




全文链接:http://tecdat.cn/?p=32007
本文以iris数据和模拟数据为例,帮助客户了比较R语言Kmeans聚类算法、PAM聚类算法、 DBSCAN聚类算法、 AGNES聚类算法、 FDP聚类算法、 PSO粒子群聚类算法在 iris数据结果可视化分析中的优缺点(点击文末“阅读原文”获取完整代码数据)。
相关视频
结果:聚类算法的聚类结果在直观上无明显差异,但在应用上有不同的侧重点。在 研究中,不能仅仅依靠传统的统计方法来进行聚类分析,而应该采用多种数据挖掘手段相结合,综合利用各种方法的优势,分析不同的数据集,从中找到适合自己研究需要的聚类分析方法。
查看数据
head(y)
## y 1 y 2 y 3 y 4 y 5 y 6 y 7
## [1,] 2.386422 1.528006 2.013216 1.522790 2.530115 2.127977 2.654109
## [2,] 1.740713 2.013977 2.322683 1.956941 1.799946 2.298104 2.146921
## [3,] 2.072196 2.129213 2.087725 2.146289 2.213800 2.459264 2.319424
## [4,] 2.418096 1.852121 1.668246 2.418176 2.513029 2.048056 1.996828
## [5,] 1.485875 2.072700 1.921772 1.645422 1.655471 1.840675 2.368683
## [6,] 2.111412 1.868223 2.022289 2.310057 1.716986 2.031257 2.069675
## y 8 y 9 y 10
## [1,] 1.964454 2.050723 1.755493
## [2,] 2.255674 1.836552 2.432906
## [3,] 1.859537 1.527330 2.227598
## [4,] 1.460083 2.033105 1.743962
## [5,] 2.364364 2.123679 1.741008
## [6,] 2.211410 2.073793 1.424886
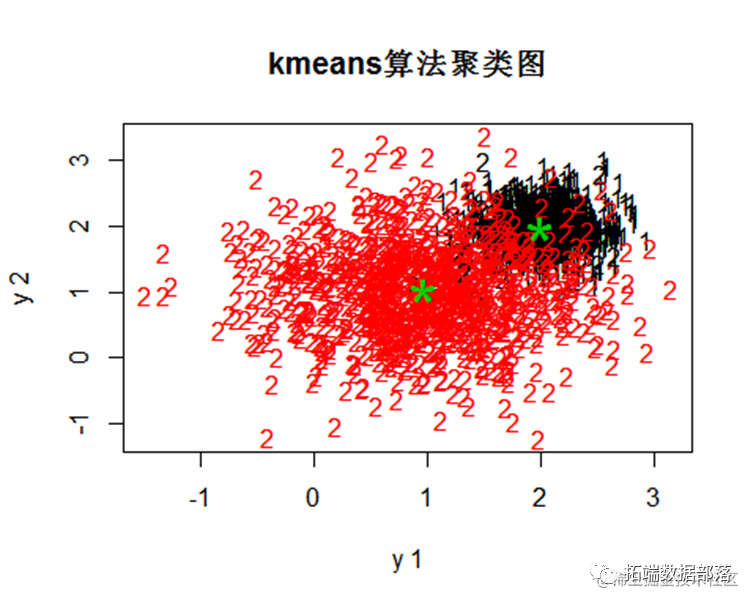
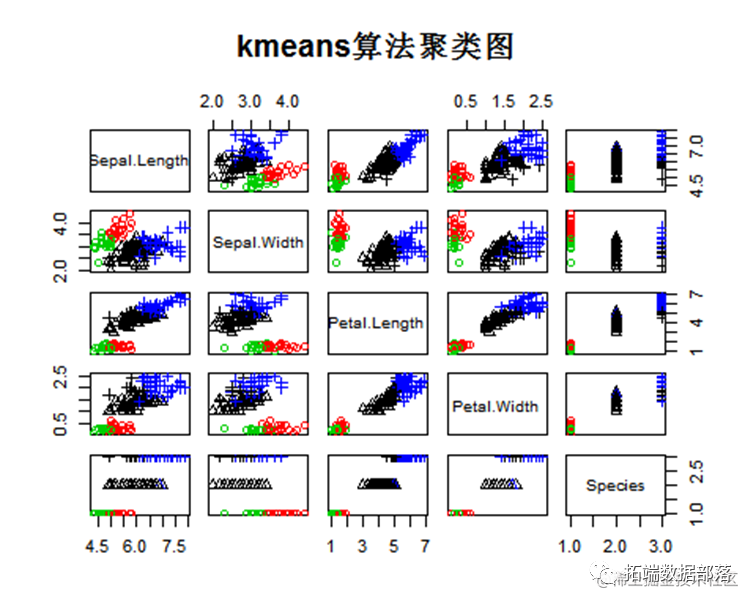
Kmeans算法聚类
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是,预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类数为2,将数据聚成2个类别:
查看模型结果
summary(cl)
## Length Class Mode
## cluster 2000 -none- numeric
## centers 20 -none- numeric
## totss 1 -none- numeric
## withinss 2 -none- numeric
## tot.withinss 1 -none- numeric
## betweenss 1 -none- numeric
## size 2 -none- numeric
## iter 1 -none- numeric
## ifault 1 -none- numeric
pch1=rep("1",1000)#类标号
pch2=rep("2",1000)
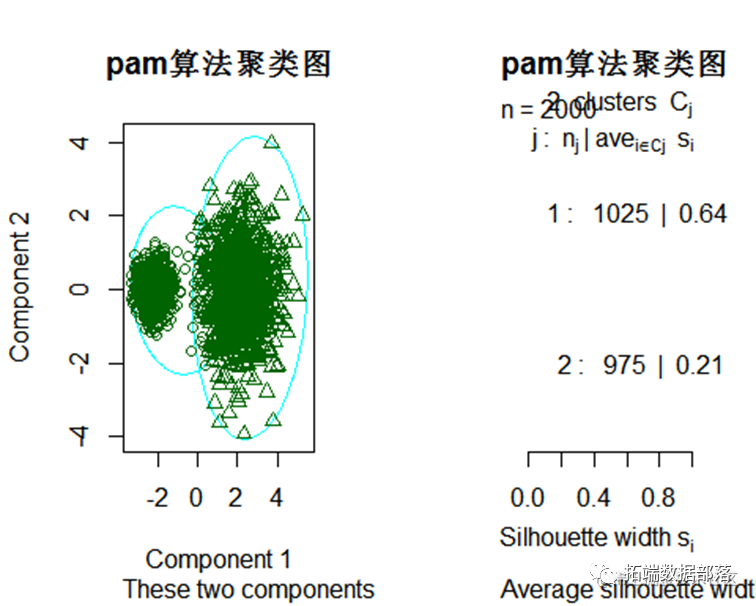
PAM算法聚类
pam聚类算法 PAM (Partitioning Around Medoids) 聚类算法属于基于质心的聚类算法,它是K-Medoids算法的一种变体。
点击标题查阅往期内容


左右滑动查看更多
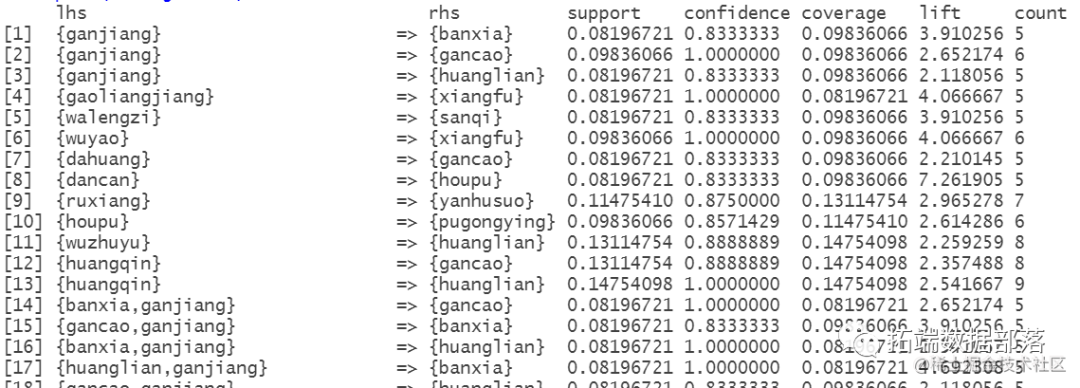
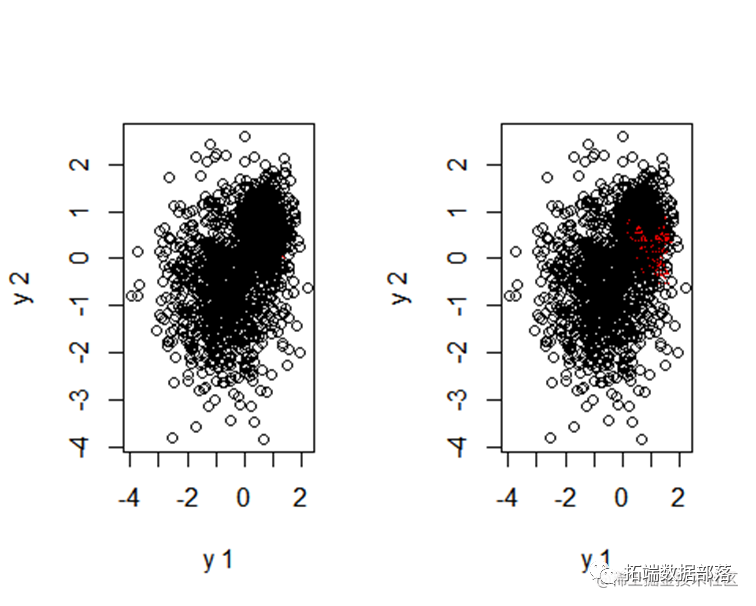
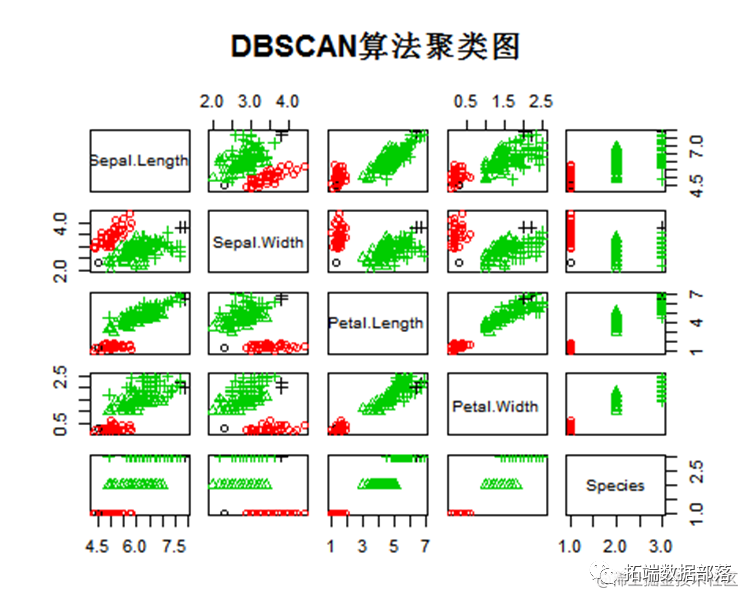
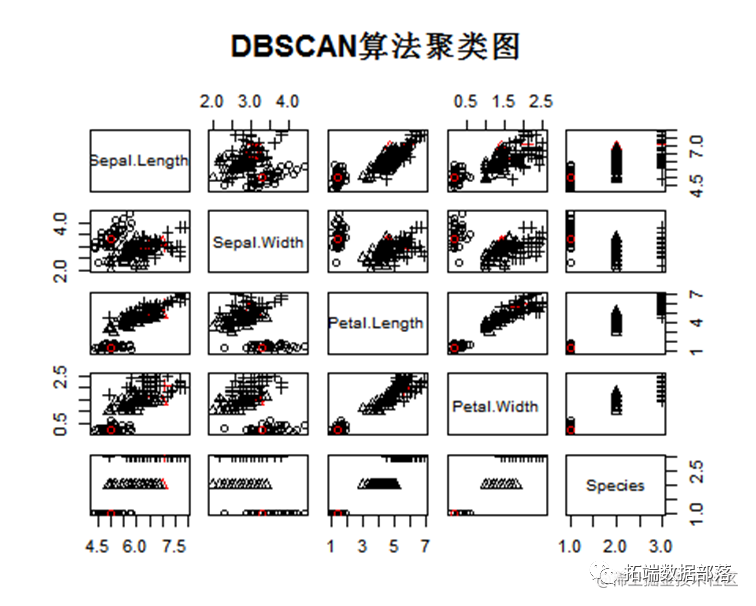
DBSCAN算法聚类
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法。
ds<-dbscan(y
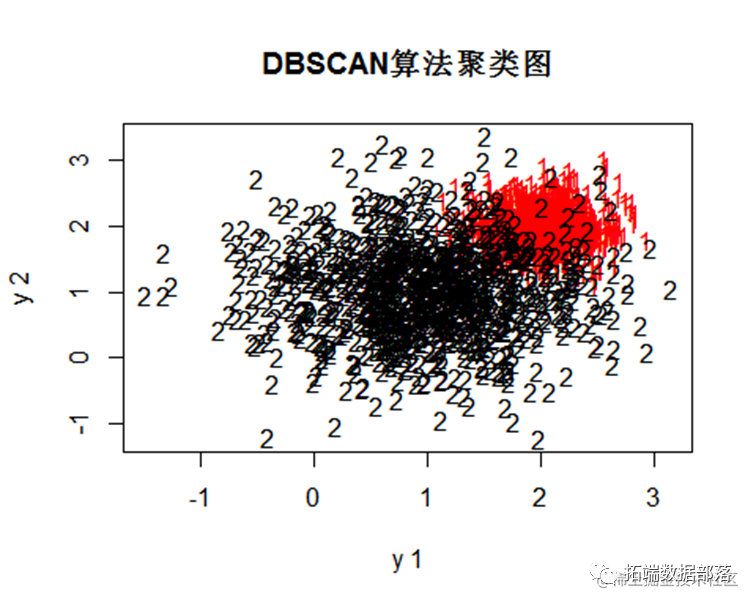
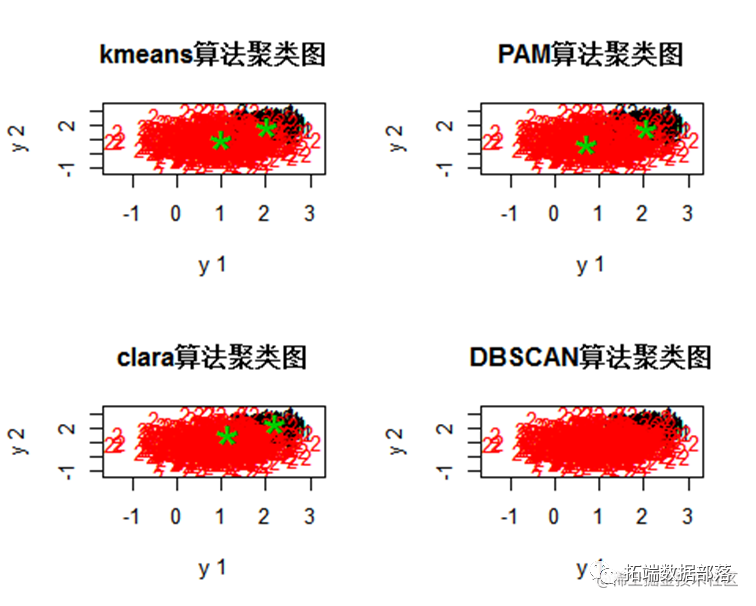
其中黑色的2代表分类错误的第2个类别,因此可以看到该数据集中dbscan的分类结果最好。
iris数据
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据样本,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
#查看数据
head(y)
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa

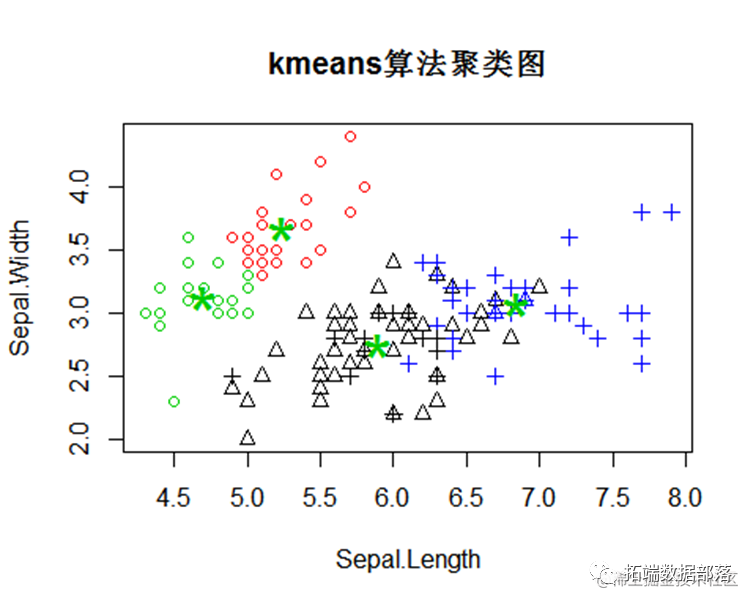
Kmeans算法聚类
聚类数为3,将数据聚成3个类别
plot(y[,1:2],col= (cl$cluster
DBSCAN算法聚类
ds<-dbscan(y[,1:4]
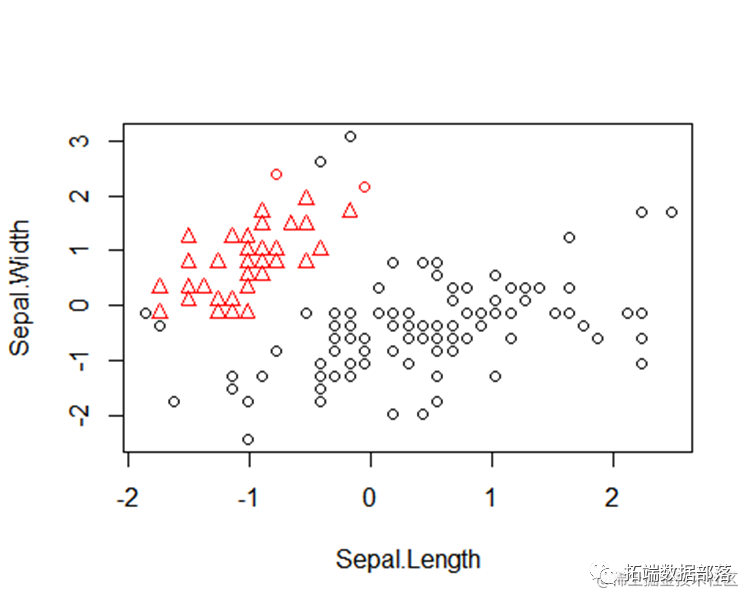
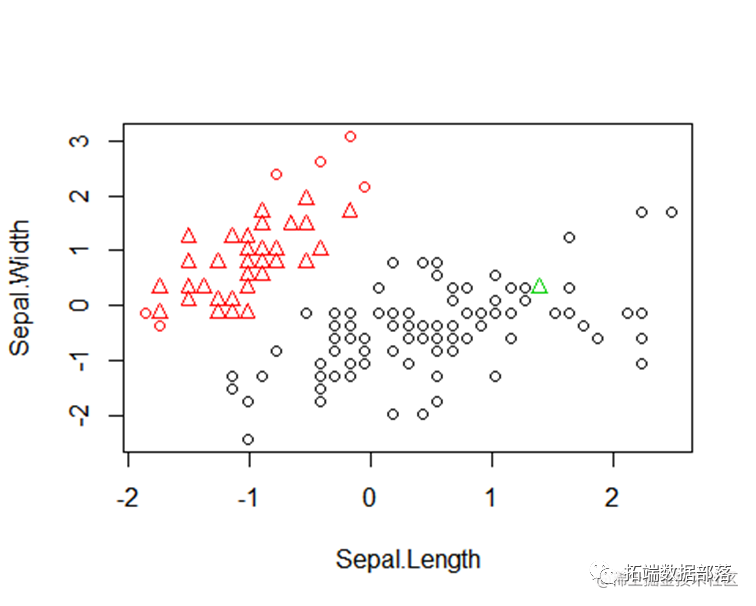
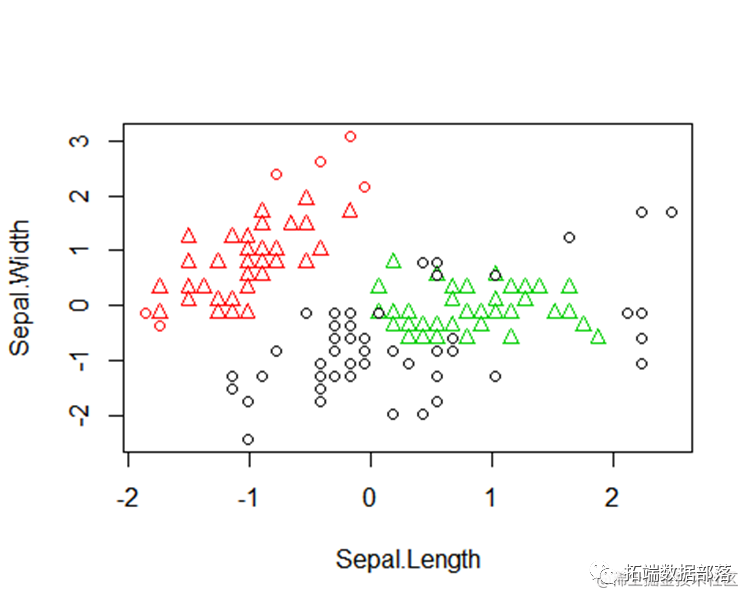
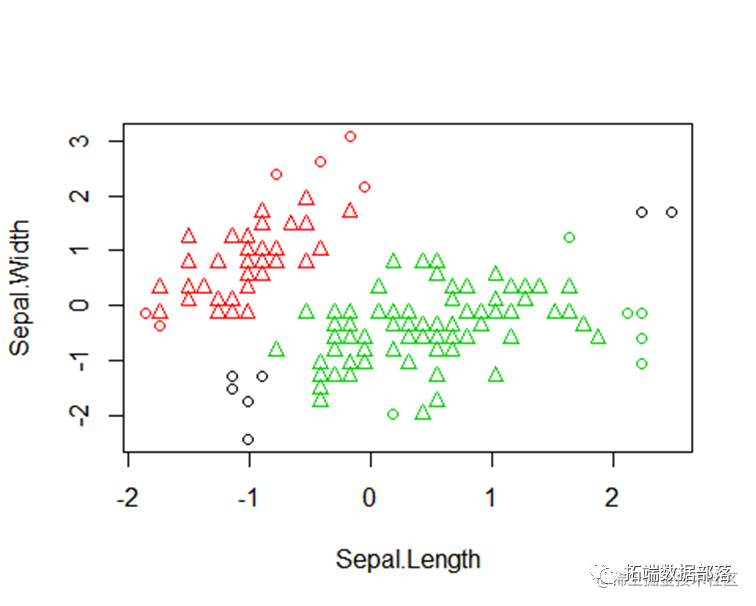
结果比较图
plot(y,col=cl$cluste
AGNES算法
“算法是凝聚的层次聚类方法。AGNES最初将每个对象作为一个簇,然后这些簇根据某些准则被一步一步地合并。例如,在簇A中的一个对象和簇B中的一个对象之间的距离是所有属于不同簇的对象之间最小的,AB可能被合并。
agn1 <- agnes(votes
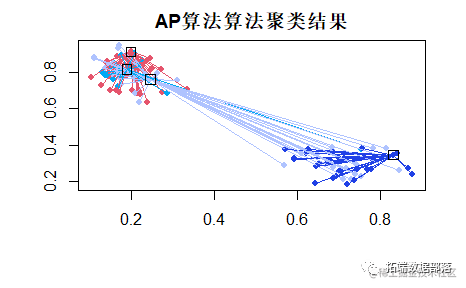
pres <- apcluster(neg
## create two Gaussian clouds
## APResult object
##
## Number of samples = 150
## Number of iterations = 138
## Input preference = -31.0249
## Sum of similarities = -45.0528
## Sum of preferences = -124.0996
## Net similarity = -169.1524
## Number of clusters = 4
##
## Exemplars:
## 8 64 81 103
## Clusters:
## Cluster 1, exemplar 8:
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
## 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49
## 50
## Cluster 2, exemplar 64:
## 51 52 53 55 56 57 59 62 64 66 67 69 71 72 73 74 75 76 77 78 79 84 85

plot(apres, x)
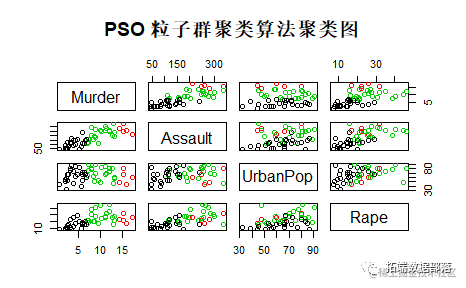
PSO 粒子群聚类算法
“PSO是粒子群优化算法(——Particle Swarm Optimization)的英文缩写,是一种基于种群的随机优化技术,由Eberhart和Kennedy于1995年提出。粒子群算法模仿昆虫、兽群、鸟群和鱼群等的群集行为,这些群体按照一种合作的方式寻找食物,群体中的每个成员通过学习它自身的经验和其他成员的经验来不断改变其搜索模式。
myPSO <- function(x, k, w) {
#创建随机质心
centroid_acak <- sample(c(1:length(x[,1])), k, replace = FALSE)
centroid <- x[centroid_acak,1:length(x)]
#计算欧几里得距离
hitung_jarak <- function(x){
sqrt(
for(i in 1:length(x)) {
euclidean <- ((x[i] - centro
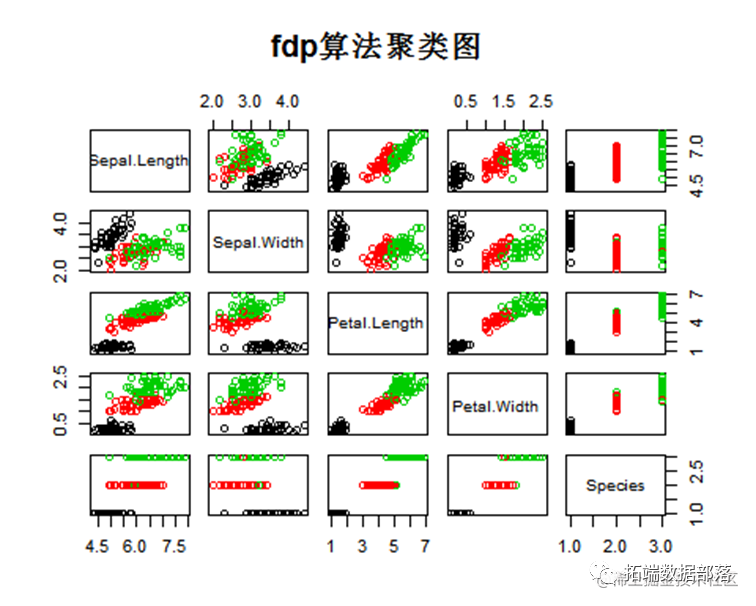
FDP 聚类算法
针对密度峰值算法 FDP在找到聚类中心后,分配其余数据时存在的漏洞,提出了基于密度聚类算法 DBSCAN的改进方法。具体做法是求出聚类中心后利用DBSCAN 算法将其余数据分配到正确的类别中,保证了在分配其余数据时考虑到数据和数据之间的关联性,而不是直接简单的将所有数据分配到离得最近的那个中心所在的类别中。所提算法和原始FDP算法相比,可处理非凸数据、能得到更好的聚类结果。
fdp<-function(X,G,p=rep(FALSE){
if(is.null(TstX)==TRUE) TstX<-X
n<-nrow(TstX)
belong<-matrix(
plot(iris,col=cl

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言Kmeans聚类、PAM、DBSCAN、AGNES、FDP、PSO粒子群聚类分析iris数据结果可视化比较》。
点击标题查阅往期内容



