




 是新朋友吗?记得点击下面名片,关注我哦
是新朋友吗?记得点击下面名片,关注我哦

1、准备
1.1、下载并安装jdk
下载地址:
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
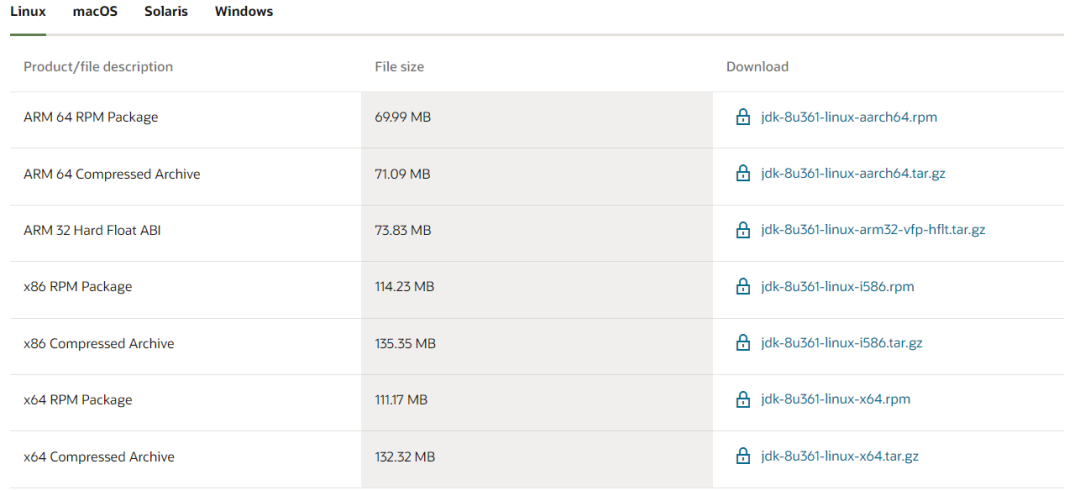
下载匹配操作系统和架构的jdk,安装jdk ,网上教程很多,不再赘述。
本例下载版本是:jdk-8u333-linux-x64.tar.gz
JAVA_HOME=/opt/module/jdk1.8.0_333


1.2、下载并安装hadoop集群
下载地址:
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
本例下载版本是:hadoop-3.3.3.tar.gz
部署手册参考往期微信公众号,如下:

1.3、下载spark
下载地址:
https://spark.apache.org/downloads.html
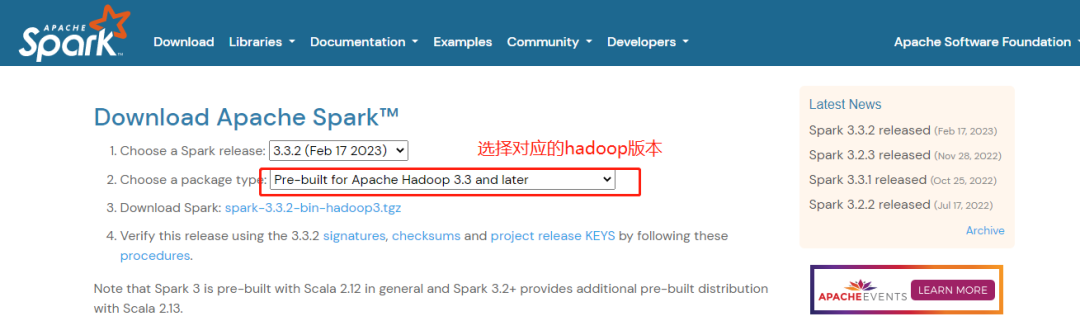
选择对应的hadoop版本后,然后下载对应版本的spark
本例下载版本是:spark-3.3.2-bin-hadoop3.tgz

2、部署spark
2.0、前置工作检查
前置条件check:
> jdk部署----done
> 主机名配置----done
> 免密码登陆配置----done
> 防火墙关闭----done
2.1、解压缩spark安装包
备注:spark-3.3.2-bin-hadoop3.tgz 已上传到 opt/software/
目标安装路径为 opt/software/
cd /opt/software/tar -zxvf spark-3.3.2-bin-hadoop3.tgz -C opt/module
#扩展信息
#spark 目录介绍drwxr-xr-x 2 501 nps1900 4096 2月 11 01:40 bin--------spark操作命令drwxr-xr-x 2 501 nps1900 4096 2月 11 01:40 conf-------配置文件drwxr-xr-x 5 501 nps1900 4096 2月 11 01:40 data-------例子里面用的一些数据drwxr-xr-x 4 501 nps1900 4096 2月 11 01:40 examples---自带的例子-源码drwxr-xr-x 2 501 nps1900 20480 2月 11 01:40 jars-------jar包drwxr-xr-x 4 501 nps1900 4096 2月 11 01:40 kubernetes-rw-r--r-- 1 501 nps1900 22940 2月 11 01:40 LICENSEdrwxr-xr-x 2 501 nps1900 4096 2月 11 01:40 licenses-rw-r--r-- 1 501 nps1900 57842 2月 11 01:40 NOTICEdrwxr-xr-x 9 501 nps1900 4096 2月 11 01:40 pythondrwxr-xr-x 3 501 nps1900 4096 2月 11 01:40 R-rw-r--r-- 1 501 nps1900 4461 2月 11 01:40 README.md----spark说明-rw-r--r-- 1 501 nps1900 165 2月 11 01:40 RELEASEdrwxr-xr-x 2 501 nps1900 4096 2月 11 01:40 sbin--集群命令,有自带的集群环境drwxr-xr-x 2 501 nps1900 4096 2月 11 01:40 yarn--spark-yarn配置
2.2、重命名Spark文件夹
备注:为后续使用方便,重命名spark文件夹
cd /opt/module/mv spark-3.3.2-bin-hadoop3/ spark-3.3.2
备注: 若启动报权限问题,或文件找不到之类的 ,发现文件夹权限低于755,尝试执行下面命令 :
chmod -R 755 opt/module/spark-3.3.2
2.3、配置spark集群
2.3.1、配置spark-env.sh
进入spark-3.3.2/conf 文件夹,重命名配置文件
cd opt/module/spark-3.3.2/confmv spark-env.sh.template spark-env.sh
修改配置文件 spark-env.sh ,如下:
vi spark-env.shexport JAVA_HOME=/opt/module/jdk1.8.0_333export SPARK_MASTER_HOST=hadoop101export SPARK_MASTER_PORT=7077
备注:以上信息按照实际情况配置。
2.3.2、配置workers
进入spark-3.3.2/conf 文件夹,重命名配置文件
cd opt/module/spark-3.3.2/confmv workers.template workers
vi workers# 添加上从服务器节点信息:hadoop102hadoop103
#扩展信息
#spark-3.3.2版本conf文件夹,有workers,没有slaves

#低版本spark,例如2.4.0版本conf文件夹,有slaves,没有workers
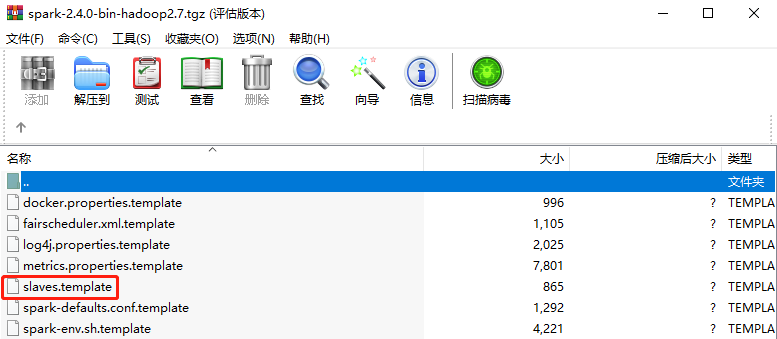
在低版本spark部署需要配置slaves文件---conf文件夹下面没有workers.templatecd /opt/module/spark-3.3.2/confmv slaves.template slavesvi slaves添加上从服务器节点信息:hadoop102hadoop103
2.4 分发spark安装包
#在hadoop101节点执行
cd opt/modulescp -r spark-3.3.2/ hadoop102:/opt/modulescp -r spark-3.3.2/ hadoop103:/opt/module
2.5、配置环境变量
#修改配置文件
vi etc/profile
#根据实际情况添加spark相关配置信息
export SPARK_HOME=/opt/module/spark-3.3.2export PATH=$PATH:$SPARK_HOME/binexport PATH=$PATH:$SPARK_HOME/sbin
#声明环境变量
source etc/profile
2.6、启停spark
2.6.1、启动spark
#启动主节点start-master.sh#启动从节点start-slaves.sh#启动shellspark-shell
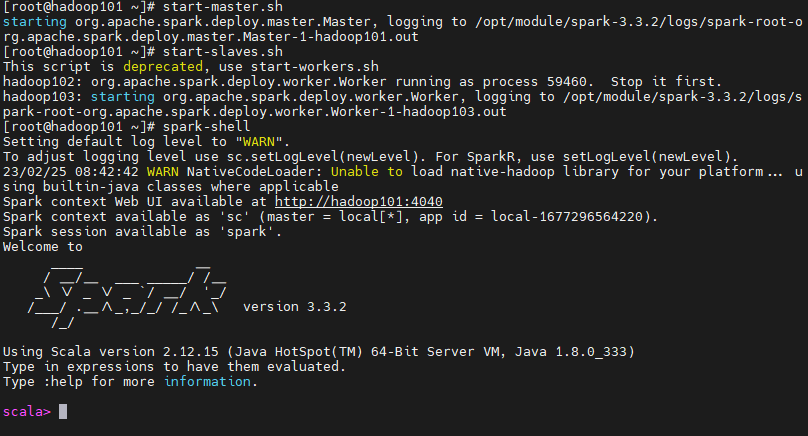
#验证
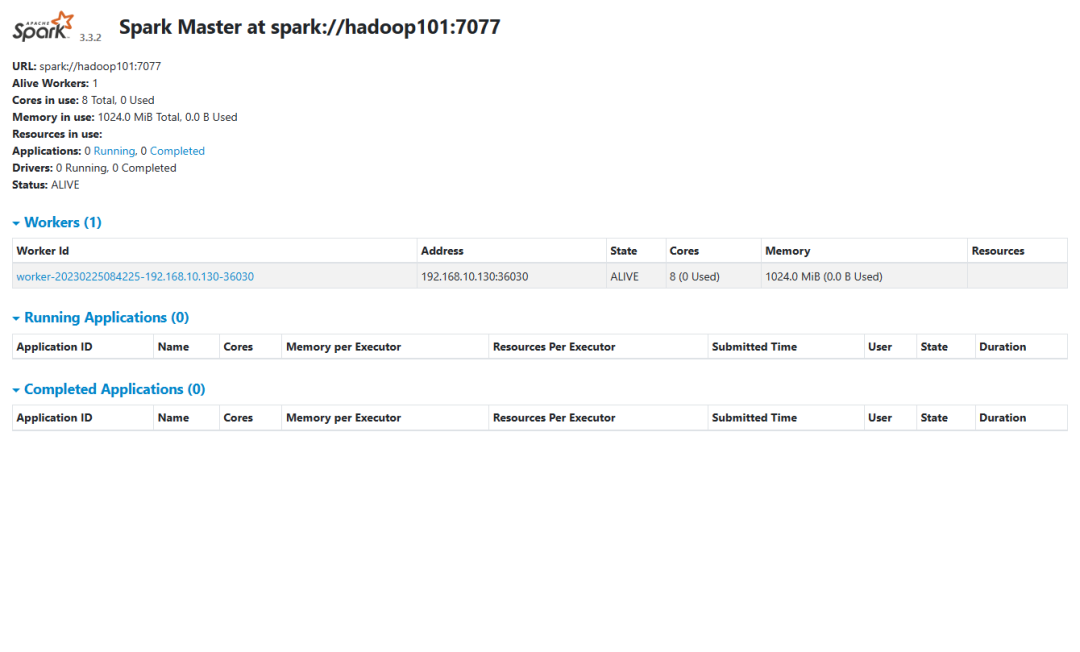
通过web端查看
http://hadoop101:8080/
如下图:
2.6.2、关闭spark
#关闭主节点stop-master.sh#关闭从节点top-slaves.sh

3、spark可用性验证
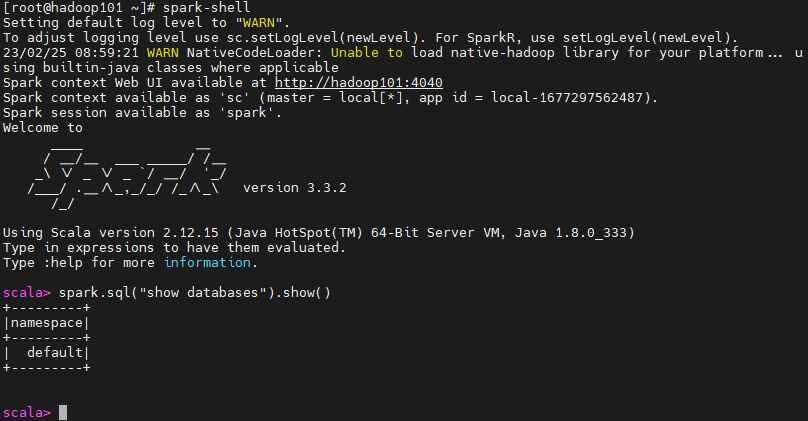
3.1、spark-shell
spark-shellspark.sql("show databases").show()退出:ctrl+c
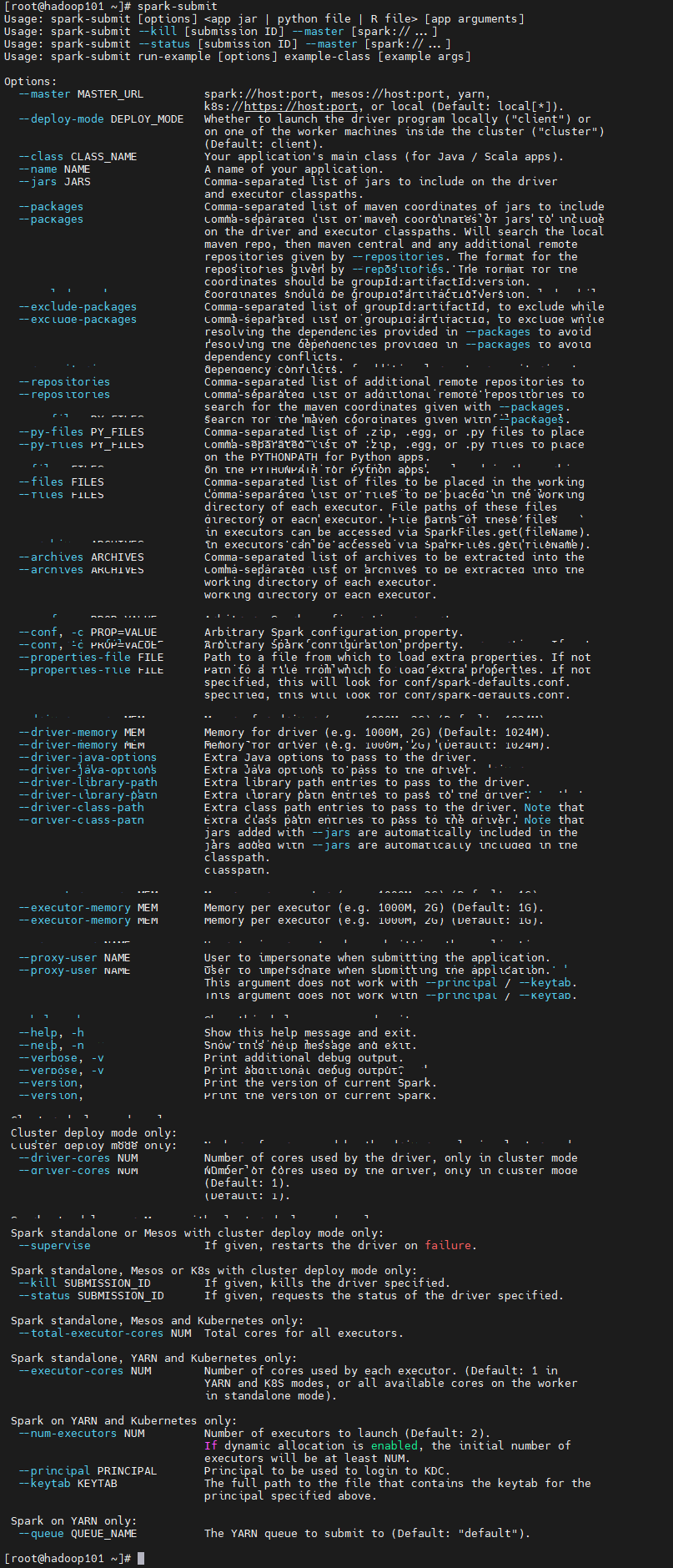
3.2、spark-submit
spark-submit
兴趣是最好的老师,唯有热爱不可辜负!
Have fun!
少侠,请留步,欢迎点赞关注转发
