




打算通过一系列分享,和大家一起从头学css,目标如下:
帮助前端人员巩固和深入css相关领域的知识,最后能有不一样的收获
帮助对样式感兴趣的人员从入门到精通再到放弃
帮助自己系统的梳理基础性知识,查漏补缺
为什么是它
先来看一张老图
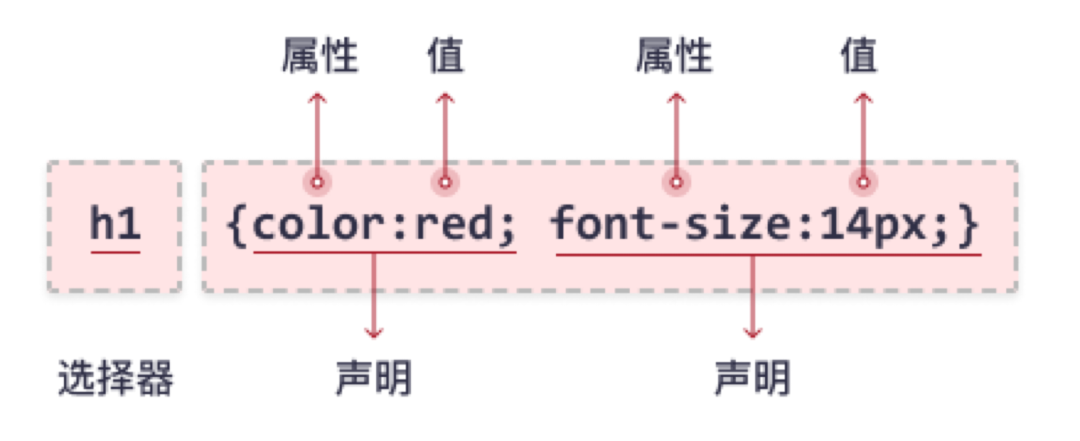
按照阅读习惯,我们从左往右看到的第一个就是选择器,这也是“主谓宾”中的“主”啊,重要优先程度可想而知。简单理解:选择器就是划定了要作用的样式的对象(群)。通俗的说:她(们)要开始化妆啦~ 那么这些她们都包含了那些人呢?
从问题开始
国际惯例,先抛出一个问题,下图是google首页,要想改变“手气不错”这个按钮样式,有多少种方法找到她改变她?
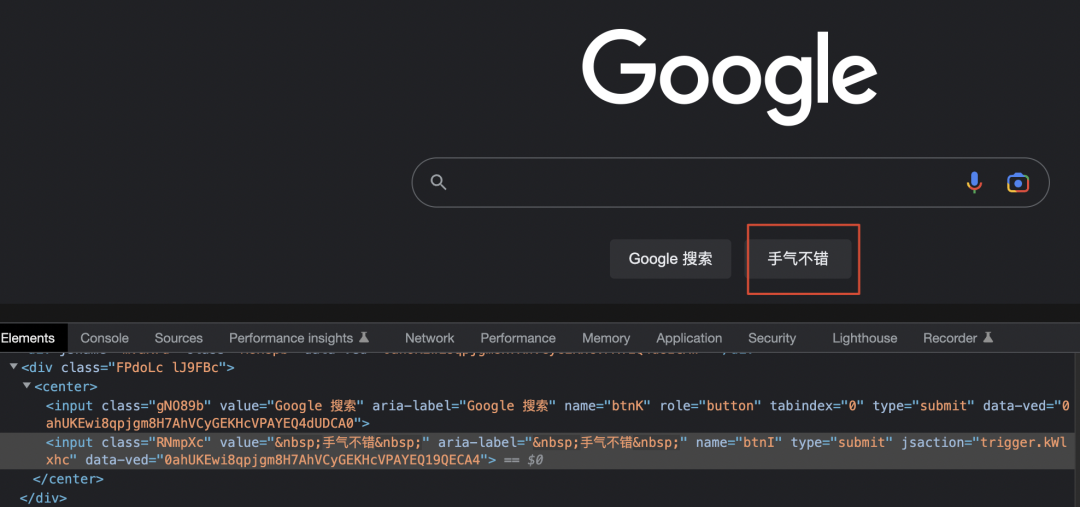
来,直接上答案!
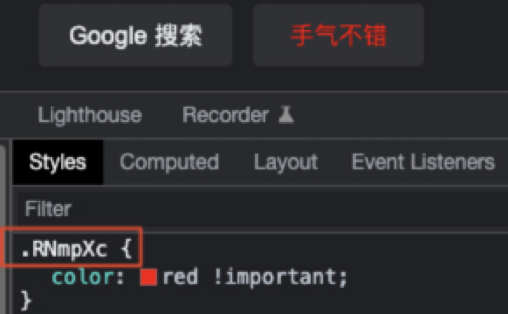
通过类名:
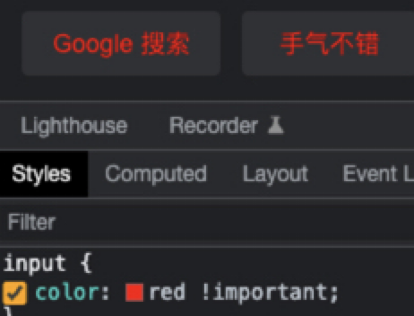
通过标签名:
通过属性:
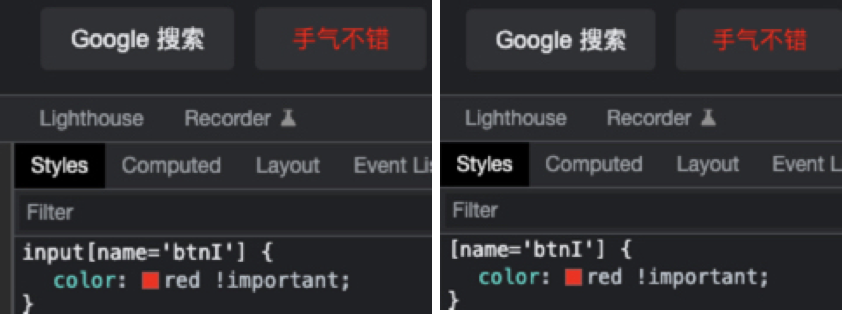
通过选择符:

通过伪类:

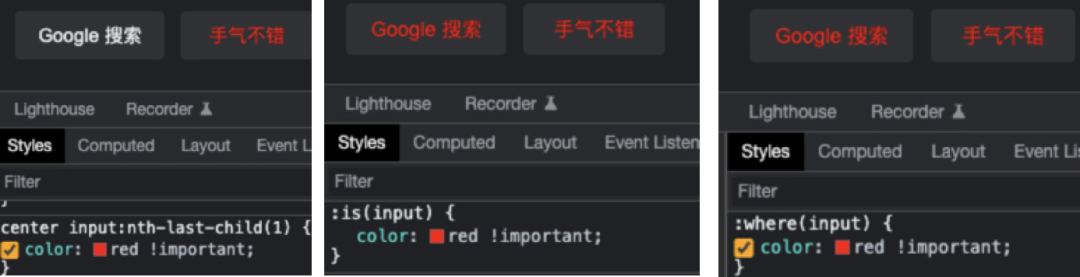
通过通配符:
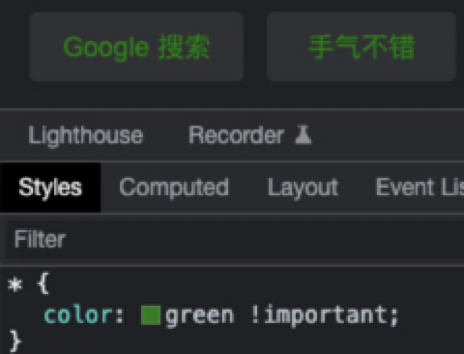
………
可以看到,方法是真的不少,但是相对来说,有的方法更准确,有的方法效率更高,有的方法使用更加合理。至于怎么选择,就通过下面的介绍有各位看官自己得出结论吧。
基础走起
选择器种类很多,我们按照用途,写法等的不同来做个简单的分类,定个基调。
一般选择器
Id选择器:#id
类选择器:.class
标签选择器:html
属性选择器:[type=submit]
通用选择器:* 请注意虽然*涵盖了基本所有的元素,但是并不包含::before和::after伪元素
选择符
交集关系(无符号):.a.b
并集关系(,):.a,.b
后代关系(空格):.a .b
父子关系(>):.a > .b
相邻兄弟(+):.a + .b
兄弟关系(~): .a ~ .b
列(||):.col || td
伪类
:hover
:focus
:last-child
:is
:where
:…
伪类非常多,数了下超过60个,而且还在不断增加迭代中,有很多伪类都非常的有用,如果感觉在写的样式非常复杂,不妨想想是不是可以用伪类来解决。特点显著:冒号(:)开头
伪元素
::before
::after
::first-line
::selection
::…
比起伪类,伪元素就少多了,但也有15个以上,最常用的还是before和after了,特点也很显著:双冒号(::)开头,别跟我说IE!
一、从一般选择器看起,基本上比较的好理解,好使用,唯一有些复杂的就是属性选择器,来个表格规整下其实也就清晰了
| 写法 | 含义 | 说明 |
|---|---|---|
| [attr] | 具有该属性即可 | [disabled] 不可用元素,vue的scoped样式隔离就是具有属性来实现的 |
| [attr="val"] | 属性全匹配 | 使用最多的一种,属性值相等 |
| [attr~="val"] | 部分匹配,注意不是模糊匹配 | 当属性值有多个(空格风格),可以匹配其中一个,如【name~="a"】 可以匹配 |
| [attr|="val"] | 起始匹配,注意不是模糊匹配 | 顾名思义,从属性开头开始匹配,匹配整个属性或则以“-”分割的前部分,如:[name|="a"] 匹配 name="a",name="a-x",name="b a-x"[name|="a"] 不匹配 name="ab" |
| [attr^="val"] | 以val开头的模糊匹配 | 这个好理解了,就是不糊匹配,不过是从头开始,比如[name^="a"] 匹配 name="a",name="ab"[name^="a"] 不匹配 name=“b a” |
| [attr$="val"]] | 以val结尾的模糊匹配 | 比较好理解了,就是和模糊匹配放在结尾的 |
| [attr*="val"] | 包含val的模糊匹配 | val可在属性任何位置,如:a[href^="http"]:not[href*="epay.163.com"] 匹配外域链接 |
上表基本上已经把属性选择器的所有用法列完了,那么还有1个问题,属性选择器中的属性值是否区分大小写吗?
以前有个i属性用来忽略大小写[attr^="a" i],但是我实际测试多个浏览器后发现,目前基本已经不区分大小写了,大致可以得到以下结论:
1、ID 和 类 选择器 区分 大小写
2、标签选择器、属性选择器 不区分 大小写
3、伪类和伪元素不区分大小写
二、再来看选择符,其作用就是通过一个元素寻找到其后代或则兄弟元素,非常的好理解,这里就不再重复累诉了。但是大家有没有发现一个问题,所有的选择符都是选择后代或则后面兄弟的,没有对应的祖先父亲选择符,也没有大哥选择符,这是又是为什么?
其实也很简单,不是做不到,是不值得做,根据DOM的渲染规则,我们遵循从上而下的规则,如果有祖先选择器,那么必然会导致回溯,已经渲染好的元素会再次渲染,影响体验和性能
三、其次看伪类,伪类很多很好用,但是并不是那么好记的,所以还是用一个表格先来做个简单的归类吧
| 名称 | 介绍 | 作用 |
|---|---|---|
| 激活类伪类 (:hover,:active,:focus…) | 用户行为相关的一些伪类 | 主要用来在用户操作时附加样式 |
| 定位伪类 (:link,:visited,:any-link,:target…) | 主要是与url相关的伪类 | 主要用来表述链接的状态,: |
| 输入伪类 (:enabled,:default:checked,:read-only…) | 主要是表单类交互的伪类 | 用来在和表单交互时,表单处在不同情况下的样式区别 |
| 结构化伪类 (:root,:empty,:first-child,nth-child…) | 主要dom树结构关系的伪类 | 用来直接选取某些特种元素或则根据其他节点选择当前元素 |
| 逻辑组合伪类 (:not,:is,:where,:has) | 如其名,根据关系排查元素 | 通过逻辑判断条件筛选到元素 |
| 其他伪类 (:scope,:host,:fullscreen,:dir,:lang…) | 作用各异,单独了解 | 作用各异,单独了解 |
虽然伪类选择器非常的多,但是大部分使用起来难度并不大,灵活的运用,合理的搭配往往能达到很多意想不到的效果。那么接下来就捡其中几个比较有意思的介绍下。
1、:empty 空元素伪类,不含内容(空包括格)不含子元素的元素,需要注意的是会把单标签也给囊括进去,使用场景如下:
避免空元素占位 :
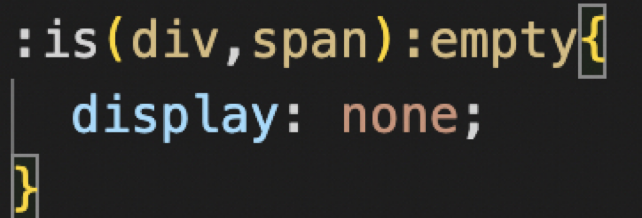
默认数据填充:

2、:not 否定伪类,支持链式写法也支持复杂参数,主要用来更方便的元素匹配,同时配合其他选择器也能起到意想不到的效果,比如
更方面的匹配:

tab切换:

3、:is,:where 任意匹配伪类,之所以把这2个放一起,是因为最终的达到的效果是差不多的,最大的区别可能就是优先级了,is的权重计算值以参数中权重最高的为其权重,而where无论参数是什么,最终的权重计算值始终为0(权重计算值会在下面介绍)。任意匹配伪类在我看来不是一个必选项,他并没有实现一些额外的功能,最大的最用就是精简选择器了,如下如图:

除此之外还可以用来突破一些框架的css作用域而不产生副作用,具体的可以查看文章,里面有较为详细的说明,当然这个也是利用了框架的“漏洞”而不是其本身真有什么特殊能力。
4、:has 具有选择器,可以实现类似父兄选择器的功能。什么!我们前面明明已经得出结论,因为性能问题不会有父兄的选择符的啊,怎么这里又蹦出个父兄的伪类选择器?


/**给”具有img子元素“的a元素添加样式,注意这里的样式是作用到a标签上的!**/
a:has(img){
}
四、最后看伪元素,这里不准备做过多的介绍,除了::before和::after 其他的使用频率并不高。
优先级
介绍完了选择器的种类说明,那么就需要来说说选择器最最重要的一个点:优先级,且看下图(计算值越高优先级也就越高)
| 等级 | 定义 | 计算值 |
|---|---|---|
| 0级 | 通配选择器、选择符和逻辑组合伪类 | 0 |
| 1级 | 标签选择器,伪元素 | 1 |
| 2级 | 类选择器、属性选择器和伪类 | 10 |
| 3级 | ID选择器 | 100 |
| 4级 | style属性内联 | 1000 |
| 5级 | !important | 10000 |
一般来说,上图的内容已经非常清晰透彻了,一个选择器的优先级,就是通过设定的计算值计算出来的。举个例子:
html body #nav .selected > a:hover
最终计算值为:1(html标签)+1(bod标签)+100(ID)+10(类)+0(选择符)+1(a标签)+10(伪类) = 123
但是我们可能还是有些疑惑的,来看看下面几个问题:
Q1:计算值一样怎么判断优先级
A:后来居上,谁写在后面,谁的优先级就高
Q2:样式和dom层级有什么关系
A:毫无关系,比如html div { } 和 body div { }是完全等效的
Q3:10个低级选择器能不能抵上一个高一级选择器
A:完全不能,目前一个层级的选择器保存在一个16位的空间中,所以如果想要超过上一层选择器,起码得写2的16次方个低级选择器才可以,而我们这里用10倍一般也够用了,因为没有人会写10个以上的同级别选择器,如果真遇到这种奇葩,也得知道,层级不可跨域
拓展延伸
那么到这里,我们是否对于选择器的使用和优先级都非常清晰了呢?不不,还不够,来看看@layer,翻译出来就是”层“,没错,实际也是层的概念,简单理解,就是给一堆样式套个壳变成一个层,然后对这个层进行降维打击,是唯二能降低选择器优先级的(还有一个是:where),总结起来就是有以下几个特点:
未被层级(@layer)包裹的优先级高于被包裹的
不同层级(@layer)之间等级分明,难以跨越
层级(@layer)之间优先级按照后来居上的原则
层级(@layer)中的优先级依据之前的逻辑
!important 权柄更大
我们直接通过下面几个题来理解上面的几个特点吧
/* 最终颜色为blue,遵循后来居上原则 */
@layer {
div {
color: red;
}
}
@layer {
div {
color: blue;
}
}
/* 最终颜色为red*/
@layer B,A;/**可以先定义后赋值,顺序为后来居上 **/
@layer A {
div {
color: red;
}
}
@layer B {
div {
color: blue;
}
}
/* 最终颜色为yellow 优先级为yellow->red->blue 被层级包裹的优先级更低*/
div {
color: yellow;
}
@layer A {
div {
color: red;
}
@layer B {
div {
color: blue;
}
}
}
/* 最终颜色为blue 优先级为blue->yellow->red */
div {
color: yellow;
}
@layer A {
div {
color: red;
}
@layer B {
div {
color: blue !important; /** !import的权柄更重,有了他,可以突破@layer的层级限制 **/
}
}
}
ok,通过上面的几个例子,应该对@layer层级有了一定的了解了吧,那么样式的优先级是不是到这里就完全搞懂了呢?,来看看下面这个例子吧
/* 优先级为blue->red->yellow 为什么?*/
.test {
color: red !important;
}
div {
color: yellow !important;
}
@layer A {
div {
color: blue !important;
}
}
对于这个结果,大家是否感到很困惑?

因为!import 确实是有些反常的,来看一张图就会比较清晰了:
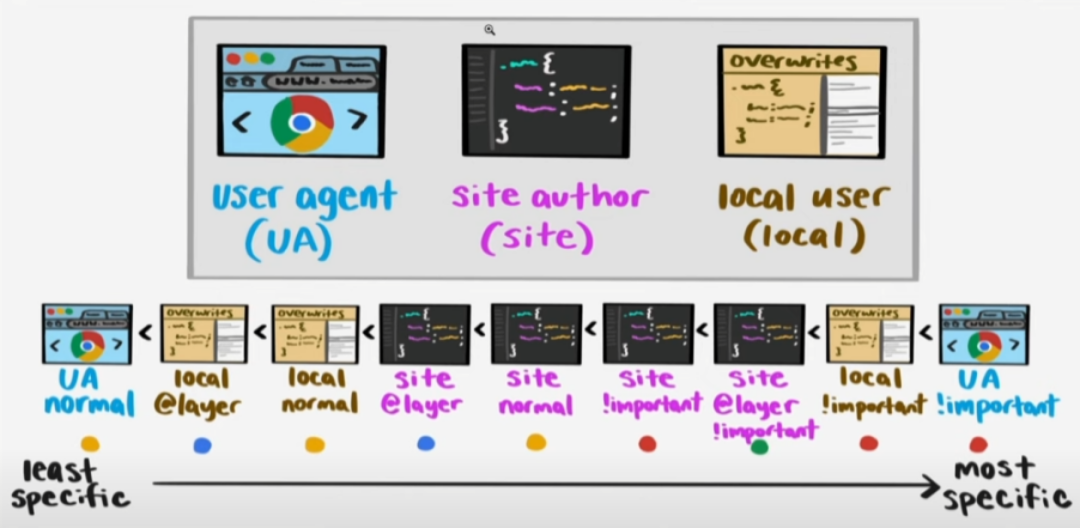
先对图上的名词解释下:
UA:是浏览器默认样式,只要我们代码头部有,浏览器就会加载默认样式,一般就是约定俗称的一些样式,比如给div加个display:block
site:作者样式,也就是我们写的css代码
local:用户样式,浏览器允许用户通过配置给其加载一些样式表,使用频率非常低。可以理解为定制化浏览器默认样式
ok,那回过头来看,样式的优先级非常明确,作者>用户>浏览器,但是一旦加上!import以后顺序就完全相反了,而这其中又把@layer分层给单独罗列了出来。site @layer !import的优先级高于site !important,所以上题中blue优先级最高。而red个yellow因为是在同一个层级(site)中,那么就依据权重计算值来判断了,很明显类(.test)高于标签(div),所以red优先级高于yellow
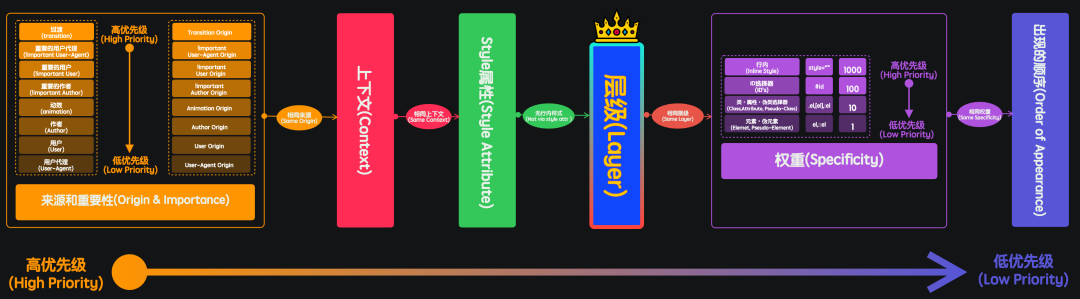
最后附上大漠老师一张比较完整的图
最佳推荐
基于上面的分析,总结了几个选择器相关的推荐写法,
尽量用class,而不是id 虽然id的性能可能更好,但是差距微乎其微,分工明确,我们还是把id留给js用吧
层次不要太多,层次多了,性能自然就差了
把更精确的写在右边,为了减少回溯选择器的查询规则是从右到左,所以把更准确的写在右边,提升效率
没有理由使用!important,!important 权柄太重,滥用只会让代码变得糟糕
后代选择符比父子选择符更优, 两者性能差距不大,但是后代选择符不用担心dom的微调变更
其实来说,上面那几点都不是那么重要,随着现在浏览器越来越强大,一般的性能问题,代码大小问题其实都已经不是我们要迫切关注的问题了,写的精准,读的明白在我看来才是最为重要的。
总结一下
我们前面其实一直没有考虑兼容性,有不少兼容性并不是非常好,比如前面说到的@layer
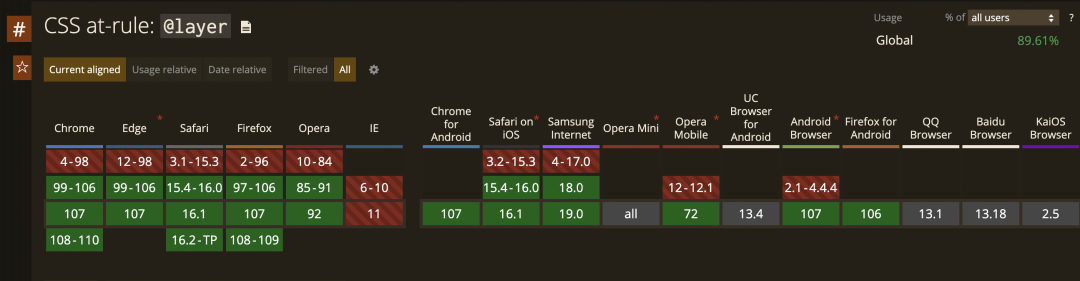
但是这个不能成为我们不去学习,不去使用的理由。我相信随着浏览器的迭代更新,越来越多有意思的css功能将被全面支持,我们要做的就是与时俱进,让我们的代码变的更加的优雅可观。
-- End --
点击下方的公众号入口,关注「技术对话」微信公众号,可查看历史文章,投稿请在公众号后台回复:投稿
