




前言
如果希望备份和恢复速度快,那么使用物理备份是毫无疑问的。物理备份和恢复是有使用限制的,源端和目标端必须是 MySQL,操作系统需要一致,最好连数据库小版本和 my.cnf 配置都一样,等于完全做一个数据库的克隆,这个场景更适用于扩展从库,或者通过备份重建主库。我们在做 MySQL 数据迁移的时候,更多的是做部分数据迁移,或异构数据库的迁移,或者无法保证对端数据库版本、my.cnf、操作系统、硬件等配置一样的情况的迁移,这个时候应当使用逻辑备份。
当然了,逻辑备份和恢复是很慢的,这很折磨 DBA。
逻辑备份常见有以下工具:
mysqldump mysqlpump mydumper mysqlshell 的 Dump&Load 插件
这些工具中哪个备份最快?哪个恢复最快呢?在 2020 年 4 月 MySQL 官方为了证明其 mysqlshell 的 Dump&Load 插件强劲的实力,在以下条件对以上四款常见逻辑备份工具做了备份和恢复的性能测试。
Oracle Linux 7.8 MySQL8.0.21 关闭 redo log OCI BM.Standard.B1.44 - 44x Intel Xeon E5-2669 v4 - 512GB RAM,Storage: 8x 400GB - 240MB/s in RAID-0 的硬件 对比网上能下载到的 3 个示例库Ontime、Stackoverflow、EN Wikipedia、All(以上3个库的混合)
备份性能
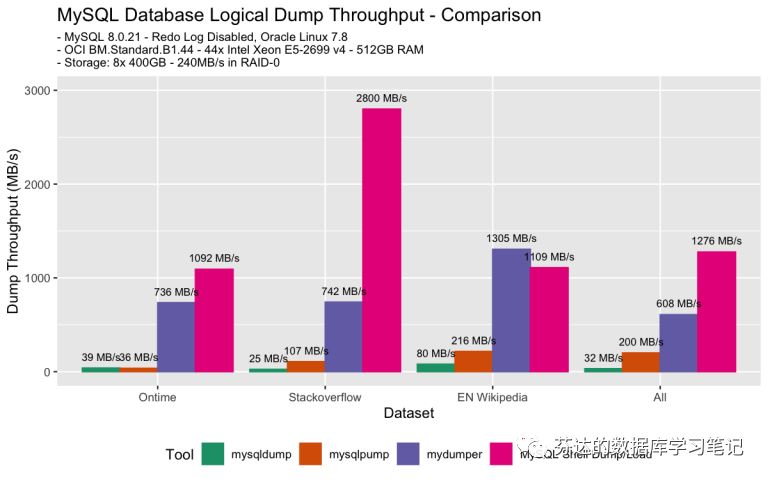
备份性能(带压缩)

从图上可以看出,无论备份带不带压缩,速度最快的都是 mysqlshell 的 Dump&Load 插件,最慢的都是 mysqldump。另外,我们可以看到使用压缩,会使备份速度大打折扣,图中最高下降了 14 倍。
对于大多数 DBA 来说:
mysqlshell 的使用并没有普及,并且官方文档中说他只适用于 MySQL 到 MySQL 的数据迁移,只适用于 InnoDB。 mysqlpump 很鸡肋,相对 mysqldump 提升很小,他的并行备份和恢复功能,只能基于 database 级别。意味着你如果只有一个 sbtest 的数据库,是无法并行的,那用起来和 mysqldump 就差不多了。 mydumper,很好、很快,互联网上很多人使用,但鉴于他是第三方出品,我不怎么使用,对新手 DBA 不做推荐。(还有一个原因,他没有给我广告费🙂)
对于刚入门的 DBA,最常见的备份工具是 mysqldump。
现在,我要引出我的主题,对于最慢的 mysqldump 工具,如何合理使用 mysqldump 提高迁移数据库的效率?
下面我们做几个实验,看看。
实验约定:
互联网公司基本业务都不允许停机,而传统行业,尤其是金融行业,金融行业又尤其是证券行业,他们下午 4 点都下班了,肯定可以停机迁移数据库。传统行业追求是稳,这种迁移数据库的需求又不常见,所以我下面的实验均基于停业务的情况下做的,这样我们可以少去考虑备份性能并发度对生产的影响,也可以少考虑备份一致性相关问题。
实验环境
两台 2c4g vmware CentOS7.5,nvme ssd 保证了 io 性能不是瓶颈 源端 MySQL5.7.40 目标端 MySQL5.7.40 千兆内网
实验一 直接干
直接干是最简单的,我们测试一下耗时,作为备份恢复花费时间的基准。
步骤
源端备份 网络传输到待恢复的机器 目标端恢复
#1.源端备份
[root@mysql01 ~]# time mysqldump sbtest --set-gtid-purged=OFF > sbtest.sql
real 0m47.989s
user 0m31.202s
sys 0m5.495s
# sbtest.sql 文件大小 3.8GB
#2.网络传输到待恢复的机器
[root@mysql01 ~]# time scp sbtest.sql root@mysql02:/tmp
root@mysql02's password:
sbtest.sql 100% 3813MB 106.2MB/s 00:35
real 0m38.182s
user 0m7.114s
sys 0m29.108s
#3.目标端恢复
[root@mysql02 ~]# time mysql sbtest < tmp/sbtest.sql
real 6m36.449s
user 0m33.522s
sys 0m4.247s
总迁移耗时 = 48s + 38s + 6m36s = 8m2s
实验二 压缩
很多情况下,备份恢复耗时,时间大头是花在网络传输上,所以实验二中,我们在传输的之间加入了压缩和解压,看看耗时。
步骤
源端 源端备份 源端压缩 网络传输 网络传输到待恢复的机器 目标端恢复 目标端解压 目标端恢复
#1.1源端备份
[root@mysql01 ~]# time mysqldump sbtest --set-gtid-purged=OFF > sbtest.sql
real 0m47.989s
user 0m31.202s
sys 0m5.495s
# sbtest.sql 文件大小 3.8GB
#1.2源端压缩
[root@mysql01 ~]# time gzip -c sbtest.sql > sbtest.sql.gz
real 4m19.514s
user 4m12.732s
sys 0m6.536s
# 压缩后的 sbtest.sql.gz 文件大小 1.8GB
#2.网络传输到待恢复的机器
[root@mysql01 ~]# time scp sbtest.sql.gz root@mysql02:/tmp
root@mysql02's password:
sbtest.sql.gz 100% 1831MB 115.1MB/s 00:15
real 0m17.826s
user 0m3.086s
sys 0m13.170s
#3.1目标端解压
[root@mysql02 tmp]# time gzip -d sbtest.sql.gz
real 0m31.143s
user 0m26.884s
sys 0m4.122s
#3.2目标端恢复
[root@mysql02 ~]# time mysql sbtest < tmp/sbtest.sql
real 6m36.449s
user 0m33.522s
sys 0m4.247s
总迁移耗时 = 48s + 4m20s + 18s + 31s + 6m36s = 12m33s
压缩了反而导致迁移速度变慢了,主要原因是,压缩的目的是为了用 CPU 的运算能力来换取备份文件的小体积,而备份文件小体积可以减少网络传输的耗时。由于我的实验环境中网路并不是瓶颈 (千兆内网),而 gzip 这个压缩工具不支持并行压缩,我的测试服务器的两核只能用到一核去压缩,压缩特别慢,压缩耗时 4m20s,解压耗时 31s,而网络传输节省的时间只有 21s。
在这种情况下,我认为只有大于 16 核,并且支持并行压缩,才能节省备份恢复的迁移时间。这个具体多少核是我大概估算的,具体和备份工具有很强的关系。
目前看来,大多数情况,想节省时间,作为不支持并行备份的 mysqldump 做迁移时可以考虑不压缩,除非你的网络是有成本的,例如:
网络受限 文件转存不像我用 scp 那么方便,需要 filezilla 之类的软件下载到安全堡垒,然后安全堡垒上传到对端服务器,中间网络传输复杂,耗时较长。 服务器之间做了网络限速。 要钱,网络需要流量费(常见于公网之间的数据流转)。
实验三 边备份边压缩,边解压边导入
实验二的操作方法很简单,先备份再压缩,但实际上,备份和压缩是可以一起做的,利用管道符,能节省等待时间,使用管道之前,压缩需要等待备份完成才能开始进行,使用管道之后,边备份边压缩,最终耗时就是以两者之中最慢的那个决定。解压和恢复同理也可以。
步骤
源端备份并压缩 网络传输到待恢复的机器 目标端解压并恢复
#1.源端备份并压缩
[root@mysql01 ~]# time mysqldump sbtest --set-gtid-purged=OFF | gzip -c > sbtest.sql.gz
real 4m25.609s
user 4m26.886s
sys 0m24.702s
#2.网络传输到待恢复的机器
[root@mysql01 ~]# time scp sbtest.sql.gz root@mysql02:/tmp
root@mysql02's password:
sbtest.sql.gz 100% 1831MB 115.1MB/s 00:15
real 0m17.826s
user 0m3.086s
sys 0m13.170s
#3.目标端解压并恢复
[root@mysql02 tmp]# time gzip -dc sbtest.sql.gz | mysql sbtest
real 6m58.995s
user 1m2.140s
sys 0m4.684s
总迁移耗时 = 4m26s + 18s + 6m59s = 11m43s
因为实验二的结论已经证明了,我的瓶颈不在网络,所以实验三这种方法并不快,比实验二快,但比基准的"直接干"方式还是慢很多,他适合于源端 MySQL 磁盘空间不太够的场景,他能直接备份出一个压缩后的只有 1.8G 的 sql.tar.gz 文件,那么如果当时磁盘空间不足,那用这个方法是不错的选择。
实验四 边备份边传输边恢复(22 端口)
既然在我的环境中,压缩并不提升性能,反而损害了性能,那么我就不压缩吧,在实验四中,我还做了个优化,就是把网络传输也放到管道中一起做了,这就是所谓的逻辑的流备份和恢复了。
步骤
源端备份并传输并远程目标端导入恢复
[root@mysql01 ~]# time mysqldump sbtest --set-gtid-purged=OFF | ssh root@mysql02 "cat - | mysql sbtest"
root@mysql02's password:
real 6m44.393s
user 0m44.910s
sys 0m44.335s
总迁移耗时 = 6m44.393s
这个耗时就非常短,并且就一条命令非常简洁,由整个流程中的最短板(也就是数据的导入阶段)决定了整个流程的速度。
实验五 边备份边传输边恢复(3306 端口)
我在实验二的结论中提到了“网络受限”,两台服务器之间如果因为安全原因不允许打通 22 端口,那么我们可以利用 mysqldump 支持远程备份的方式,依然可以实现流备份恢复。
步骤
目标端远程备份源端数据并导入恢复
[root@mysql02 tmp]# time mysqldump -ufanderchan -pmypassword -hmysql01 -P3306 sbtest --set-gtid-purged=OFF | mysql sbtest
mysqldump: [Warning] Using a password on the command line interface can be insecure.
real 7m26.868s
user 0m54.520s
sys 0m35.703s
这种方式会比实验四速度慢一些,原因不详。
实验四的方法更具通用性,因为:
实验四也适用于别的数据库的工具,例如 PostgreSQL 的 pg_dump, 实验四的中间的管道可以接压缩命令,可以让网络流量减少。 实验五有使用限制,要求 mysqldump 具有远程导出能力
实验四、实验五的流备份恢复的共同优点是:
一条命令即可,这个备份是一个流式的,耗时几乎只取决于整个流程中最慢的数据导入阶段。 中间不落盘,实验三中提及如果磁盘不足,可以源端边备份边压缩,但这个可用空间是否足够是很难评估的,流备份完全不会占用源端的磁盘空间,流恢复完全不占用目标端的磁盘空间,比实验三更适用于磁盘不足的场景。
实验六 利用多核
我们之前的方法,都是使用单个 mysqldump 进程,而每个 mysqldump 进程由于软件自身不支持并行,所以之前的实验最多只能利用到服务器的一核,而生产上服务器基本上都是很多核的,如果把所有核心利用起来,那么备份速度就会很快。我使用一个 for 循环可以解决这个问题。
如果要编写为备份脚本,大概如下:
mysql="mysql -uadmin -pmypassword -S database/mysql/data/3306/mysqld.sock"
mysqldump="mysqldump -uadmin -pmypassword -S database/mysql/data/3306/mysqld.sock"
database_name="sbtest"
for table in `$mysql ${database_name} -NBe 'show tables' 2>/dev/null`
do
$mysqldump ${database_name} $table --set-gtid-purged=OFF 2>/dev/null | gzip -c > $table.sql.gz &
done
while [[ "`ps -ef|grep mysqldump|wc -l`" -gt "1" ]]
do
sleep 1
done
脚本的思路是,把我的database sbtest 的所有表列出来,我有 20 张表,分 20 个独立的 mysqldump 进程遍历备份这 20 张表。
他是实验三的第一步"边备边压缩的"改进,之前这步耗时是 4m26s,现在我是 2m39s,原因是因为我把我的 CPU 用满了两个核心,而之前只用满了一核。之前的CPU使用率大概是 55%,现在的 CPU 使用率大概是 95%。这种备份方法可以让我的备份速度随着服务器 CPU 的核数增加,而几何增长。
[root@mysql01 ~]# time sh test6.sh
real 2m38.808s
user 4m30.989s
sys 0m6.222s
实验七 利用多核+管道流备份恢复
把实验七和实验四结合,那么就可以达到最高速度。
脚本大概如下:
mysql="mysql -uadmin -pmypassword -S database/mysql/data/3306/mysqld.sock"
mysqldump="mysqldump -uadmin -pmypassword -S database/mysql/data/3306/mysqld.sock"
database_name="sbtest"
for table in `$mysql ${database_name} -NBe 'show tables' 2>/dev/null`
do
$mysqldump ${database_name} $table --set-gtid-purged=OFF 2>/dev/null | ssh root@mysql02 "cat - | mysql sbtest" &
done
while [[ "`ps -ef|grep mysqldump|wc -l`" -gt "1" ]]
do
sleep 1
done
执行
[root@mysql01 ~]# time sh test7.sh
real 3m44.520s
user 0m54.861s
sys 0m28.989s
总迁移耗时 = 3m45s
需要调整mysql02机器 /etc/ssh/sshd_config 的 MaxStartups 以支持更大的 ssh 连接
实验七,就是最快的方法了。
说在最后
实验七是最快的方法,但其实还是可以使他更快。如果您知道 mysqlshell 的 Dump&Load 为什么比任何逻辑备份工具都快,你就能明白为什么我说 mysqldump 还能更快,这里我不直接说,请读者自行阅读文章末尾的参考文献,里面有讲 mysqlshell 的 Dump&Load 的原理。
在生产上我更倾向于使用实验六的变异方法,利用多核导出多个表并用 lz4 压缩,并且流备份到目标端服务器,但不流恢复。分两阶段走,先备份再导入,并不会增加太多的耗时,换来的好处是,让我们发生导入出错时更好地好排查和处理,不需要重新全量再来一次。还有,我们目标端经常不是 MySQL,你以为我为什么迁移 MySQL,我们是迁移到国产数据库上🙂,所以不一定能流恢复。
如果数据量太大,mysqldump 并不是最好的选择,但如果您已经确认要使用 mysqldump 来做数据迁移了,可以考虑一下本文的内容再加上您的方法,加速整个迁移过程,少熬夜,身体健康。
Enjoy MySQL!
参考
https://mysqlserverteam.com/mysql-shell-dump-load-part-1-demo/
https://mysqlserverteam.com/mysql-shell-dump-load-part-2-benchmarks/
https://mysqlserverteam.com/mysql-shell-dump-load-part-3-load-dump/
https://mysqlserverteam.com/mysql-shell-8-0-21-speeding-up-the-dump-process/
