




原文链接:http://tecdat.cn/?p=18169
比如说分类变量为是否幸存、是因变量,连续变量为年龄、是自变量,这两者可以做相关分析吗(点击文末“阅读原文”获取完整代码数据)。
相关视频
两者又是否可以做回归分析?
我们考虑泰坦尼克号数据集,
titanic = titanic[!is.na(titanic$Age),]
attach(titanic)
考虑两个变量,年龄x(连续变量)和幸存者指标y(分类变量)
X = Age
Y = Survived
年龄可能是逻辑回归中的有效解释变量,
summary(glm(Survived~Age,data=titanic,family=binomial))
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.05672 0.17358 -0.327 0.7438
Age -0.01096 0.00533 -2.057 0.0397 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 964.52 on 713 degrees of freedom
Residual deviance: 960.23 on 712 degrees of freedom
AIC: 964.23
此处的显着性检验的p值略低于4%。实际上,可以将其与偏差值(零偏差和残差)相关联。
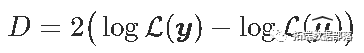
而
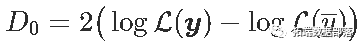
点击标题查阅往期内容


左右滑动查看更多
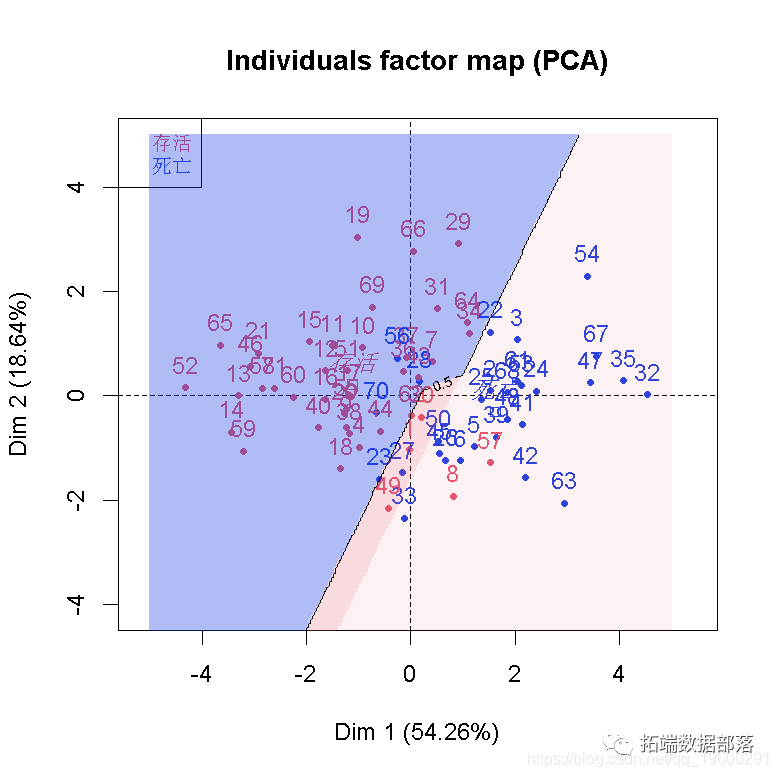
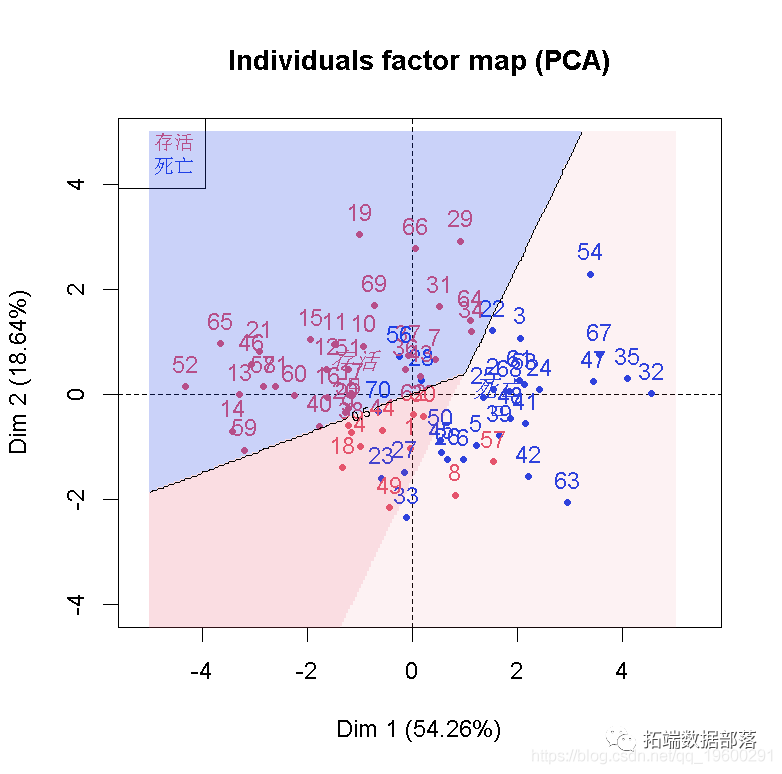
在x毫无价值的假设下,D_0趋于具有1个自由度的χ2分布。我们可以计算似然比检验的p值自由度,
1-pchisq(
[1] 0.03833717
与高斯检验一致。但是如果我们考虑非线性变换
glm(Survived~bs(Age)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.8648 0.3460 2.500 0.012433 *
bs(Age)1 -3.6772 1.0458 -3.516 0.000438 ***
bs(Age)2 1.7430 1.1068 1.575 0.115299
bs(Age)3 -3.9251 1.4544 -2.699 0.006961 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 964.52 on 713 degrees of freedom
Residual deviance: 948.69 on 710 degrees of freedom
Age的p值更小,似乎“更重要”
[1] 0.001228712
为了可视化非零相关性,可以考虑给定y = 1时x的条件分布,并将其与给定y = 0时x的条件分布进行比较,
Two-sample Kolmogorov-Smirnov test
data: X[Y == 0] and X[Y == 1]
D = 0.088777, p-value = 0.1324
alternative hypothesis: two-sided
即p值大于10%时,两个分布没有显着差异。
v= seq(0,80
v1 = Vectorize(F1)(vx)
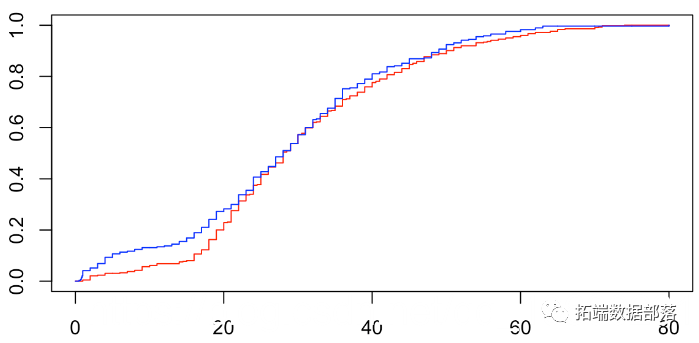
我们可以查看密度
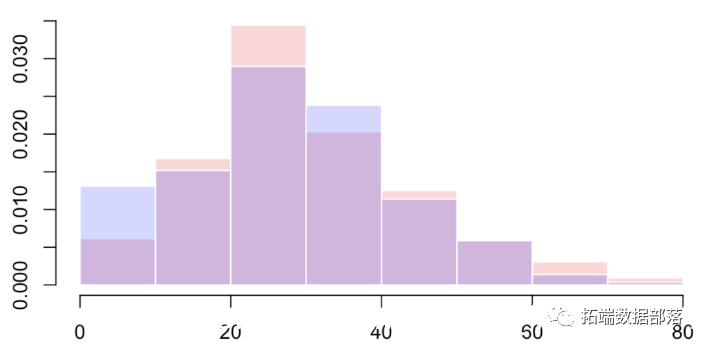
另一种方法是离散化变量x并使用Pearson的独立性检验,
table(Xc,Y)
Y
Xc 0 1
(0,19] 85 79
(19,25] 92 45
(25,31.8] 77 50
(31.8,41] 81 63
(41,80] 89 53
Pearson's Chi-squared test
data: table(Xc, Y)
X-squared = 8.6155, df = 4, p-value = 0.07146
p值在此处为7%,分为年龄的五个类别。实际上,我们可以比较p值
pvalue = function(k=5){
LV = quantile(X,(0:k)/k)
plot(k,p,type="l")
abline(h=.05,col="red",lty=2)
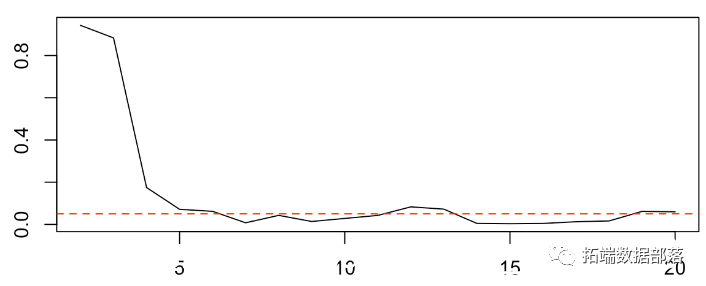
只要我们有足够的类别,P值就会接近5%。实际上年龄在试图预测乘客是否幸存时是一个重要的变量。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言逻辑回归分析连续变量和分类变量之间的“相关性“》。
点击标题查阅往期内容



文章转载自拓端数据部落,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
