





file1.txt和
file2.txt,对它们进行加权倒排索引,整体思想流程如下图所示。
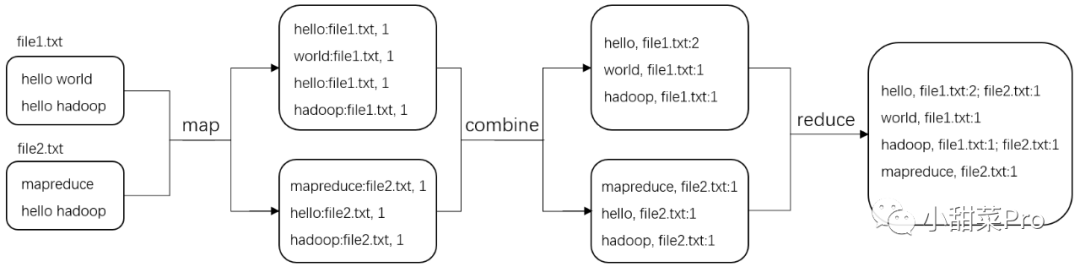
combine的过程,它可以理解为是在map阶段的reduce操作,是对单个map任务的输出结果数据进行合并的操作。
words的字符串数组中,同时利用
FileSplit类获取该数据行所在的文件名称,将这个文件名称存放在名为
fileName的字符串变量中,接下来遍历
words字符串数组,将数组中的每个元素与文件名称进行拼接(拼接时使用
word :filename的格式,例如:
hadoop:file1.txt),拼接后的数据为设置
KEY的值,最后将
KEY和
VAL写入下一阶段(这里的
VAL是一个字符1,是为了在
combine阶段进行计数)。
public class InvertedIndexMapper extends Mapper<LongWritable, Text, Text, Text> {
private static final Text KEY = new Text();
private static final Text VAL = new Text("1");
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String fileName = fileSplit.getPath().getName();
for (String word : words) {
KEY.set(word + ":" + fileName);
context.write(KEY, VAL);
}
}
}
Reducer类。在该阶段中将Map阶段传来的每个key中的value进行计数,由于Map阶段最终的输出
VAL类型为
Text,因此要使用
toString()方法转为字符串类型,并同时使用
Integer类的
parseInt()方法继续转为
int类型,再进行累加,但是这样操作较为繁琐,由于这里只是为了实现计数功能,并且Map阶段最终的输出
VAL为字符串1,因此可以直接使用
sum ++语句进行计数。
word :filename格式),最后将单词
word作为
KEY,文件名称
filename与计数
sum拼接后作为
VAL传入下一阶段。
VAL设置成
IntWritable类型呢?这样是不是就可以不用在Combine阶段进行两次转变数据类型,而是直接使用
get()方法得到数字1呢?
<Text, IntWritable>,那么Combine阶段的输入输出类型为
<Text, IntWritable, Text, IntWritable>,而Reduce阶段的输入则为
<Text, IntWritable>,但是在Combine阶段的输出类型必须为
<Text, Text>类型(输出的key为单词
word,value为文件名称和计数的拼接数据
filename:sum,因此只能使用
Text类型传递),所以Map阶段的输出类型也必须为
<Text, Text>类型,这样就解释清楚以上问题的答案了。
public class InvertedIndexCombiner extends Reducer<Text, Text, Text, Text> {
private static final Text KEY = new Text();
private static final Text VAL = new Text();
protected void reduce(Text key, Iterable<Text> value, Context context) throws IOException, InterruptedException {
int sum = 0;
for (Text v : value) sum += Integer.parseInt(v.toString());
String[] line = key.toString().split(":");
String word = line[0];
String filename = line[1];
KEY.set(word);
VAL.set(filename + ":" + sum);
context.write(KEY, VAL);
}
}
StringBuilder类型,将拼接后的数据作为
VAL,而
KEY依然为上一阶段的输出
KEY,最后写入下一阶段。
public class InvertedIndexReducer extends Reducer<Text, Text, Text, Text> {
private static final Text KEY = new Text();
private static final Text VAL = new Text();
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuilder fileIndex = new StringBuilder();
for (Text value : values) fileIndex.append(value.toString()).append(";");
KEY.set(key);
VAL.set(fileIndex.toString());
context.write(KEY, VAL);
}
}
20230308获取详细代码。
如何使用IDEA将Maven项目进行打包?文章,或在本公众号后台回复关键词
20230117获取该图文),并上传至服务器中
/usr/local/hadoop/jar路径下,同时开启HDFS和Yarn集群,将本文开头的
file1.txt文件和
file2.txt文件上传至服务器中
/root路径下。
$HADOOP_HOME/bin/hadoop fs -mkdir -p /Mapreduce/InvertedIndex/input命令在HDFS中创建数据上传路径,使用
$HADOOP_HOME/bin/hadoop fs -put /root/file* /Mapreduce/InvertedIndex/input命令将两个示例文件上传至HDFS的
/Mapreduce/InvertedIndex/input路径下。
$HADOOP_HOME/bin/hadoop jar /usr/local/hadoop/jar/InvertedIndex.jar /Mapreduce/InvertedIndex/input /Mapreduce/InvertedIndex/output命令启动MapReduce程序并提交到Yarn集群。
$HADOOP_HOME/bin/hadoop fs -cat /Mapreduce/InvertedIndex/output/part-r-00000命令查看运行结果,此案例运行结果如下所示。

本文详细讲解了MapReduce倒排索引案例,以上就是本期分享的全部内容,想要获取本文中的全部代码及数据,请在公众号后台回复关键词20230308
,若各位小伙伴有什么不懂的问题也可以直接在公众号后台留言,感谢观看!
文章转载自小甜菜Pro,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
