




在一些经典的任务领域,有一些方法几乎达到了性能的饱和点。在这样的选题上实验无疑困难重重,难以有突破性的进展,也不太会被同行认可。对此,我已饱受其害。 例如,在 skeleton-based action recognition 领域中,一些方法在 NTU 60 数据集上的精度已经达到了 96%,提升的空间就不大了。那么,如何在这样的大环境下做科研(大神戏称水论文,在没有顶会之前姑且称之为做科研吧)?个人愚见:可能的方案就是找一条不太卷的赛道或是创造一个新赛道。例如经典的基于视频的动作识别已经非常卷了,有人提出了一个压缩视频动作识别的新赛道,在这条新赛道上做文章相对没有那么卷。
由于原始视频流规模较大,且有高冗余, 真实有趣的信号经常被无用的数据淹没。通过视频压缩(使用H.264,HEVC等)可以将多余信息减少多达两个数量级,Wu等[1]首次提出直接在压缩视频上训练深度网络并取得了不错的效果。
现代编解码器将视频分成 帧(内嵌帧)、 帧(预测帧)和0个或多个B帧(双向帧)。 帧是常规图像,因此被压缩。 帧代表前面的帧,只对“更改”进行编码。变化的一部分——称为运动矢量——表示为像素块在时间 从源帧移动到目标帧。
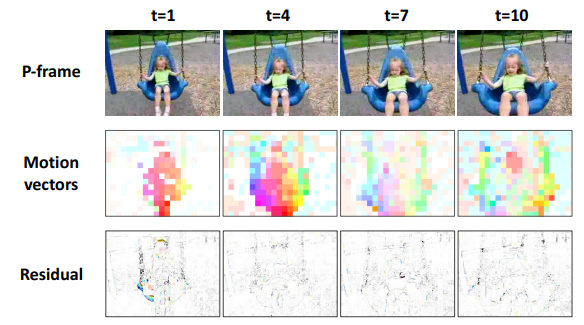
在压缩视频中,只有少部分的 帧被完全解码,大部分帧被不完全解码为 帧。然而,压缩视频动作识别这项任务严重地受到粗糙和噪声的动态信息和 RGB 和运动模式融合不足的影响。
前者是指压缩视频中记录的动态信息可能是不准确的;随着压缩视频中分辨率的降低,运动向量(motion vector)被引入噪声的影响;

后者是指为了产生具有代表性的视频级特征,现有方法在处理不同模态信息(RGB信息和运动动态信息)时的融合不充分。
为此,Li等[2]提出 MEACI-Net 来解决这两个问题。
其实,这两个问题在其它任务中也可能存在,从而提供借鉴。例如,对于骨架动作识别问题中,骨架信息本身由于姿态估计算法的不精确从而存在噪声;结合 RGB 就是多模态的方法,考虑如何有效融合也可以作为一个出发点。
首先从压缩视频中解码出 帧和 帧,分别对应 RGB 和 MVR 两种模态信息。RGB 流被送入 I3D-ResNet50 骨干网络;MVR 流被送入堆叠 MSB 网络。
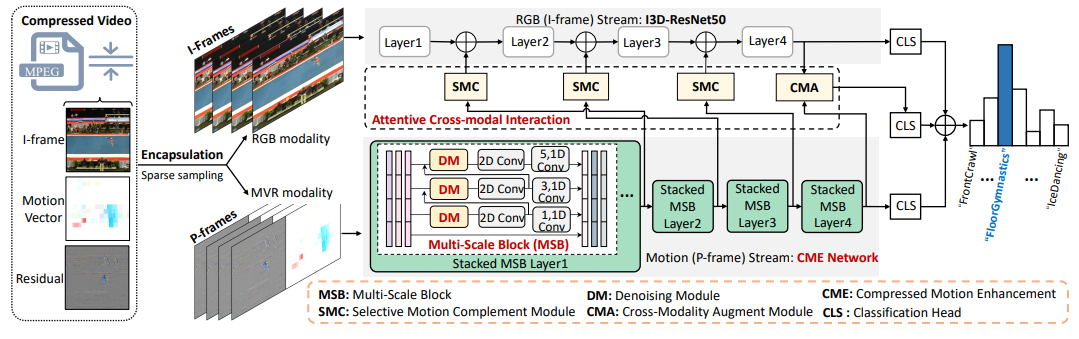
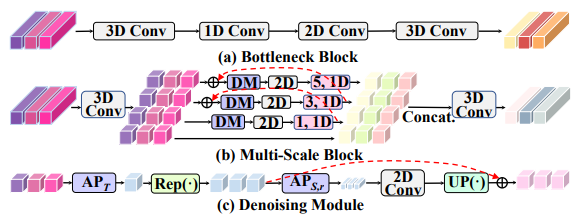
为了解决第一个问题,作者提出的 MSB 模块包括四个独立级联的分支,通过不同的内核大小(即1、3和5)捕获短期/长期动态,可以有效地提取多个空间粒度上的多尺度运动模式,而不会增加太多额外的计算成本;包含的 DM 模块利用门控机制在时间和空间上都抑制噪声。
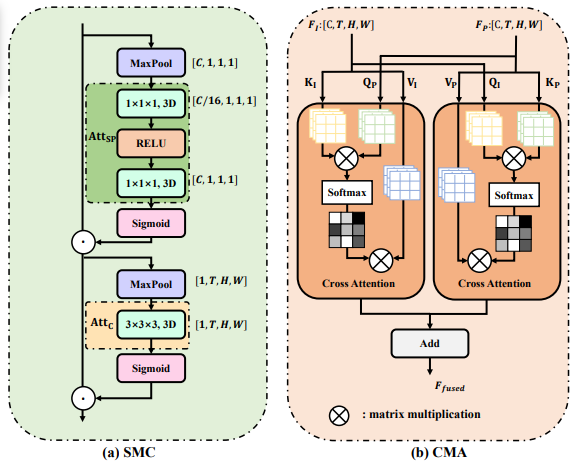
为了解决第二个问题,作者分别提出 SMC 和 CMA 用以加强两个模态之间的信息交流。SMC 通过整合来自 MVR 模态的信息运动线索,增强了 RGB 模态的表征学习。通过交叉注意聚合多模态特征,CMA 进一步构建了一个跨模态表示,作为单模态表示的扩充。从两个独立的流中提取的高级特征与 CMA 学习到的特征在分数层面进行融合,最终进行预测。
最后,要证明所提出的方法有效,还得通过实验指标来验证。
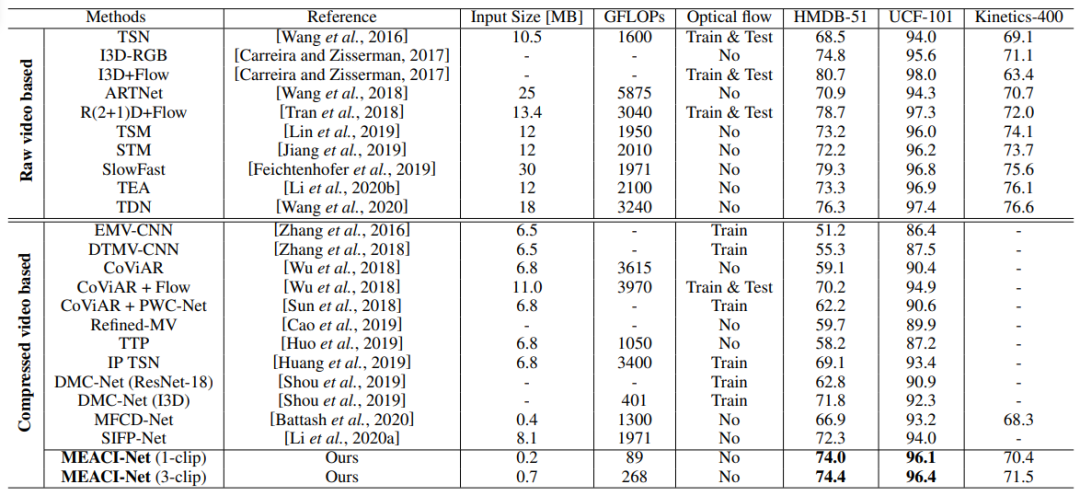
与同类方法相比,涨点在 2% 以上。这样才能更加具有说服力,效果好而且性能提升要大。
参考资料
Wu, C.Y., Zaheer, M., Hu, H., Manmatha, R., Smola, A.J. and Krähenbühl, P., 2018. Compressed video action recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 6026-6035).: https://arxiv.org/pdf/1712.00636.pdf
[2]Li, B., Chen, J., Zhang, D., Bao, X. and Huang, D., 2022. Representation Learning for Compressed Video Action Recognition via Attentive Cross-modal Interaction with Motion Enhancement. arXiv preprint arXiv:2205.03569: https://arxiv.org/pdf/2205.03569.pdf
