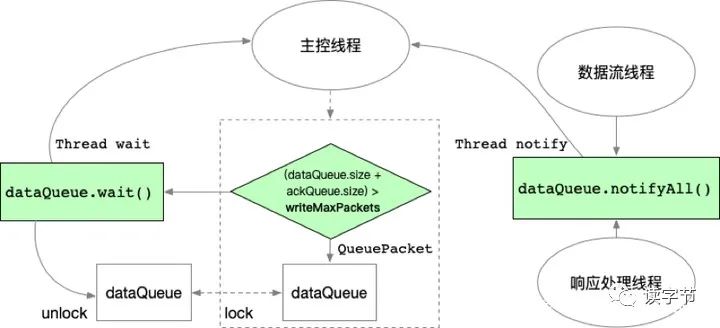
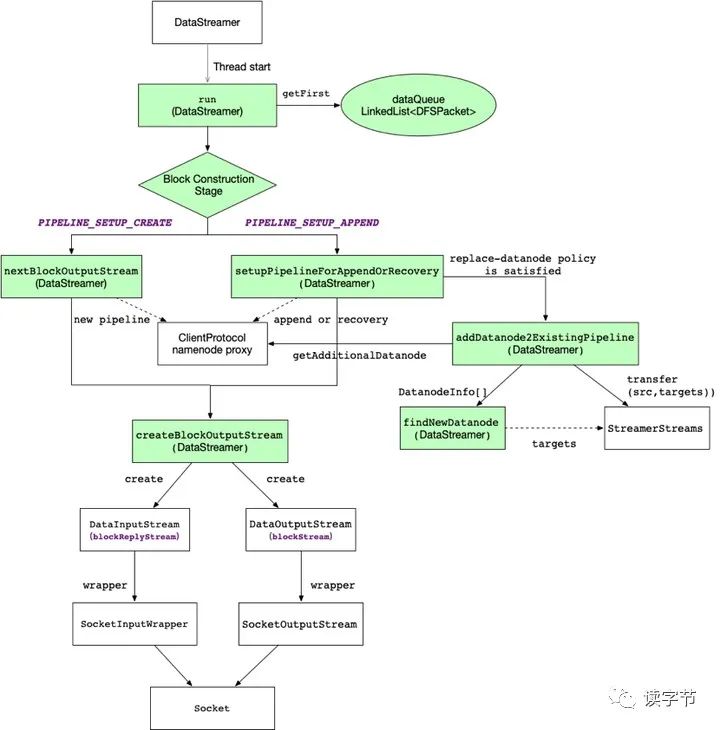
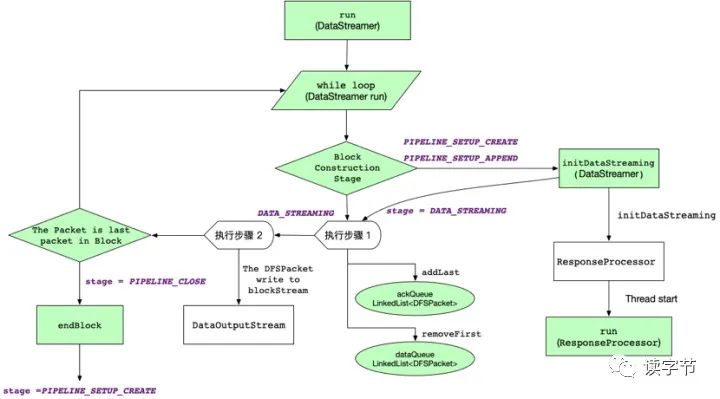
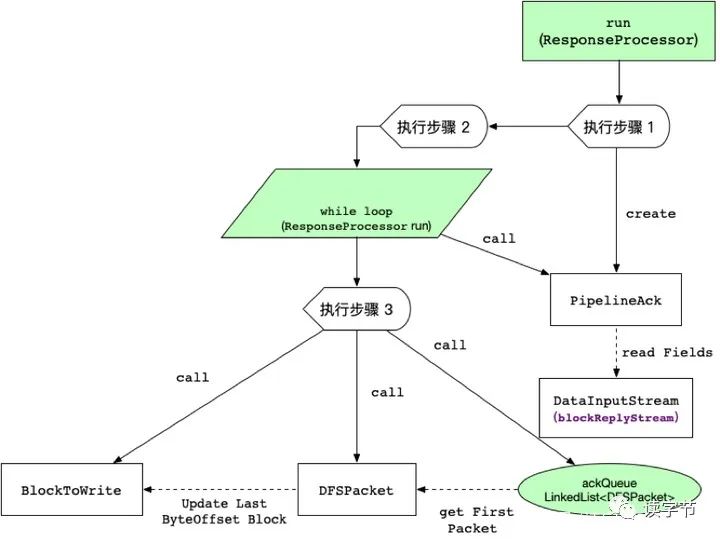
3、HDFS客户端数据写入流程

4、结束
文章转载自守护石技术研究,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
