




 是新朋友吗?记得点击下面名片,关注我哦
是新朋友吗?记得点击下面名片,关注我哦

1、spark相关服务启停
1.0、本地环境
>web端查看HDFS的NameNodehttp://hadoop101:9870>web端查看yarn的ResourceManagerhttp://hadoop102:8088>历史服务器地址http://hadoop103:19888/jobhistory可以访问spark 安装路径 opt/module/spark-3.3.2/
1.1、单独启停spark
cd opt/module/spark-3.3.2/sbin#启动主节点--hadoop101上执行start-master.sh#启动从节点-all--hadoop101上执行start-slaves.sh重定向到了 start-workers.sh#启动从节点-single---分别在对应节点上执行start-slave.sh重定向到了 start-worker.sh启动命令格式:sh start-slave.sh master-url:7077备注:此例master 主机名为 hadoop101【示例】:#在hadoop102、hadoop103上面分别执行下面命令启动该节点上work./start-worker.sh spark://hadoop101:7077#启动shellspark-shell
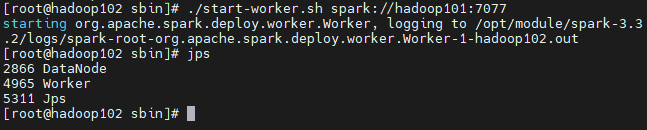
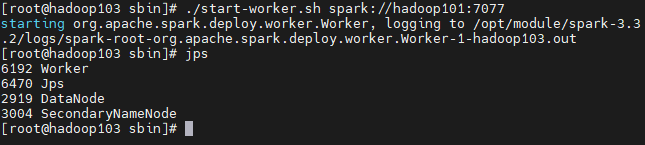
#验证
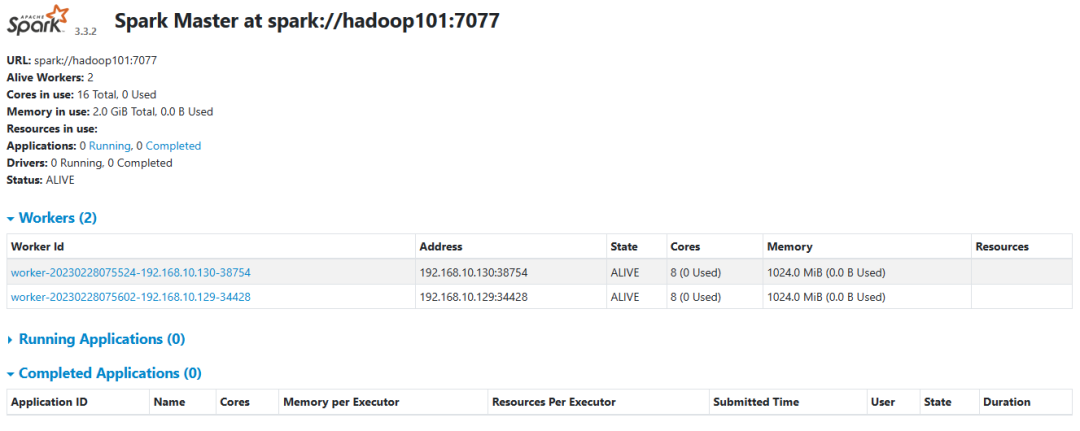
#关闭主节点--hadoop101上执行stop-master.sh#关闭从节点--all--hadoop101上执行stop-slaves.sh重定向到了 stop-workers.sh#关闭从节点--single--分别在对应的服务器上执行关闭命令格式:sh stop-worker.sh master-url:7077备注:此例master 主机名为 hadoop101【示例】:#在hadoop102、hadoop103上面分别执行下面命令启动该节点上work./stop-worker.sh spark://hadoop101:7077



1.2、整体启停spark
spark部署地址:/opt/module/spark-3.3.2/
cd opt/module/spark-3.3.2/sbin
#停止spark./stop-all.sh#启动spark./start-all.sh
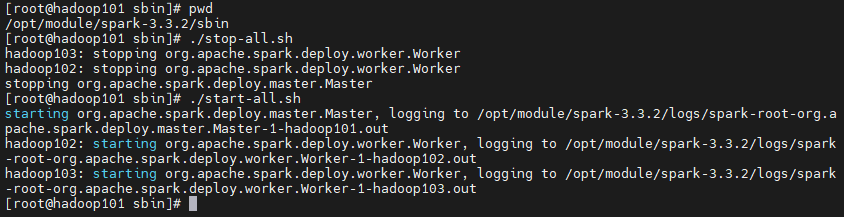
备注:stop-all.sh、 start-all.sh 容易和hadoop相关命令混淆,所以建议切换到spark sbin路径下执行上面命令。
1.3、启动spark-shell
spark-shell
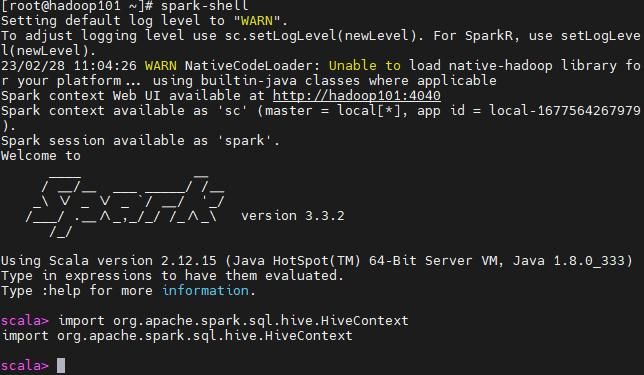
备注:执行命令
import org.apache.spark.sql.hive.HiveContext
返回上面信息,即代表Spark版本包含Hive支持,能够访问Hive
#扩展信息
启动spark后,运行bin/spark-shell会出现一个警告WARN util.NativeCodeLoader: Unable to load native-hadoop libraryfor your platform... using builtin-java classes where applicable> 解决办法:(1)第一种:在linux环境变量里设置linux共享库:命令行输入一下命令vim /etc/profileexport LD_LIBRARY_PATH=$HADOOP_HOME/lib/native/:$LD_LIBRARY_PATHsource etc/profile(2)第二种:设置环境变量和conf/spark-env.shvim /etc/profileexport JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native/source etc/profile进入conf/spark-env.sh目录下:vim conf/spark-env.shexport LD_LIBRARY_PATH=$JAVA_LIBRARY_PATH问题就解决了
1.4、启停Spark History Server
SparkHistoryServer ,spark 历史服务可以记录spark应用程序的运行过程,方便定位与查找问题
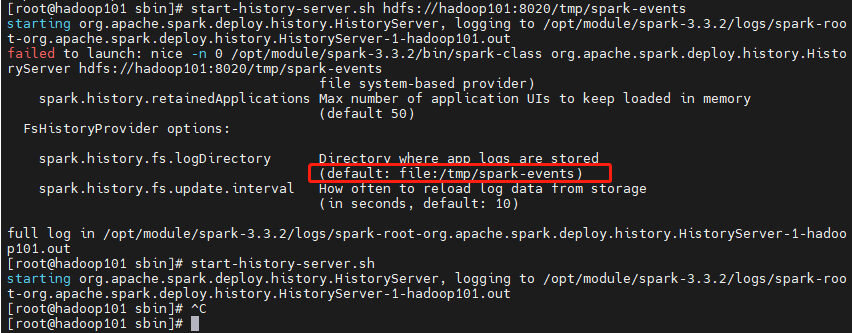
start-history-server.sh
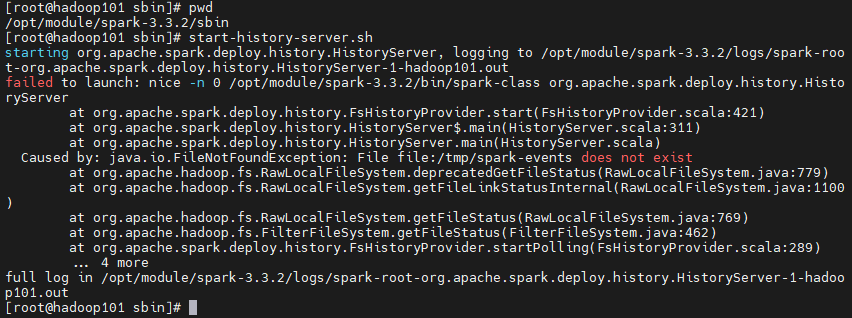
#解决方案
spark history server 默认应用日志存储路径 本地 tmp/spark-events
chmod -R 777 tmp/spark-events 赋予读写权限 至少666
新建该文件夹 ,然后重试该命令
备注:可以参考扩展信息中属性
spark.history.fs.logDirectory,参数配置hdfs路径存储日志
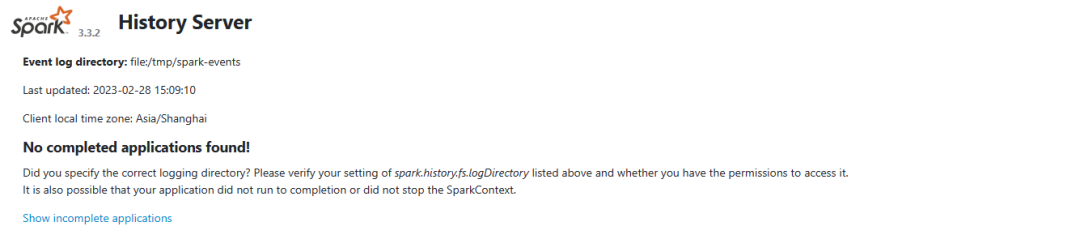
启动完成之后可以通过WEBUI访问,默认端口是18080:http://hadoop101:18080
默认界面列表信息是空的,跑了spark-sql测试后会出现的
初始化的时候:
#停止spark history server
stop-history-server.sh

#扩展信息-history server 相关的配置参数
配置指南:以spark.history开头的需要配置在spark-env.sh中的SPARK_HISTORY_OPTS,以spark.eventLog开头的配置在spark-defaults.conf1) spark.history.updateInterval默认值:10以秒为单位,更新日志相关信息的时间间隔2)spark.history.retainedApplications默认值:50在内存中保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,当再次访问已被删除的应用信息时需要重新构建页面。3)spark.history.ui.port默认值:18080HistoryServer的web端口4)spark.history.kerberos.enabled默认值:false是否使用kerberos方式登录访问HistoryServer,对于持久层位于安全集群的HDFS上是有用的,如果设置为true,就要配置下面的两个属性5)spark.history.kerberos.principal默认值:用于HistoryServer的kerberos主体名称6)spark.history.kerberos.keytab用于HistoryServer的kerberos keytab文件位置7)spark.history.ui.acls.enable默认值:false授权用户查看应用程序信息的时候是否检查acl。如果启用,只有应用程序所有者和spark.ui.view.acls指定的用户可以查看应用程序信息;否则,不做任何检查8)spark.eventLog.enabled默认值:false是否记录Spark事件,用于应用程序在完成后重构webUI9) spark.eventLog.dir默认值:file:///tmp/spark-events保存日志相关信息的路径,可以是hdfs://开头的HDFS路径,也可以是file://开头的本地路径,都需要提前创建10)spark.eventLog.compress默认值:false是否压缩记录Spark事件,前提spark.eventLog.enabled为true,默认使用的是snappy
1.5、web 端访问
spark 监控:
http://hadoop101:8080/
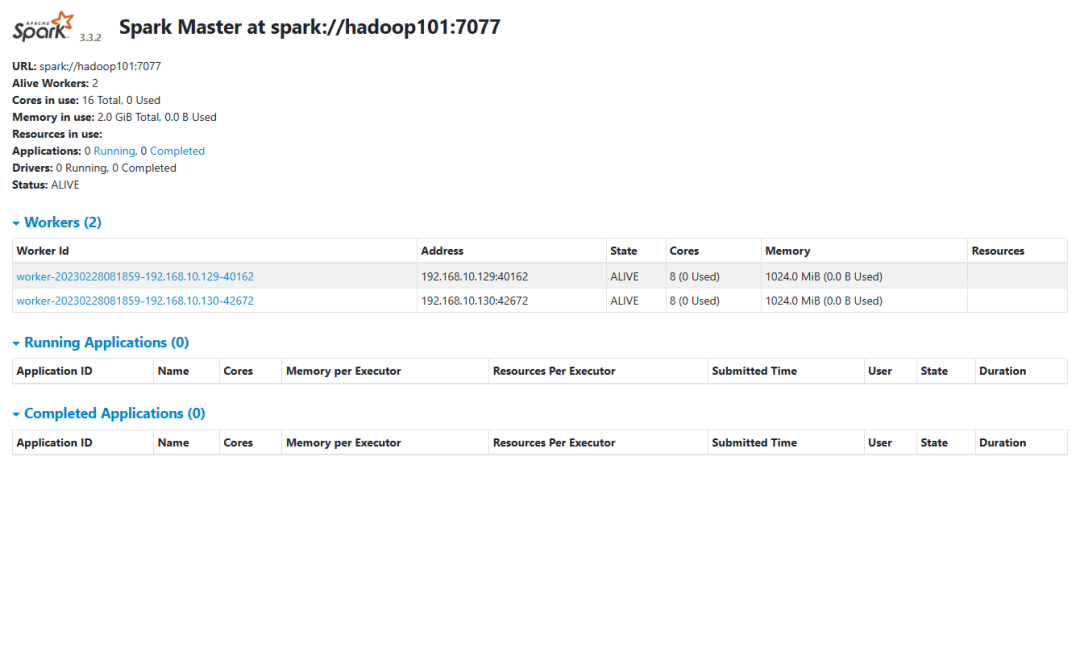
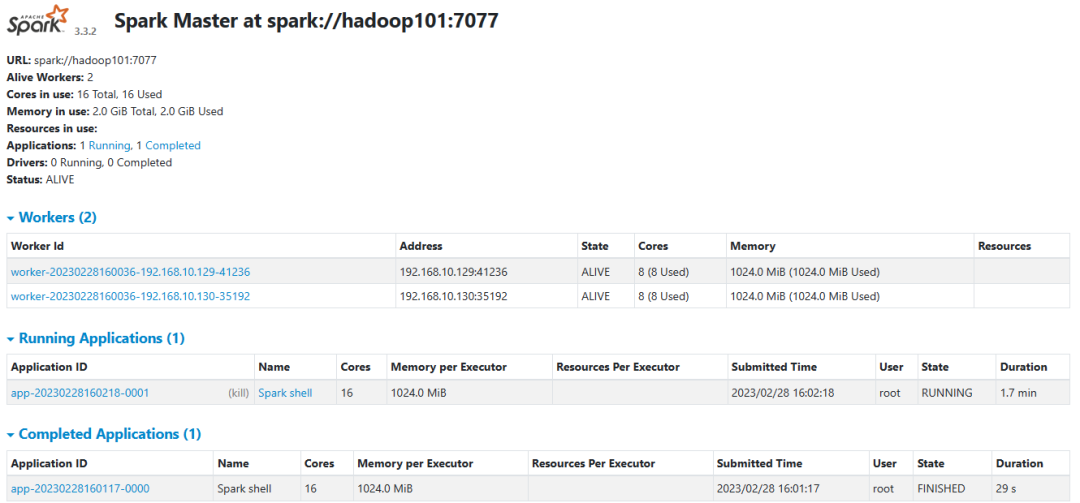
历史服务:
http://hadoop101:18080
spark-shell :
http://hadoop101:4040


2、spark-sql
Spark SQL是Spark生态系统中非常重要的组件, 用于结构化数据(structured data)处理的Spark模块,其前身为Shark。Shark是Spark上的数据仓库,最初设计成与Hive兼容,但是该项目于2014年开始停止开发,转向Spark SQL。Spark SQL全面继承了Shark,并进行了优化。
需要和hive 结合使用,不急,慢慢来,逐步的安排 。

3、spark-shell
Spark shell 作为一个强大的交互式数据分析工具,提供了一个简单的方式学习 API。它可以使用 scala(在Java 虚拟机上运行现有的Java库的一个很好方式)或 Python。
当我们的spark shell 程序提交后我们可以在
http://hadoop101:8080/
的Running Applications 中看到。
3.1、启动和验证命令
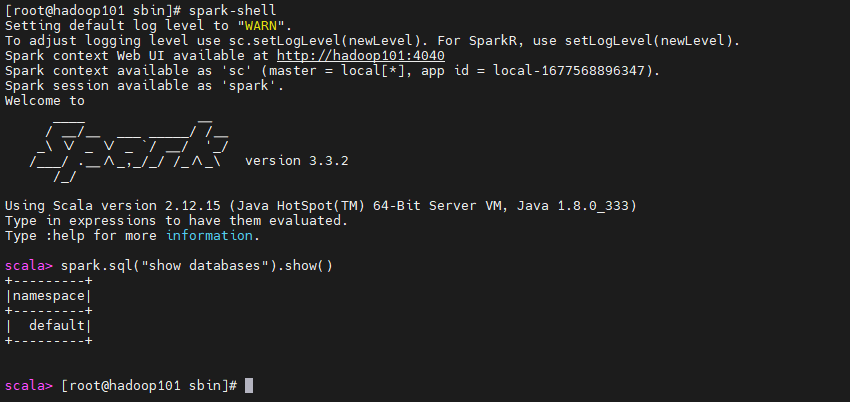
启动spark shell 的时候不指定master,默认本地spark
spark-shellspark.sql("show databases").show()退出:ctrl+c
#spark-shell 命令参考
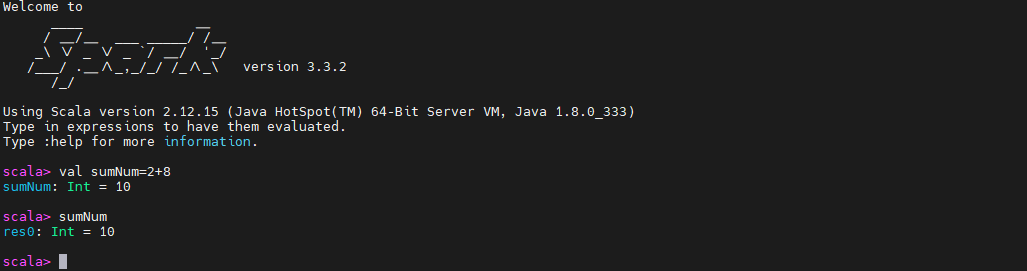
#scala验证
val sumNum=2+8
sumNum
3.2、启动指定master
3.2.1、指定本地spark集群
spark-shell --master spark://hadoop101:7077
这种就是我们自己搭建的spark 集群
3.2.2、指定yarn
spark-shell --master yarn-client --executor-memory 1G --num-executors 1
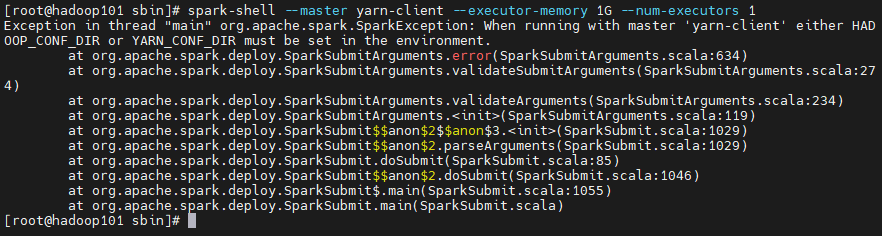
需要配置相关配置文件,参考第5章完成“yarn 模式部署”

4、spark-submit
spark-submit 是spark 给我们提供的一个提交任务的工具,就是我们将代码打成jar 包后,提交任务到集群的方式
添加参数 --master ,指定driver 生成在哪个节点。
4.1、yarn
--master yarn 有下面2种模式
4.1.1、cluster模式
范例脚本:
spark-submit --class org.apache.spark.examples.SparkPi \--master yarn \--deploy-mode cluster \--driver-memory 1g \--executor-memory 1g \--executor-cores 1 \--num-executors 5 \--queue default \/opt/module/spark-3.3.2/examples/jars/spark-examples_2.12-3.3.2.jar \1000
执行结果:
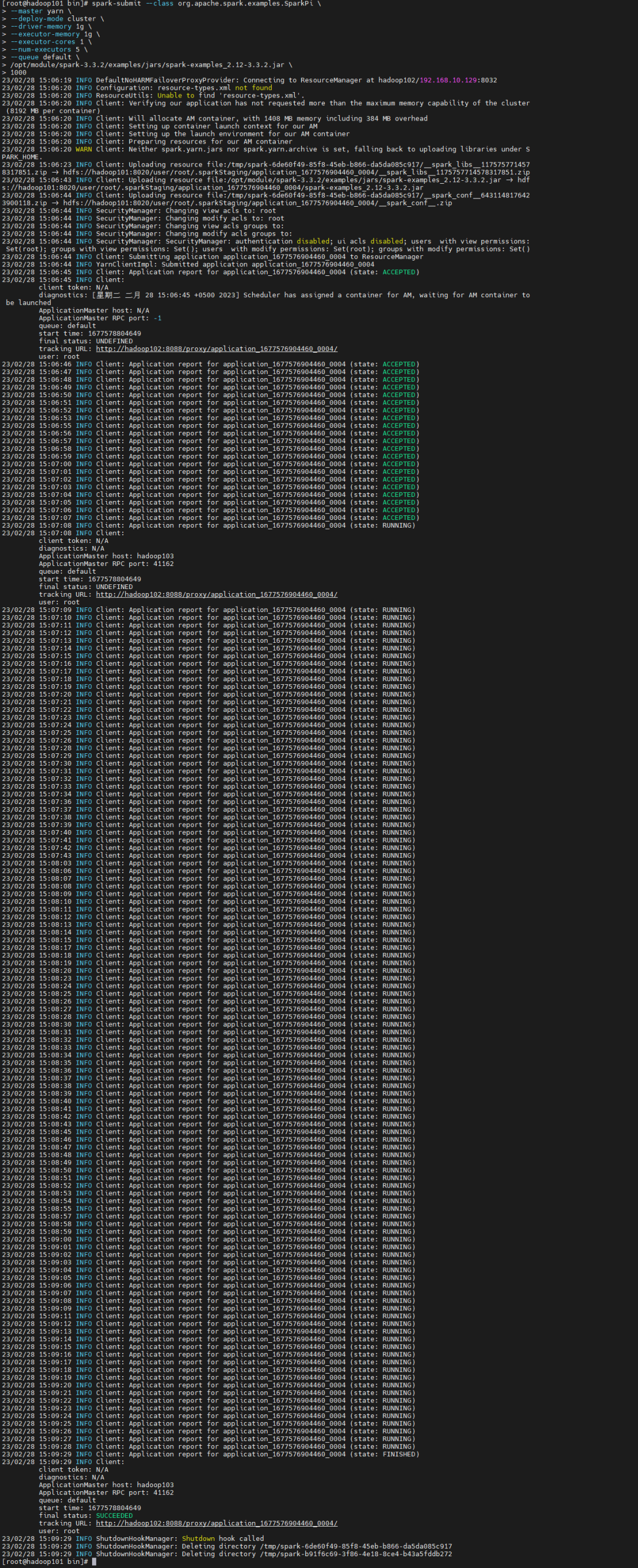
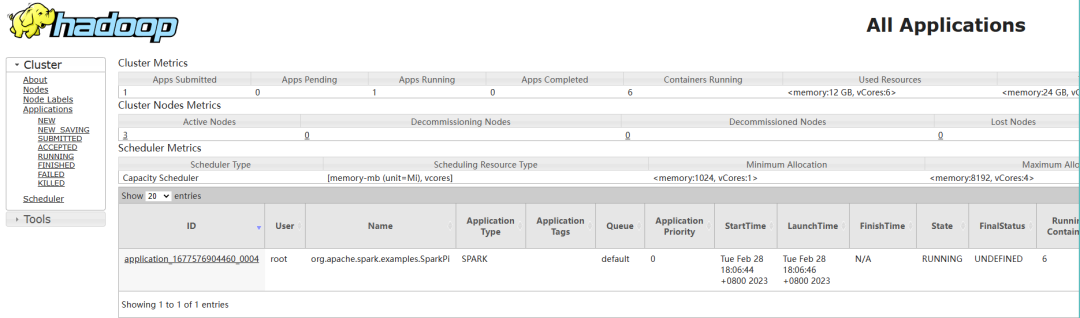
#登录yarn webui上面看是否提交
http://hadoop102:8088/cluster
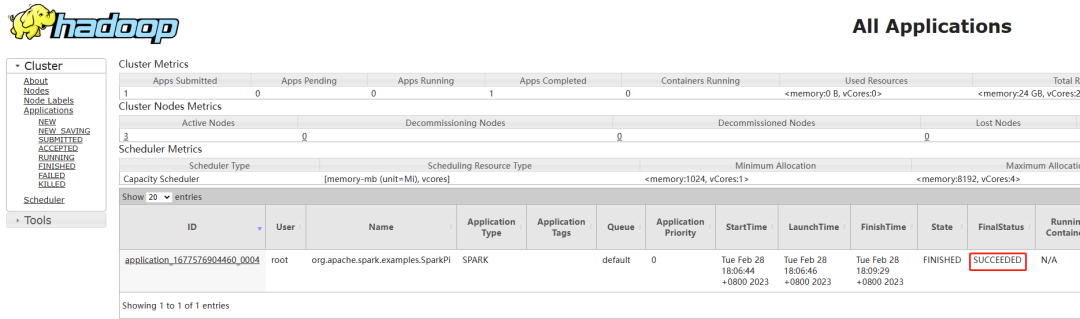
4.1.2、client模式
范例脚本:
spark-submit --class org.apache.spark.examples.SparkPi \--master yarn \--deploy-mode client \--driver-memory 1g \--executor-memory 1g \--executor-cores 1 \--num-executors 5 \--queue default \/opt/module/spark-3.3.2/examples/jars/spark-examples_2.12-3.3.2.jar \1000
执行结果如下:
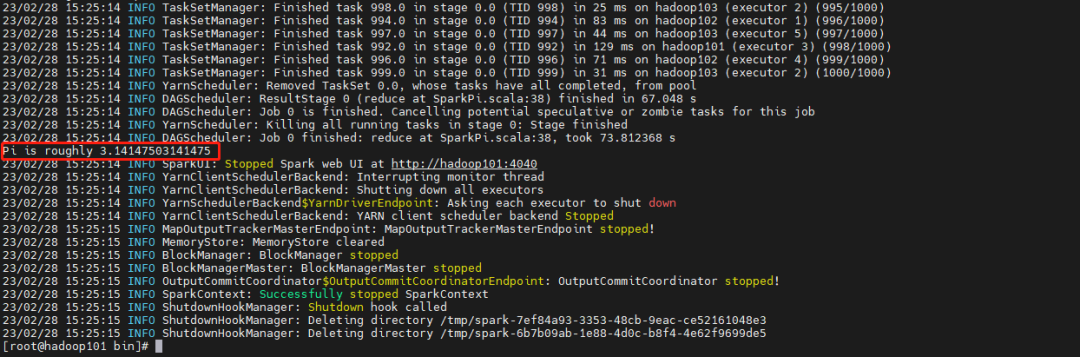
4.2、本地
范例脚本:
spark-submit --class org.apache.spark.examples.SparkPi \--master local \--driver-memory 1g \--executor-memory 1g \--executor-cores 1 \--num-executors 5 \--queue default \/opt/module/spark-3.3.2/examples/jars/spark-examples_2.12-3.3.2.jar \1000
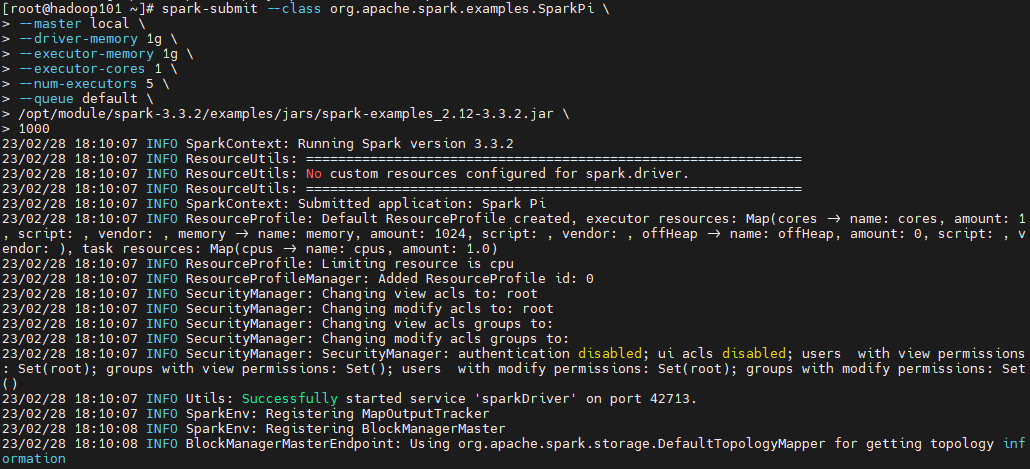
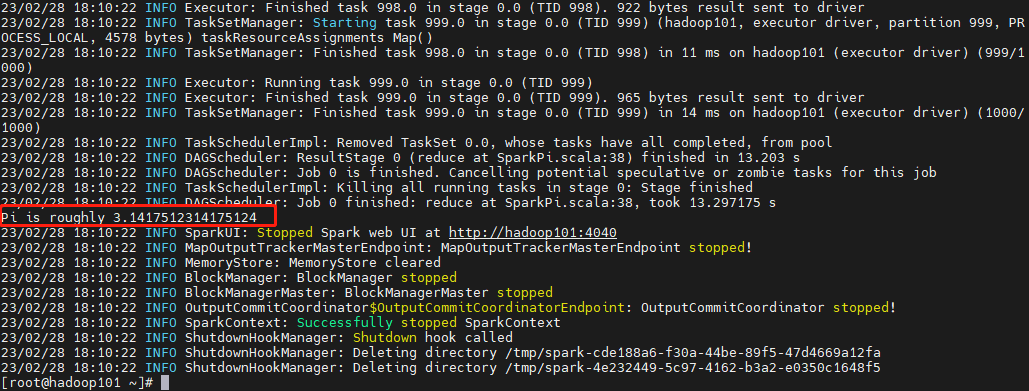

5、yarn 模式部署
执行下面步骤的前提依赖是已经执行下面公众号里面的内容:
即已经按照上述文档完成原生spark 部署
5.1、修改hadoop配置文件
修改 hadoop 配置文件/opt/module/hadoop-3.3.3/etc/hadoop/yarn-site.xml
cd /opt/module/hadoop-3.3.3/etc/hadoop/vim yarn-site.xml
添加内容:
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true --><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
5.2、分发yarn-site.xml
xsync yarn-site.xml
5.3、修改spark配置
修改Spark-yarn的conf/spark-env.sh,添加JAVA_HOME 和YARN_CONF_DIR 配置
cd opt/module/spark-3.3.2/conf/
#修改文件名--done 已执行
mv spark-env.sh.template spark-env.shvim spark-env.sh
#添加内容
export JAVA_HOME=/opt/module/jdk1.8.0_333 ---已添加export YARN_CONF_DIR=/opt/module/hadoop-3.3.3/etc/hadoop
5.4、重启hadoop集群
myhadoop.sh stopmyhadoop.sh start
5.5、启动spark
cd opt/module/spark-3.3.2/sbin/./stop-all.shstop-history-server.sh./start-all.shstart-history-server.sh
5.6、验证yarn
执行 4.1章节内容,验证部署是否正确。
兴趣是最好的老师,唯有热爱不可辜负!
Have fun!
少侠,请留步,欢迎点赞关注转发
