




👆戳蓝字“读字节”关注
续
上篇大数据平台的SQL查询引擎有哪些(上)?我们首先对大数据平台的SQL查询引擎都有哪些,做了一个总体的概述。进入到具体技术的架构分类描述上,先列出来了Hive-On-Hadoop架构,Impala架构。本篇为中篇,会继续对SQL查询引擎中其他三款:Presto、Spark SQL、Phoenix的架构进行解读和描述。
Impala VS Presto
2013年Facebook开源了Presto,支持标准ANSI SQL。Presto的特点特别适合与Impala做一个比较。
首先如果把Impala比喻成一位用情专一的君子,那么Presto就是处处留情的公子。Impala用于查询的主要基础存储系统就是Hadoop HDFS与HBase,我们再看看Presto都设计了多少种存储连接:
Accumulo Connector |基于HDFS的K-V存储
BigQuery Connector |Google的大数据查询引擎云服务
Cassandra Connector
Druid Connector | 实时分析型数据库
Elasticsearch Connector
Hive Connector
Kafka Connector
Kudu Connector |基于HDFS的列式快速分析存储系统
Local File Connector
Memory Connector |直接在内存中建立数据表进行操作
MongoDB Connector
MySQL Connector
Oracle Connector
PostgreSQL Connector
Redis Connector
SQL Server Connector
Thrift Connector |远程过程调用RPC框架
......
但是有一点我感到很不解,Presto都支持那么多存储系统和框架了,而且最早的设计初衷就是为了Hadoop HDFS的高效查询,既然Impala都是直接支持HBase了,为什么Presto不支持HBase呢?有了解情况的朋友还希望给予指点。如下图所示:
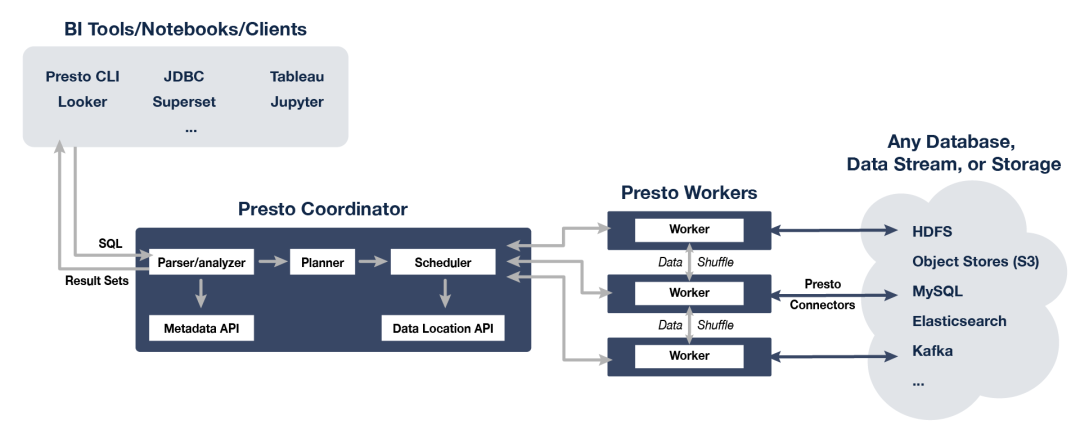
其次,Impala更像是一个传统的大规模并行处理(MPP)数仓工具,每个进程都是独立接受客户端请求的,客户端连接到哪个服务,该服务就作为分布式调度者,大家可以看看上篇中的Impala架构图。
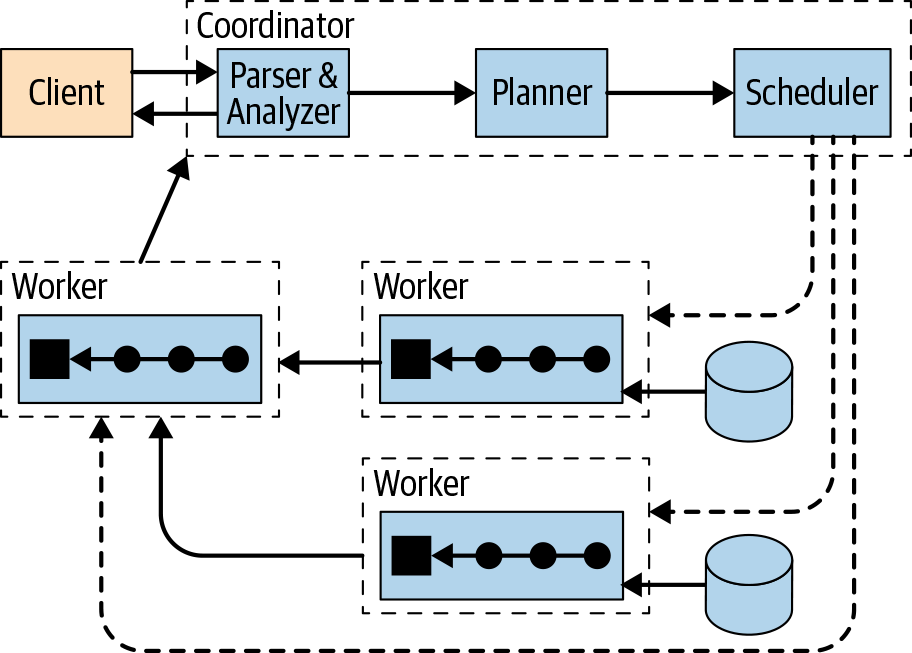
但是Presto就是一个标准的主从架构了,客户端要先与主节点打交道,主节点再将SQL解释后的执行计划分配到不同的work节点去执行,并由一个work节点作为结果汇聚返回节点,如下图所示:
最后,我们再看看Impala和Presto在SQL解释、优化和调度之间的对比。如下图所示:左边是Impala架构,右边是Presto架构。
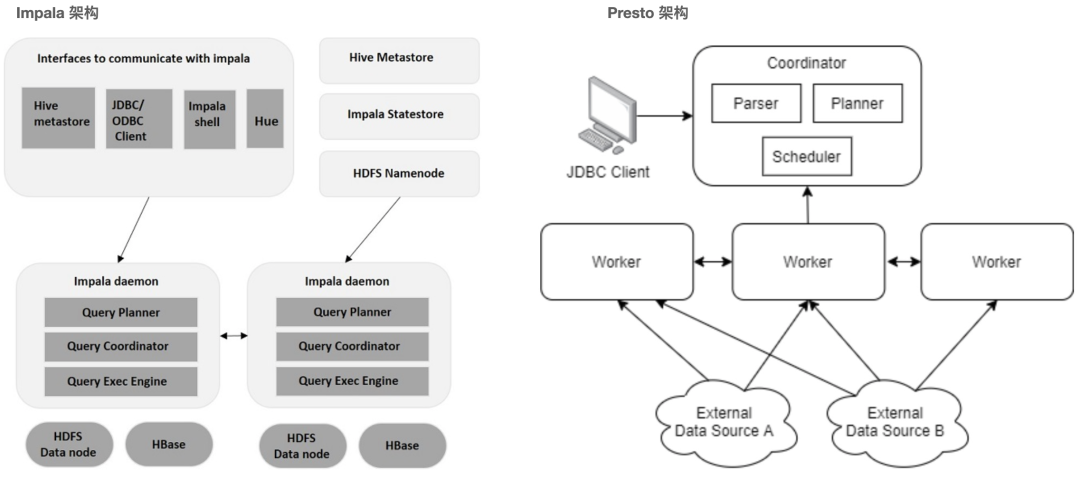
上篇已经描述过Impala主要是任意连接客户端的Impalad后台服务,接收SQL请求,解析SQL并制定执行计划后,由当前节点在Query Coordinator阶段对执行计划各个部分进行调度分配,再由集群其他Impalad后台服务根据调度进入Query Exec Engine阶段实现并行处理。最终结果还是汇聚到调度节点反馈客户端。
Presto获取用户提交的SQL查询,首先进行SQL语句解析( Parser),接着形成逻辑计划相关对象(Planner)放入线程池,最后由调度器(Scheduler)对逻辑计划生成的SubPlan提交到多个Work节点上执行。
其他特性对比
Presto也是完全基于内存的并行计算,注意内存保护,根据数据量情况,为每个节点设置合适的内存大小,否则大数据量情况下,内存溢出就是家常便饭;Impala2.0之后支持内存不够情况,数据吐给磁盘,虽然有了可靠性保护,但是内存与磁盘的I/O交换会带来更慢的吞吐。
Presto由调度节点(Coordinator)和注册与发现节点(Discovery Service)实现SQL执行的集群调度管理,由于Coordinator和Discovery Service都是单节点部署,可能会因为Coordinator故障,产生多个Coordinator服务,导致集群的脑裂问题,因此一般建议都是Coordinator和Discovery Service放在一个节点上部署,形成Discovery对Coordinator的唯一性指定,然后再做成一主一备两个节点形成HA,这样主节点服务挂掉,备集群Work都连接到备节点上,实现主备节点的热替换。
Impala的后台服务因为是无共享的架构模式,非常适合集群节点的无限扩张,但往往需要在Impala集群之上安装一个客户端请求负载均衡器,实现对Impalad服务的负载调度。
最后就是Impala的架构更适合于计算与存储放在一起的就近读取原则,有效防止网络传输数据的损耗;但是Presto的架构更倾向于计算与存储分离,存储系统多样化的支持,虽然使自身变得灵活,适配性高,但是默认读数据源并不是采用就近读取原则,导致计算访问数据都是远程操作,例如:在复杂的大数据集Join操作,会导致严重的网络传输的性能损耗。

——点击“阅读原文”即可获取更多精彩内容——


