





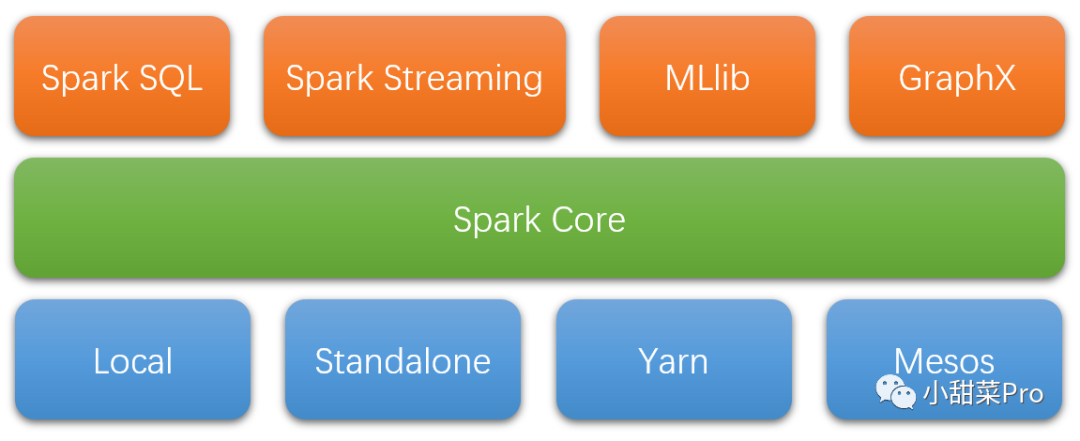
搭建Hadoop3.x分布式集群文章,或者在公众号后台回复
20230116获取该图文)。演示所使用的Spark版本为3.3.1,Hadoop版本为3.3.4。
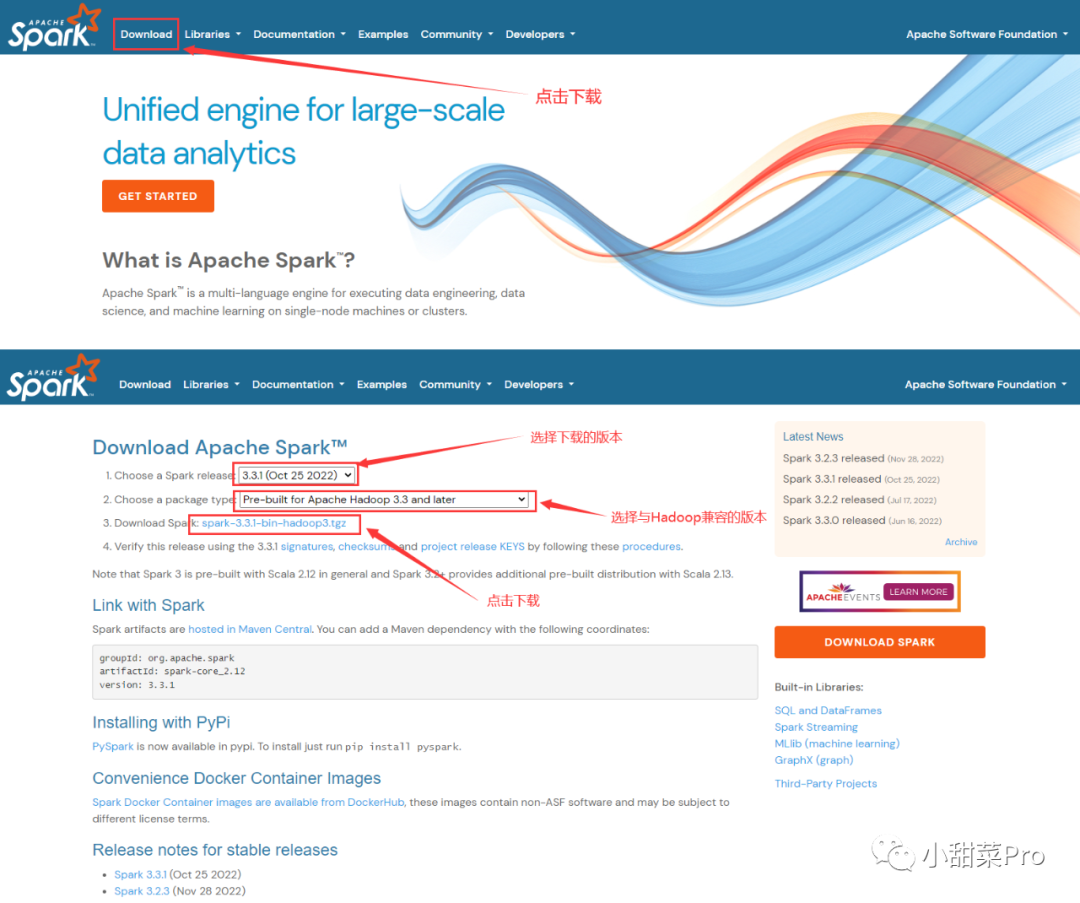
https://spark.apache.org并按照以下图示进行下载。
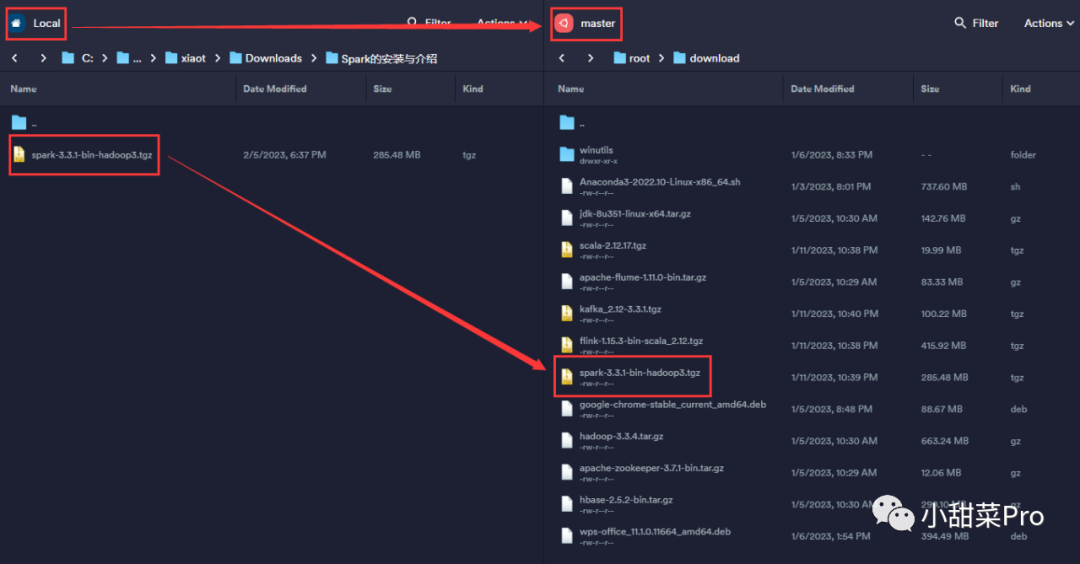
2、将下载好的安装包上传至master
主机中/root/download
路径下。
3、tar -zxvf root/download/spark-3.3.1-bin-hadoop3.tgz -C usr/local
命令解压安装包。
4、mv usr/local/spark-3.3.1-bin-hadoop3 usr/local/spark
命令重命名默认文件夹。
5、vim root/.bashrc
修改系统环境变量,在文件最后添加以下代码。
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
使用:wq
保存并退出,同时使用source root/.bashrc
命令让环境变量立即生效。
6、cp usr/local/spark/conf/spark-env.sh.template /usr/local/spark/conf/spark-env.sh
命令拷贝配置文件。
7、vim /usr/local/spark/conf/spark-env.sh
命令修改配置文件,在文件末尾添加以下代码,这里会涉及到Hadoop的安装路径,这里要根据实际情况进行调整。
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export YARN_CONF_DIR=/usr/local/hadoop/etc/hadoop
export LD_LIBRARY_PATH=/usr/local/hadoop/lib/native
8、$HADOOP_HOME/bin/hadoop fs -mkdir -p /tmp/spark-yarn
命令在HDFS上创建/tmp/spark-yarn
路径。
9、$HADOOP_HOME/bin/hadoop fs -put /usr/local/spark/jars/* /tmp/spark-yarn
命令将jar包上传至刚创建好的路径中。
10、cp /usr/local/spark/conf/spark-defaults.conf.template /usr/local/spark/conf/spark-defaults.conf
命令拷贝默认配置文件。
11、vim /usr/local/spark/conf/spark-defaults.conf
命令修改配置文件,在文件末尾添加spark.yarn.jars
参数。
spark.yarn.jars=hdfs:///tmp/spark-yarn/*.jar
使用:wq
保存并退出。
spark.yarn.jars参数,若不进行设置也是可以运行的,但是会出现
Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.警告信息,建议进行设置。接下来可以执行以下命令测试是否成功安装。
$SPARK_HOME/bin/spark-submit \
--master yarn \
--deploy-mode client \
--class org.apache.spark.examples.SparkPi /usr/local/spark/examples/jars/spark-examples_2.12-3.3.1.jar 20
--master yarn用来指定将任务提交到yarn中去执行;
--deploy-mode client指定为本地客户端模式,在本地启动driver,并且本地会产生一个程序的客户端;
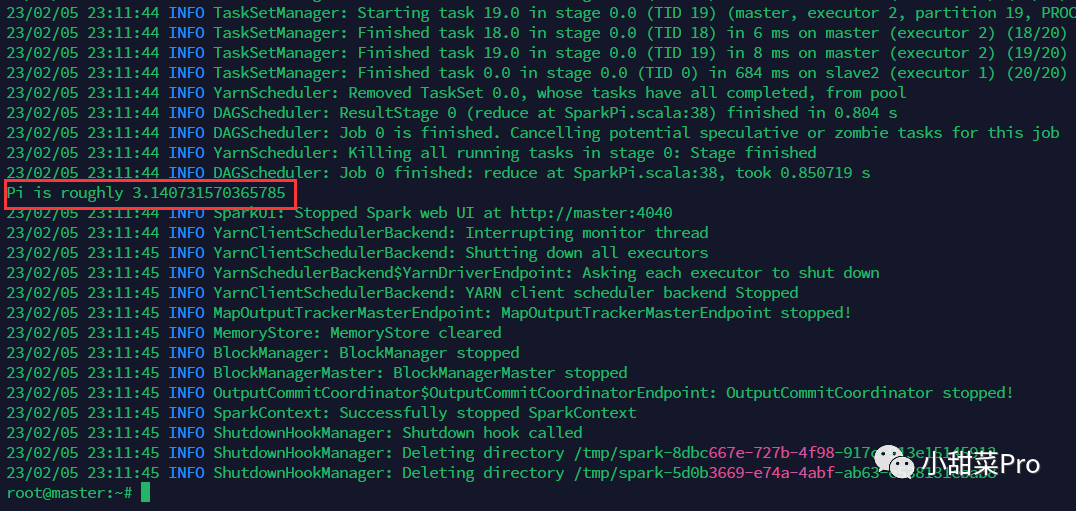
--class org.apache.spark.examples.SparkPi /usr/local/spark/examples/jars/spark-examples_2.12-3.3.1.jar 20用来指定应用程序的主类即入口类。以上命令实现的功能是粗略求出圆周率的值,运行结果如下图所示。
20230206,若各位小伙伴有什么不懂的问题请在后台留言,感谢观看!
