




最大均值差异(MMD,Maximum Mean Discrepancy)
如何描述一个随机变量?最直接的方法就是给出它的概率分布函数[1]。例如,正太分布可以由其均值(一阶原点矩)和方差(二阶中心距)确定。然而,对于同样均值和方差的高斯分布和拉普拉斯分布,均值和方差并不能完全代表其中任何一个分布,这时候我们就需要更高阶的矩来描述一个分布。在实践中,每一个随机变量的矩都告诉我们一些关于其分布的信息[2]。
核心思想 两个随机变量的任意阶都相同的话,那么两个分布就是一致的。而当两个分布不相同的话,那么使得两个分布之间差距最大的那个矩应该被用来作为度量两个分布的标准。
定义
最大均值差异(MMD)是迁移学习,尤其是域适应中使用最广泛的一种损失函数,主要用来度量两个不同但相关的随机变量的分布的距离。
差异度量 域适应的目的是将源域中学到的知识应用到不同但相关的目标域中。本质上是要找到一个映射函数,使得变换后的源域数据和目标域数据的距离最小;而MMD就是一种度量源域与目标域距离数据分布差异的标准。
其定义为:
为源域数据,其分布为
为目标域数据,其分布为
表示求上确界
和 表示求期望
表示映射函数
表示在再生希尔伯特空间中的范数应该小于等于1
利用了再生希尔伯特空间的再生性,先将向量通过一个函数 映射到希尔伯特空间,再与该空间中的一个单位球内给定的向量 作点积,完成映射到高维的变换。
和 分别表示 和 。根据内积的性质 ,且 ,则可得到最终结果。
此式的含义是寻找一个映射函数,这个映射函数能够将变量映射到高维空间,之后求两个分布的随机变量在映射后的期望的差,这个差值便是 Mean Discrepancy
,然后寻找这个 Mean Discrepancy
的上确界。这个最大值便是 MMD
。
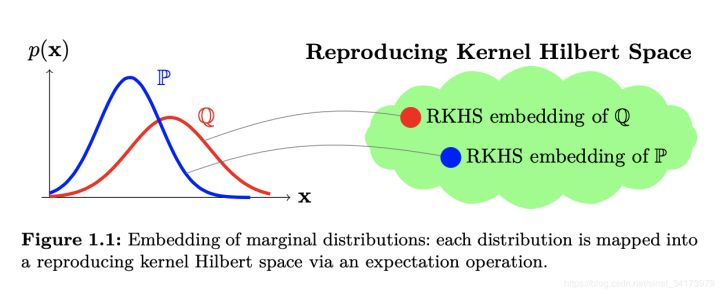
计算
和 由均值代替计算,可得:
其中,假设源域有 个样本,目标域有 个样本。至此,MMD 的关键在于如何找到一个合适的 作为映射函数。但是这个映射函数可能在不同的任务中不是固定的,很难去选取或者定义。因此,开始考虑采用核技巧,核技巧的关键就在于不需要显式地表示映射函数来求两个向量的内积。因此我们对 MMD 进行平方,化简得到内积并用核函数表达
其中, , 在特征空间的内积等于它们在原始样本空间中通过核函数 计算的结果。为了方便计算,常将其简化为矩阵形式:
其中,
此处,矩阵 即为 Gram 核矩阵。
实现
在实际的应用中一般使用的是多核 MMD,在这里实现的时候利用的就是多个不同 RBF-bandwith
的高斯核。
Pytorch 版本实现[3]如下:
import numpy as np
import torch
def guassian_kernel(source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):
"""计算Gram核矩阵
source: sample_size_1 * feature_size 的数据
target: sample_size_2 * feature_size 的数据
kernel_mul: 这个概念不太清楚,感觉也是为了计算每个核的bandwith
kernel_num: 表示的是多核的数量
fix_sigma: 表示是否使用固定的标准差
return: (sample_size_1 + sample_size_2) * (sample_size_1 + sample_size_2)的
矩阵,表达形式:
[ K_ss K_st
K_ts K_tt ]
"""
n_samples = int(source.size()[0])+int(target.size()[0])
total = torch.cat([source, target], dim=0) # 合并在一起
total0 = total.unsqueeze(0).expand(int(total.size(0)), \
int(total.size(0)), \
int(total.size(1)))
total1 = total.unsqueeze(1).expand(int(total.size(0)), \
int(total.size(0)), \
int(total.size(1)))
L2_distance = ((total0-total1)**2).sum(2) # 计算高斯核中的|x-y|
# 计算多核中每个核的bandwidth
if fix_sigma:
bandwidth = fix_sigma
else:
bandwidth = torch.sum(L2_distance.data) / (n_samples**2-n_samples)
bandwidth /= kernel_mul ** (kernel_num // 2)
bandwidth_list = [bandwidth * (kernel_mul**i) for i in range(kernel_num)]
# 高斯核的公式,exp(-|x-y|/bandwith)
kernel_val = [torch.exp(-L2_distance / bandwidth_temp) for \
bandwidth_temp in bandwidth_list]
return sum(kernel_val) # 将多个核合并在一起
def mmd(source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):
n = int(source.size()[0])
m = int(target.size()[0])
kernels = guassian_kernel(source, target,
kernel_mul=kernel_mul, kernel_num=kernel_num, fix_sigma=fix_sigma)
XX = kernels[:n, :n]
YY = kernels[n:, n:]
XY = kernels[:n, n:]
YX = kernels[n:, :n]
XX = torch.div(XX, n * n).sum(dim=1).view(1,-1) # K_ss矩阵,Source<->Source
XY = torch.div(XY, -n * m).sum(dim=1).view(1,-1) # K_st矩阵,Source<->Target
YX = torch.div(YX, -m * n).sum(dim=1).view(1,-1) # K_ts矩阵,Target<->Source
YY = torch.div(YY, m * m).sum(dim=1).view(1,-1) # K_tt矩阵,Target<->Target
loss = (XX + XY).sum() + (YX + YY).sum()
return loss
if __name__ == "__main__":
# 样本数量可以不同,特征数目必须相同
# 100和90是样本数量,50是特征数目
data_1 = torch.tensor(np.random.normal(loc=0,scale=10,size=(100,50)))
data_2 = torch.tensor(np.random.normal(loc=10,scale=10,size=(90,50)))
print("MMD Loss:",mmd(data_1,data_2))
data_1 = torch.tensor(np.random.normal(loc=0,scale=10,size=(100,50)))
data_2 = torch.tensor(np.random.normal(loc=0,scale=9,size=(80,50)))
print("MMD Loss:",mmd(data_1,data_2))
# MMD Loss: tensor(1.0866, dtype=torch.float64)
# MMD Loss: tensor(0.0852, dtype=torch.float64)
参考资料
统计知识(一)MMD Maximum Mean Discrepancy 最大均值差异: https://zhuanlan.zhihu.com/p/163839117
[2]随机变量的矩和高阶矩有什么实在的含义?: https://www.zhihu.com/question/25344430/answer/64509141
[3]easezyc/deep-transfer-learning: https://link.zhihu.com/?target=https%3A//github.com/easezyc/deep-transfer-learning/blob/5e94d519b7bb7f94f0e43687aa4663aca18357de/MUDA/MFSAN/MFSAN_3src/mmd.py
