




自监督学习提供了一种充分利用现有的大量无标记数据获取监督信号的有效方法,越来越受到关注。这篇论文[1]主要探索视频自监督学习的通用范式,发表在CVPR 2021和TIP 2022。
作者核心观点是视频的多尺度时序依赖很重要,这也是一个老生长谈的问题。
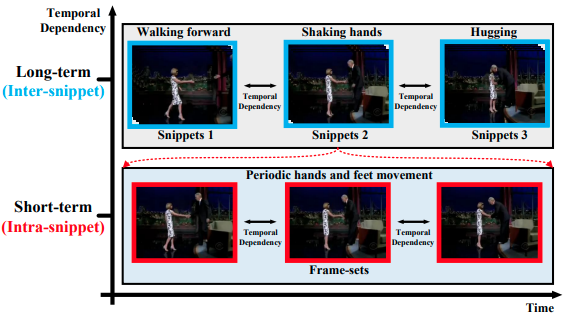
如下图所示,握手的动作包含了向前走、握手和拥抱的长时间依赖性(视频片段),同时也包含了周期性手脚运动的短时间依赖性(视频片段中的帧集)。因此,对视频进行均匀分段:
视频片段 -> 长时间依赖性 片段内部 -> 短时间依赖性
作者声称使用GCN探索视频时序多样性的工作在监督学习中普遍存在,在无标数据领域未有人涉足。因此,作者针对视频自监督表示学习这一问题,基于GCN和对比学习,利用时序预测任务,深入挖掘和探索视频长时间和短时间依赖。
实现上述目标,有以下四步:
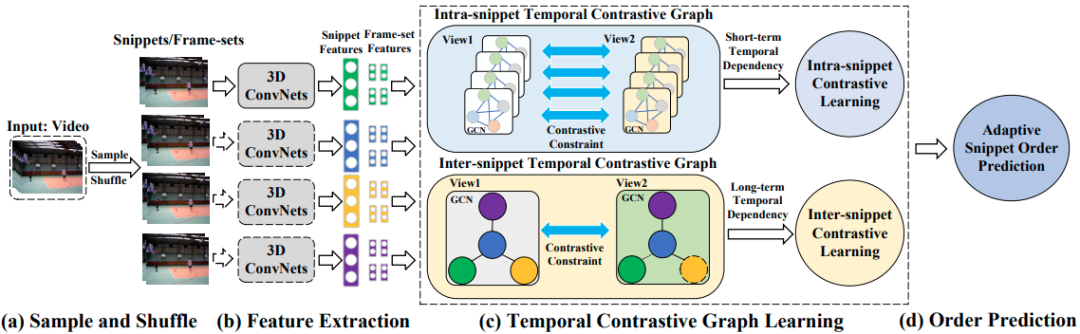
采样
对视频序列进行均匀分段得到 ,保证段的大小在3~4之间以降低顺序预测任务的复杂性,每一段 的视频帧集合记为 。
提取特征
首先使用一个 STKE 模块提取具有判别性的时空特征表示。本质上,原始的视频段内各帧 减去相应的平均帧 。
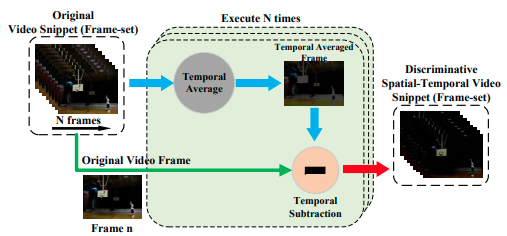
然后,使用各种 3D 卷积神经网络提取特征。
时序对比图学习
该模块旨在探究段内和段间的时序多样性。
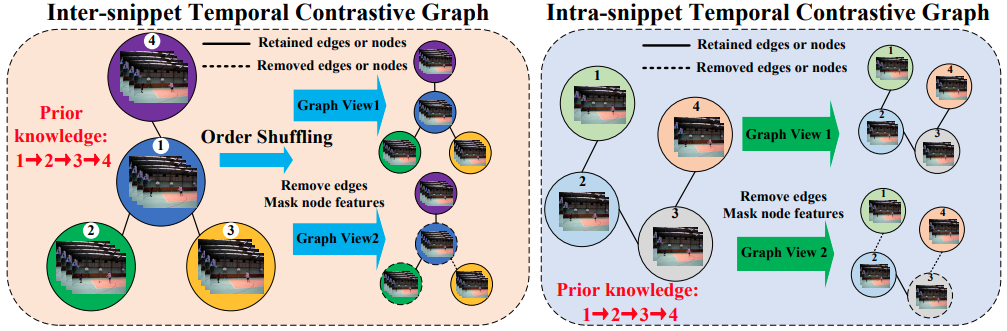
构造样本对
为了探索每个片段和帧集内的节点交互,以建模视频的多尺度时间依赖性。在得到视频片段和帧集的特征向量后,我们构造了两种时间对比图结构:片段间和片段内的时间对比图,以增加视频的时间依赖的多样性。
包括两个层面,
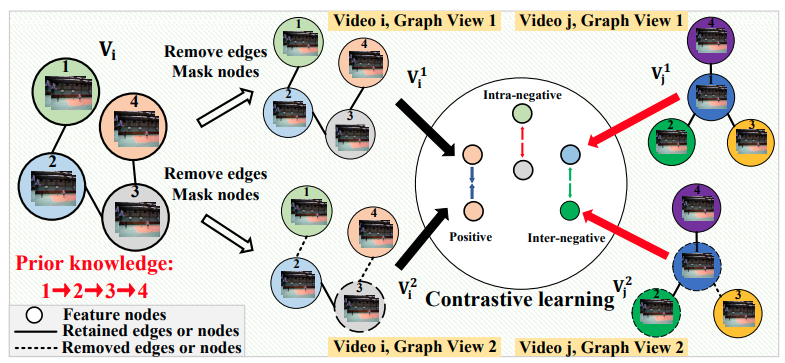
1)对图结构进行遮挡:
2)对特征进行遮挡:
给定一个正样本对,则负样本来自两个视图中。因此,对比损失目标函数定义为:
分母中的第一项表示正对,第二项表示视图间负对,第三项表示视图内负对。
段间图 损失定义为:
类似地,段内图 损失定义为:
因此,总体对比损失为:
其中, 和 为损失平衡因子。
自适应顺序预测
将从时间对比图中学习到的视频片段特征作为输入,将视频片段顺序的概率分布作为输出,将顺序预测任务定义为分类任务。
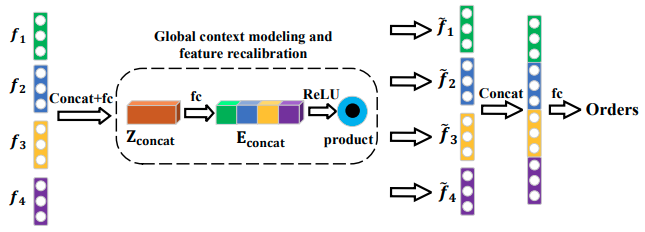
交叉熵损失用来衡量顺序预测的正确性,因此,总体损失为:
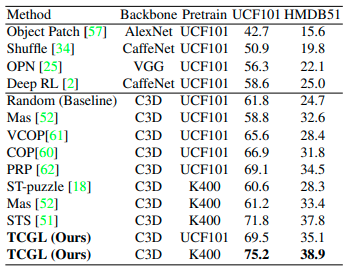
主要实验
在 UCF101 和 HMDB51
参考资料
Temporal Contrastive Graph Learning for Video Action Recognition and Retrieval: https://arxiv.org/pdf/2101.00820.pdf
