




全文链接:http://tecdat.cn/?p=31233
随着互联网的普及和移动端的应用的飞速发展,消费者在各大电商平台进行活动交易时产生了大量的行为数据,在线评论文本就是其中一种(点击文末“阅读原文”获取完整数据)。
去年,我们为一位客户进行了短暂的咨询工作,他正在构建一个主要基于酒店评论数据的文本分析应用程序。在线评论文本是消费者对消费对象切身体验后以文本的形式反馈至电商平台,被作为大众的舆论观点导向。对此类观点进行有效情感分类不仅可以帮助消费者进行决策,还可以帮助商家对服务进行改善。
本文分析的数据是从某酒店预定网站获取到的评论数据。通过对评论数据的分析,得到影响好差酒店的关键影响因素,并建立模型预测评论所对应的等级。在众多文本中筛选人们评论的关键因素因为存在情感倾向,中文表达的多样,隐性表达使得提取关键影响因素称为本项目的一大挑战。另一个挑战是评分预测,由于数据的不规则,对于模型的选取又是一大难点。
任务/目标
l 根据给定评价(review),预测评分(rating)
l 提取“好”,“差”酒店的关键影响因素
分析思路:
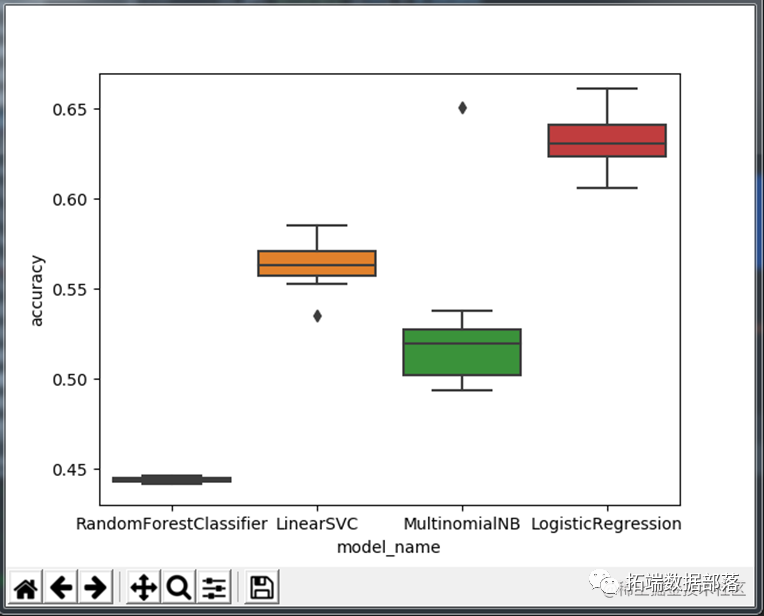
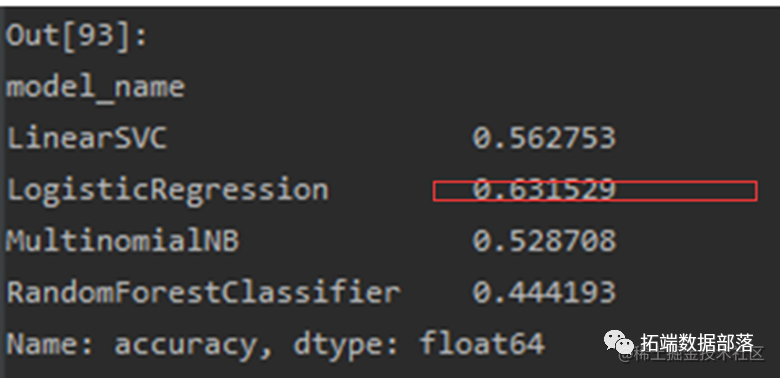
对于问题一,需要根据给定评价预测评分,由于每一条评论都有1~5五种评分方式,因此属于文本多分类问题,文本分类的算法很多,有机器学习方面的也有深度学习方面的,在这里我们尝试了朴素贝叶斯、逻辑回归,支持向量机(SVM)、K最邻近算法(KNN)、随机森林等多分类算法,并进行了相关比较。本次分类任务的最大特点是我们处理的是英文的文本,为此我们使用了经典的tf-idf模型进行特征提取,对train_data进行初步简单的划分,并训练后发现预测准确率都不高。随后我们从数据预处理、调参以及数据划分和训练及预测方法上做了优化处理,具体来说,就是数据预处理时充分考虑了英文文本自身的特点,调参时用到了控制变量法和交叉检验法,同时在训练集与测试集划分和紧接着的训练与预测上也用的是交叉检验法。最后对我们的Testing data.csv 文件进行预测时,我们是选取了准确率最高的模型和我们自己调试的相应参数。
对于问题二,提取“好”,“差”酒店的关键影响因素,所研究的情感分类是二分类(正面情感和负面情感)的,给定文本已经有了评分标签,故可以通过评分标签对文本进行分类,由于3分的评论情感倾向不明确,影响分类的准确性,为了得到更好的结果,剔除3分的评论数据,将评分为1-2的差评数据和评分为4-5的好评数据进行训练,并根据TF-IDF算法提取关键词绘制词云图。根据词云图可以初步确定好评和差评的关键因素。但是由于用户表达的情感倾向和其使用的关键词存在反向否定的情况,为了进一步捕捉用户的情感倾向,使用具有潜在狄氏分配的主题模型对所有评论数据建模,每一条评论,可视为一个主题,评论文本共19003条,对所有文本进行主题建模,设置主题参数为2,得到两个主题的按升序排列的单词重要性矩阵,显示前60个主题关键词,得到结果
如下训练样本(只列举部分特征)。

评分预测建模
1. 朴素贝叶斯模型
贝叶斯方法以贝叶斯原理为基础,在先验概率的基础上将数据集归为n个标签中后验概率最大的标签(基于最小错误率贝叶斯决策原则),其特点是结合先验概率和后验概率,避免了只使用先验概率的主观偏见,也避免了单独使用样本信息的过拟合现象。本次实验中贝叶斯算法训练速度最快,准确度较高。
2. 随机森林
随机森林是一种集成算法(Ensemble Learning),它属于Bagging类型,通过组合多个弱分类器,最终结果通过投票或取均值,使得整体模型的结果具有较高的精确度和泛化性能。其可以取得不错成绩,主要归功于“随机”和“森林”,一个使它具有抗过拟合能力,一个使它更加精准。在本次实验中其预测准确率较低,训练速度较慢。
3. 逻辑回归
逻辑回归的思想就是 在线性回归上再做一次函数转换,对线性回归的结果做一个在函数上的转换,变化为逻辑回归。这个函数一般取为sigmoid函数,经常用来解决二分类问题,也可以解决多分类问题,主要有两种实现策略,一种是为每个类别创建一个sigmod分类器,再进行整合,另一种是就用一个digmod分类器,同时基于softmax思想为每个类别分配一个概率(所有类别的概率和为1)来训练模型,实现分类。本次实验中使用这种方法取得了最高的预测准确率
4. 支持向量机(SVM)
支持向量机的目的在于求得最优的即几何间隔最大的超平面,在样本数据是线性可分的时候,这里的间隔最大化又叫硬间隔最大化(训练数据近似可分的话就叫软间隔)
实验发现其训练速度较慢,准确度一般。
模型优化
交叉检验是在机器学习建立模型和验证模型参数时常用的办法。交叉验证,顾名思义,就是重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏。在此基础上可以得到多组不同的训练集和测试集,某次训练集中的某样本在下次可能成为测试集中的样本,即所谓“交叉”。
根据切分的方法不同,交叉验证分为下面三种:
第一种是简单交叉验证,所谓的简单,是和其他交叉验证方法相对而言的。首先,我们随机的将样本数据分为两部分(比如:70%的训练集,30%的测试集),然后用训练集来训练模型,在测试集上验证模型及参数。接着,我们再把样本打乱,重新选择训练集和测试集,继续训练数据和检验模型。最后我们选择损失函数评估最优的模型和参数。
第二种是S折交叉验证(S-Folder Cross Validation)。和第一种方法不同,S折交叉验证会把样本数据随机的分成S份,每次随机的选择S-1份作为训练集,剩下的1份做测试集。当这一轮完成后,重新随机选择S-1份来训练数据。若干轮(小于S)之后,选择损失函数评估最优的模型和参数。
第三种是留一交叉验证(Leave-one-out Cross Validation),它是第二种情况的特例,此时S等于样本数N,这样对于N个样本,每次选择N-1个样本来训练数据,留一个样本来验证模型预测的好坏。此方法主要用于样本量非常少的情况,比如对于普通适中问题,N小于50时,一般采用留一交叉验证。
本次实验采用简单交叉进行验证
关键词提取建模
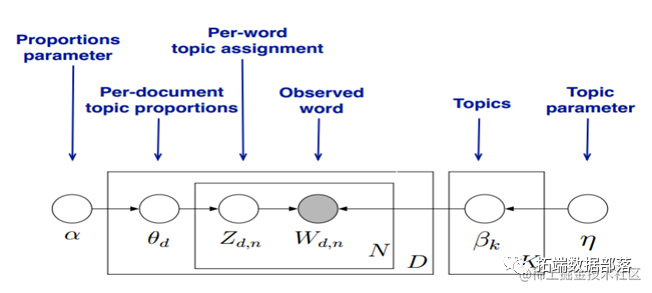
LDA模型:LDA即LatentDirichletAllocation(隐含狄利克雷分布),是由Blei于2003年提出的三层贝3叶斯主题模型,通过无监督的学习方法发现文本中隐含的主题信息,LDA是一种概率生成模型,试图找出几个常出现在不同文档中的单词。假设每个单词都是由不同文档组成的混合体,那么经常出现的单词就代表主题。LDA 的输入是词袋模型,LDA把词袋矩阵作为输入然后分解成两个新矩阵:1.文档主题矩阵2.单词主题矩阵
模型图如下:
使用各种模型的正确率图示:
点击标题查阅往期内容


左右滑动查看更多

问题二结果图:
分别对评分为1-3分和评论与评分为4-5分的评论制作词云图如下:
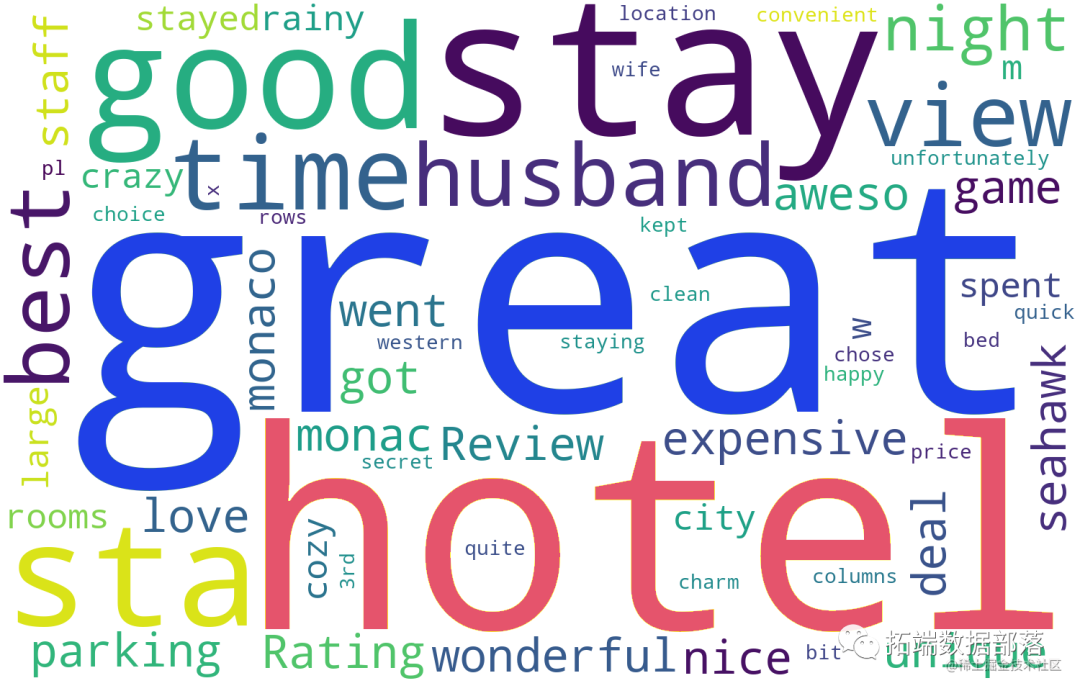
<评分4~5分词云图>
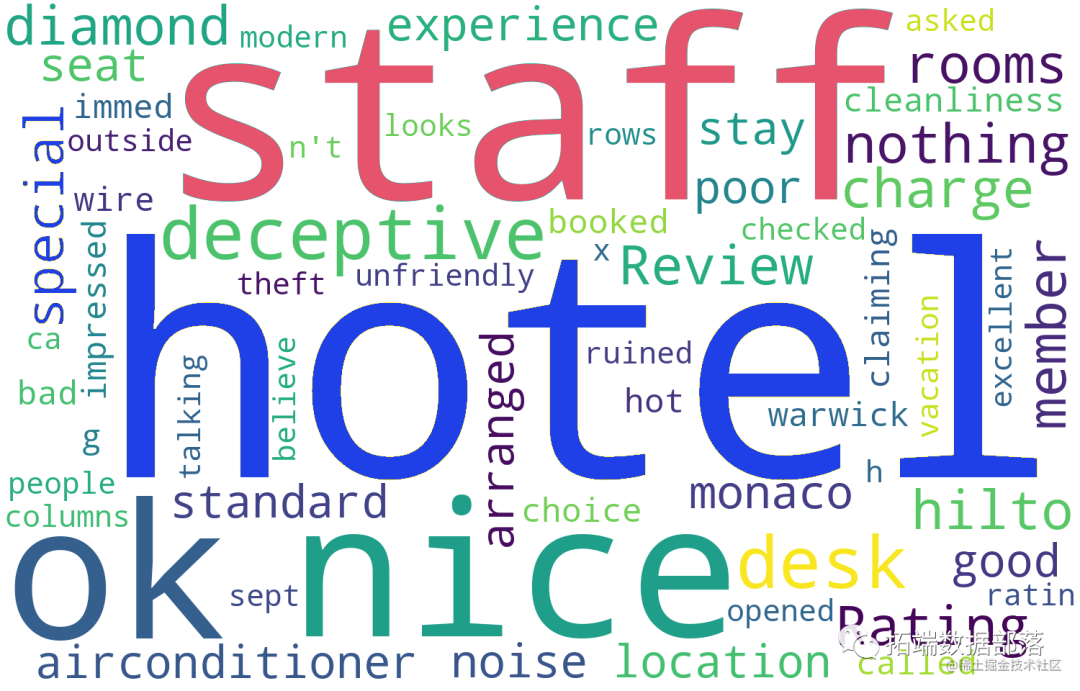
<评分1~3分词云图>
发现在低分的评论词云图中出现了正向情感词,因为3分的评论对于“好”“差”的倾向度不高,因此选择了45分的评论和12分的评论分别绘制词云图,结果如下
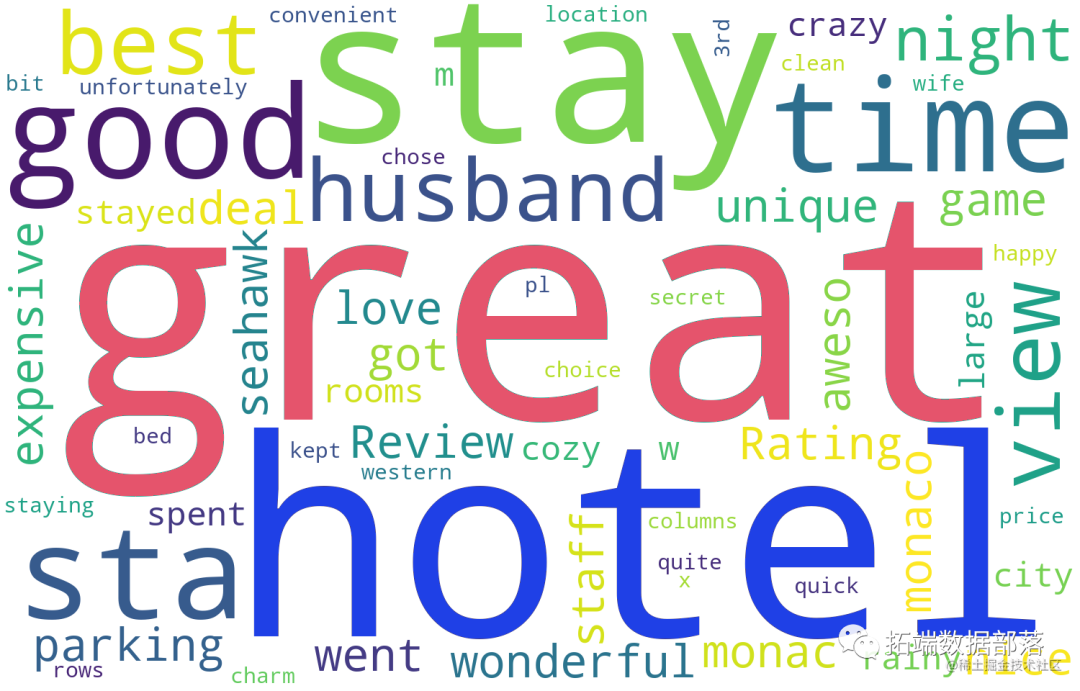
<评分为4~5分词云图>
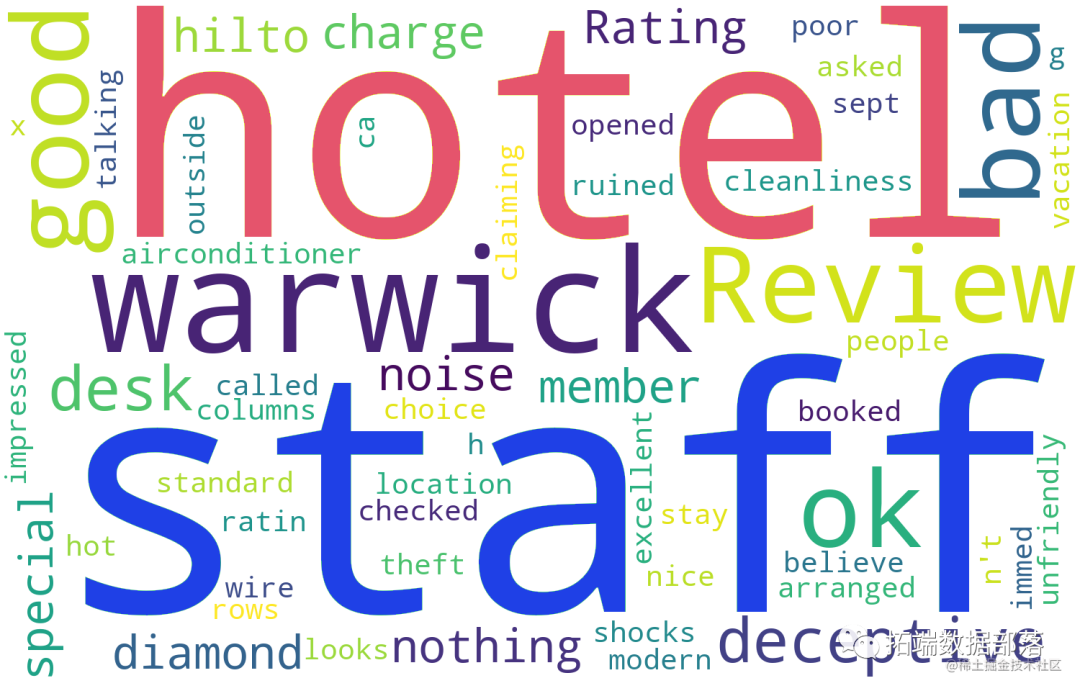
<评分为1~2分词云图>
为了得到更强的区分度,分别对评分为5分的评论集和1分的评论集绘制词云,得到如下结果
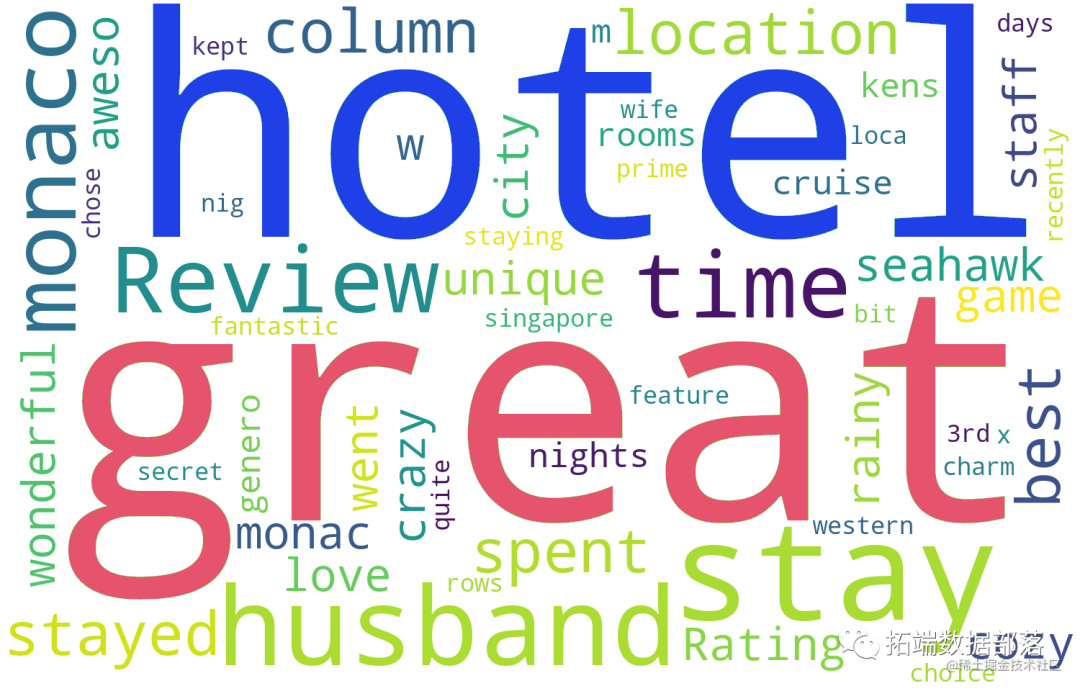
<评分为5分词云图>
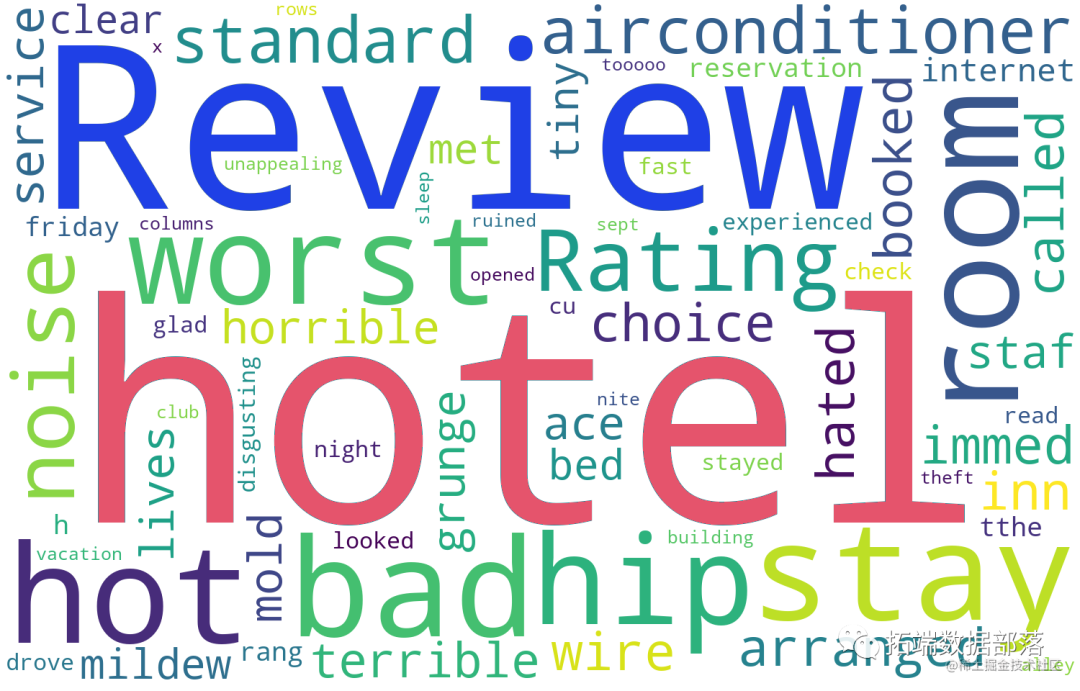
<评分为1分词云图>
从上述结果可以直观的看到,剔除描述情感倾向的词汇
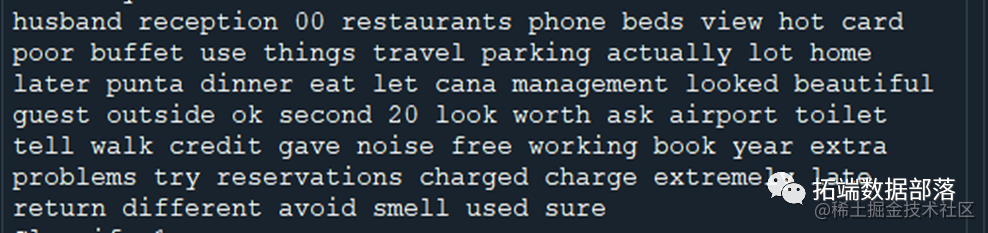
好酒店的关键影响因素:uinique parking staying convenient location clean large quick seahawk time monaco cruise spent
差酒店的关键影响因素:staff airconditioner charge theft looked building tiny unfriendly outside cleanliness wire ruined talking booked/reservation noise internet
为了得到更准确的结果,使用LDA进行情感主题分类,得到量化结果如下:
好酒店的关键影响因素

差酒店的关键影响因素
关于作者
在此对Yuanyuan Zhang对本文所作的贡献表示诚挚感谢,她擅长深度学习、数理金融。
数据获取
在公众号后台回复“酒店评论数据”,可免费获取完整数据。

本文中分析的数据分享到会员群,扫描下面二维码即可加群!

点击文末“阅读原文”
获取全文完整数据资料。
本文选自《Python酒店评论文本数据分析:tf-idf、贝叶斯、逻辑回归,支持向量机SVM、K最邻近算法KNN、随机森林、LDA主题模型》。
点击标题查阅往期内容



