





file.txt,将其中的数字由大到小排序并取出前5个数字。
1 4 2
9 8 3 9
2 6 3 4 1
7 5 5
IdentityTreeMap的数据结构,专门解决key不可以重复的问题。
IdentityTreeMap数据结构中,它基于TreeMap实现内部自动排序,并且其中key和value都可以有重复,与TreeMap类似,它也是根据key进行排序,默认为自然顺序排序,但也可以根据需求自定义创建排序规则。
(1, 2);(2, 1);(1, 1);(3, 2);(2, 2)分别加入到
IdentityTreeMap中,它在内部会自动变成
(1, 2);(1, 1);(2, 1);(2, 2);(3, 2),这样就实现了按照key排序并且可重复,具体实现过程请在公众号后台回复
20230204获取详细代码。
IdentityTreeMap数据结构,并且定义该排序为倒序排序,同时命名为
map。
num的数组中,接下来遍历该数组写入到map中,键和值都为相同的数字,此处的原因有两个:一是
IdentityTreeMap数据结构为双值集合(key-value);二是需要按照key进行排序,value进行计数。事实上
IdentityTreeMap数据结构是通过
TreeMap的key进行排序,value进行向后追加实现的,这样就不会违背TreeMap数据结构的规则(key是唯一的),在该案例中可以抽象的理解成key进行排序,value进行计数。举一个例子:
(2, 2);(4, 4);(3, 3);(2, 2);(1, 1)在
IdentityTreeMap中会自动变成
(1, 1);(2, 2);(2, 2);(3, 3);(4, 4),实际上它是这样存储的:
[1, (1)];[2, (2, 2)];[3, (3)];[4, (4)],通过这个例子再回读上面的解释可能会更好理解。
remove()方法可以根据指定key-value删除元素,参数可以为HashMap类型。这里的
getLast()方法用来获取map中最后一个元素,返回类型为HashMap。
public class TopNMapper extends Mapper<LongWritable, Text, NullWritable, IntWritable> {
int N = 5;
private static final NullWritable KEY = NullWritable.get();
private static final IntWritable VAL = new IntWritable();
private final IdentityTreeMap<Integer, Integer> map = new IdentityTreeMap<>((o1, o2) -> o2 - o1);
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, NullWritable, IntWritable>.Context context) {
String[] num = value.toString().split(" ");
for (String n : num) {
map.put(Integer.parseInt(n), Integer.parseInt(n));
if (map.size() > N) map.remove(map.getLast());
}
}
protected void cleanup(Mapper<LongWritable, Text, NullWritable, IntWritable>.Context context) throws IOException, InterruptedException {
for (Integer value : map.values()) {
VAL.set(value);
context.write(KEY, VAL);
}
}
}
public class TopNReducer extends Reducer<NullWritable, IntWritable, NullWritable, IntWritable> {
int N = 5;
private static final NullWritable KEY = NullWritable.get();
private static final IntWritable VAL = new IntWritable();
private final IdentityTreeMap<Integer, Integer> map = new IdentityTreeMap<>((o1, o2) -> o2 - o1);
protected void reduce(NullWritable key, Iterable<IntWritable> values, Reducer<NullWritable, IntWritable, NullWritable, IntWritable>.Context context) {
for (IntWritable value : values) {
map.put(value.get(), value.get());
if (map.size() > N) map.remove(map.getLast());
}
}
protected void cleanup(Reducer<NullWritable, IntWritable, NullWritable, IntWritable>.Context context) throws IOException, InterruptedException {
for (Integer value : map.values()) {
VAL.set(value);
context.write(KEY, VAL);
}
}
}
20230204获取详细代码。
如何使用IDEA将Maven项目进行打包?文章,或在本公众号后台回复关键词
20230117获取该图文),并上传至服务器中
/usr/local/hadoop/jar路径下,同时开启HDFS和Yarn集群,将本文开头的
file.txt文件上传至服务器中
/root路径下。
$HADOOP_HOME/bin/hadoop fs -mkdir -p Mapreduce/TopN/input命令在HDFS中创建数据上传路径,使用
$HADOOP_HOME/bin/hadoop fs -put root/file.txt Mapreduce/TopN/input命令将
file.txt文件上传至HDFS的
/Mapreduce/TopN/input路径下。
$HADOOP_HOME/bin/hadoop jar usr/local/hadoop/jar/topn.jar Mapreduce/TopN/input Mapreduce/TopN/output命令启动MapReduce程序并提交到Yarn集群。

$HADOOP_HOME/bin/hadoop fs -cat Mapreduce/TopN/output/part-r-00000命令查看运行结果,此案例运行结果如下所示。

https://www.kaggle.com/datasets/chaitanyahivlekar/large-movie-datasetmovies_dataset.csv文件是每个用户对电影的评分数据,每一行为一条数据,每行数据有5个字段,分别是:行号、用户ID、电影名称、评分值和电影类型。示例数据如下:
0,1,Pulp Fiction (1994),5.0,Comedy|Crime|Drama|Thriller,本案例已经将该文件中的第一行删除(该数据第一行为字段名称并不是有效数据)。

Count和
TopN两个Mapreduce程序串联才可实现需求。
,进行数据切分时,数组中倒数第二个元素一定为评分值,但是由于在电影名称字段中也可能有
,,因此切分后的
data数组长度可能不为5,这里需要进行一个判断:若数组长度为5,则第二个元素一定为电影名称;若数组长度大于5,则需要将数组中第二个元素至倒数第二个元素之间的所有元素拼接起来,使用了
StringBuilder数据结构,得到电影名称;若数组长度小于5,则直接返回,数据为无效数据。
public class CountMapper extends Mapper<LongWritable, Text, Text, FloatWritable> {
private static final Text KEY = new Text();
private static final FloatWritable VAL = new FloatWritable();
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FloatWritable>.Context context) throws IOException, InterruptedException {
String[] data = value.toString().split(",");
int length = data.length;
float score = Float.parseFloat(data[length - 2]);
String name;
if (length == 5) name = data[2];
else if (length > 5) {
StringBuilder nameStringBuilder = new StringBuilder();
for (int i = 2; i < length - 2; i++) nameStringBuilder.append(data[i]);
String nameStringBuilderToString = nameStringBuilder.toString();
name = nameStringBuilderToString.substring(1, nameStringBuilderToString.length() - 1);
} else return;
int year;
try {
String[] splitLeft = name.split("\\(");
year = Integer.parseInt(splitLeft[splitLeft.length - 1].split("\\)")[0]);
} catch (NumberFormatException ignored) return;
if (year >= 2018) {
KEY.set(name);
VAL.set(score);
context.write(KEY, VAL);
}
}
}
count记录各个电影的评分用户数量,然后通过这两个指标就可以得到各个电影的平均评分并将结果保留1位小数,最后设置KEY和VAL并写入下一阶段。
public class CountReducer extends Reducer<Text, FloatWritable, Text, Text> {
private static final Text KEY = new Text();
private static final Text VAL = new Text();
protected void reduce(Text key, Iterable<FloatWritable> values, Reducer<Text, FloatWritable, Text, Text>.Context context) throws IOException, InterruptedException {
int count = 0;
float sum = 0;
for (FloatWritable score : values) {
sum += score.get();
count++;
}
String average = String.format("%.1f", sum / count);
KEY.set(key);
VAL.set(average);
context.write(KEY, VAL);
}
}
IdentityTreeMap数据结构,并且定义该排序为倒序排序,同时命名为
map。
\t,得到的数组第一个元素为评分值,第二个元素为电影名称,然后写入map中,键为评分,值为电影名称,始终保留map中前N条数据,若超出N条则删除map中最后一条(因为map中key是按降序排列的,key值大的在map前部)。
public class TopNMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
int N = 100;
private static final NullWritable KEY = NullWritable.get();
private static final Text VAL = new Text();
private final IdentityTreeMap<Float, String> map = new IdentityTreeMap<>((o1, o2) -> {
float flag = o2 - o1;
if (flag > 0) return 1;
if (flag < 0) return -1;
return 0;
});
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, NullWritable, Text>.Context context) {
String[] data = value.toString().split("\t");
String name = data[0];
float score = Float.parseFloat(data[1]);
map.put(score, name);
if (map.size() > N) map.remove(map.getLast());
}
protected void cleanup(Mapper<LongWritable, Text, NullWritable, Text>.Context context) throws IOException, InterruptedException {
for (HashMap<Float, String> element : map.getAll()) {
String[] elementStringSplit = element.toString().split("=");
VAL.set(elementStringSplit[0].split("\\{")[1] + "\t" + elementStringSplit[1].split("\\}")[0]);
context.write(KEY, VAL);
}
}
}
public class TopNReducer extends Reducer<NullWritable, Text, Text, Text> {
int N = 100;
private static final Text KEY = new Text();
private static final Text VAL = new Text();
private final IdentityTreeMap<Float, String> map = new IdentityTreeMap<>((o1, o2) -> {
float flag = o2 - o1;
if (flag > 0) return 1;
if (flag < 0) return -1;
return 0;
});
protected void reduce(NullWritable key, Iterable<Text> values, Reducer<NullWritable, Text, Text, Text>.Context context) {
for (Text value : values) {
String[] valueSplit = value.toString().split("\t");
map.put(Float.parseFloat(valueSplit[0]), valueSplit[1]);
if (map.size() > N) map.remove(map.getLast());
}
}
protected void cleanup(Reducer<NullWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
for (HashMap<Float, String> element : map.getAll()) {
String[] elementStringSplit = element.toString().split("=");
KEY.set(elementStringSplit[0].split("\\{")[1]);
VAL.set(elementStringSplit[1].split("\\}")[0]);
context.write(KEY, VAL);
}
}
}
20230204获取详细代码。
如何使用IDEA将Maven项目进行打包?文章,或在本公众号后台回复关键词
20230117获取该图文),并上传至服务器中的
/usr/local/hadoop/jar路径下,同时开启HDFS和Yarn集群,将
movies_dataset.csv电影数据上传至服务器中的
/root路径下。
$HADOOP_HOME/bin/hadoop fs -mkdir -p /Mapreduce/TopNMovies/input命令在HDFS中创建数据上传路径,使用
$HADOOP_HOME/bin/hadoop fs -put /root/movies_dataset.csv /Mapreduce/TopNMovies/input命令将
movies_dataset.csv文件上传至HDFS的
/Mapreduce/TopNMovies/input路径下。
$HADOOP_HOME/bin/hadoop jar /usr/local/hadoop/jar/topn-movies.jar /Mapreduce/TopNMovies/input /Mapreduce/TopNMovies/output /Mapreduce/TopNMovies/temp命令(该命令需要传递三个参数,第一个为Count阶段输入路径,第二个为TopN阶段输出路径,第三个为Count阶段输出路径也是TopN阶段输入路径)启动MapReduce程序并提交到Yarn集群。
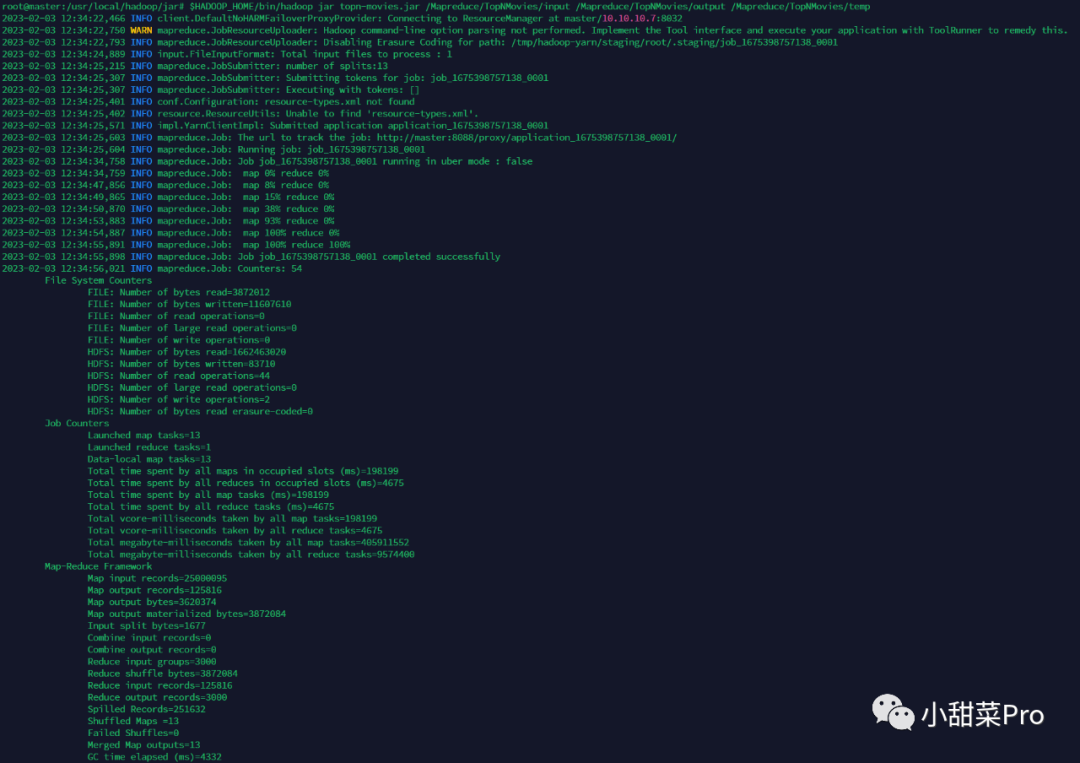
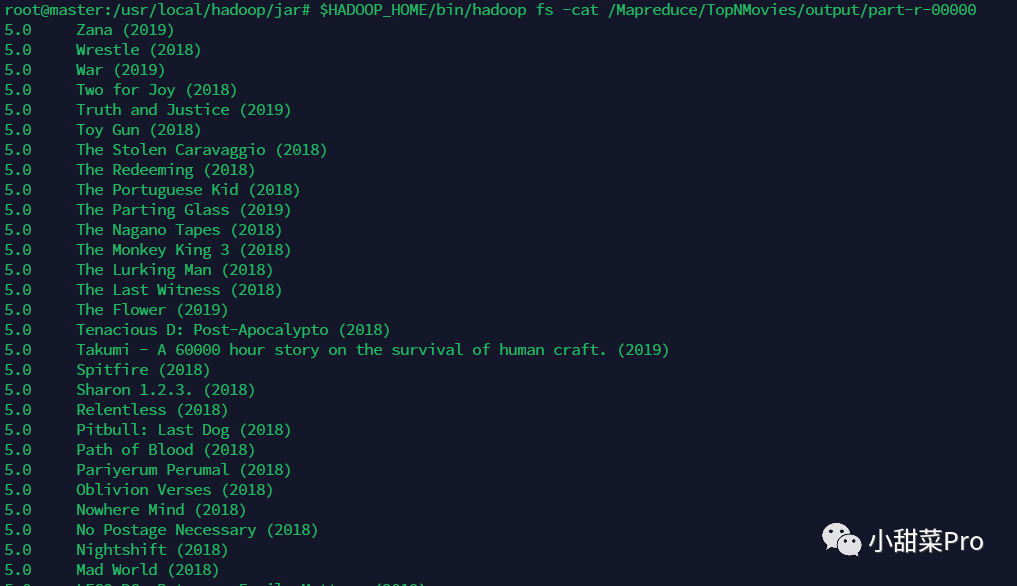
$HADOOP_HOME/bin/hadoop fs -cat /Mapreduce/TopNMovies/output/part-r-00000命令查看运行结果,此案例运行结果如下所示。
20230204,若各位小伙伴有什么不懂的问题也可以直接在公众号后台留言,感谢观看!
文章转载自小甜菜Pro,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
