






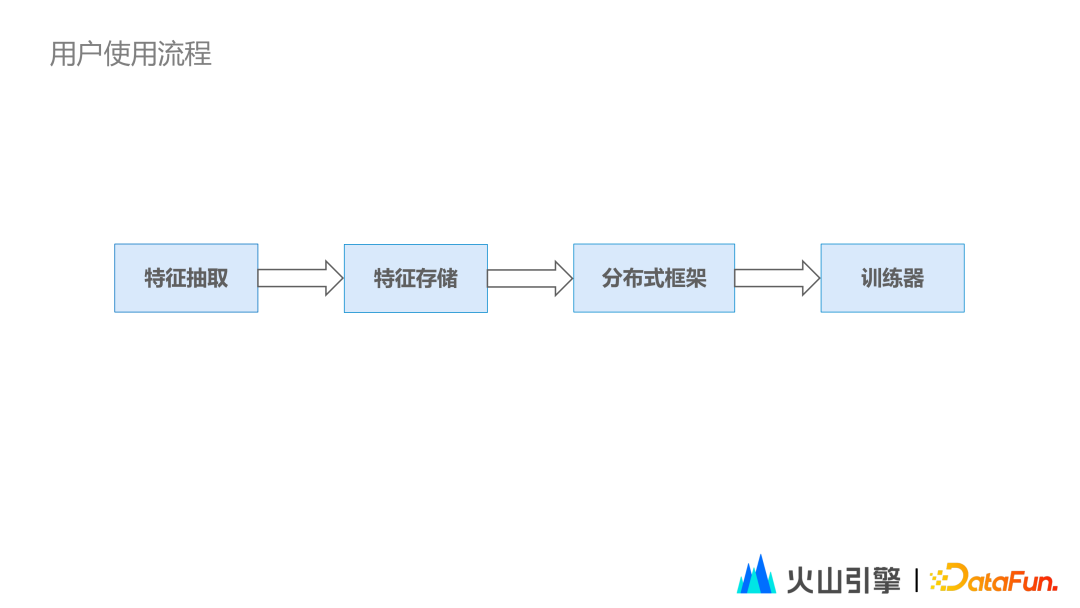
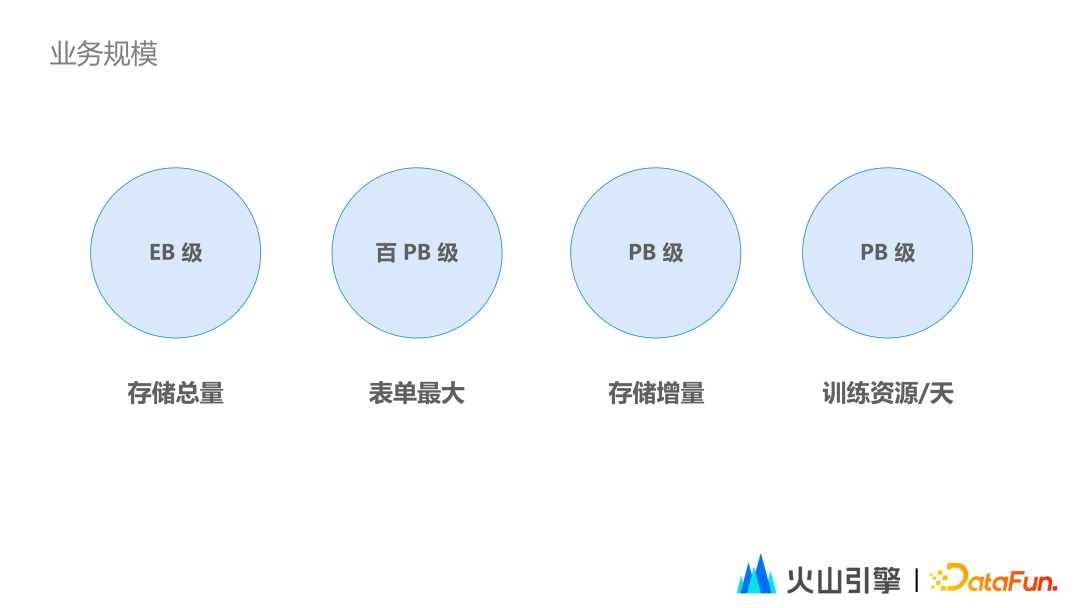
导读 随着业务的发展,字节跳动特征存储已到达 EB 级别,日均增量 PB 级别,每天训练资源量级为百万 Core。随之而来的是内部业务方对原始数据存储、特征回填需求、降低成本、提升速度等需求的期待。本次分享将围绕问题背景、选型 & Iceberg 简介、基于 Iceberg 的实践及未来规划展开。
全文目录如下:
1. 问题背景
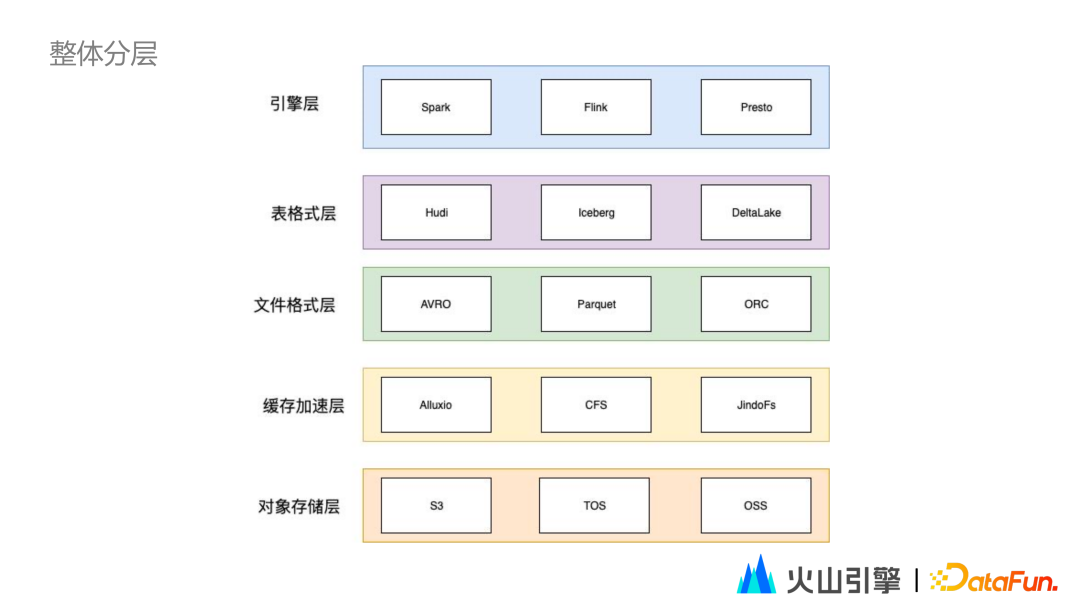
2. 选型 & Iceberg 简介
3. 基于 Iceberg 的实践
4. 未来规划
分享嘉宾|刘纬 字节跳动 火山引擎云原生计算研发工程师
编辑整理|王吉东 昆仑数据
出品社区|DataFun
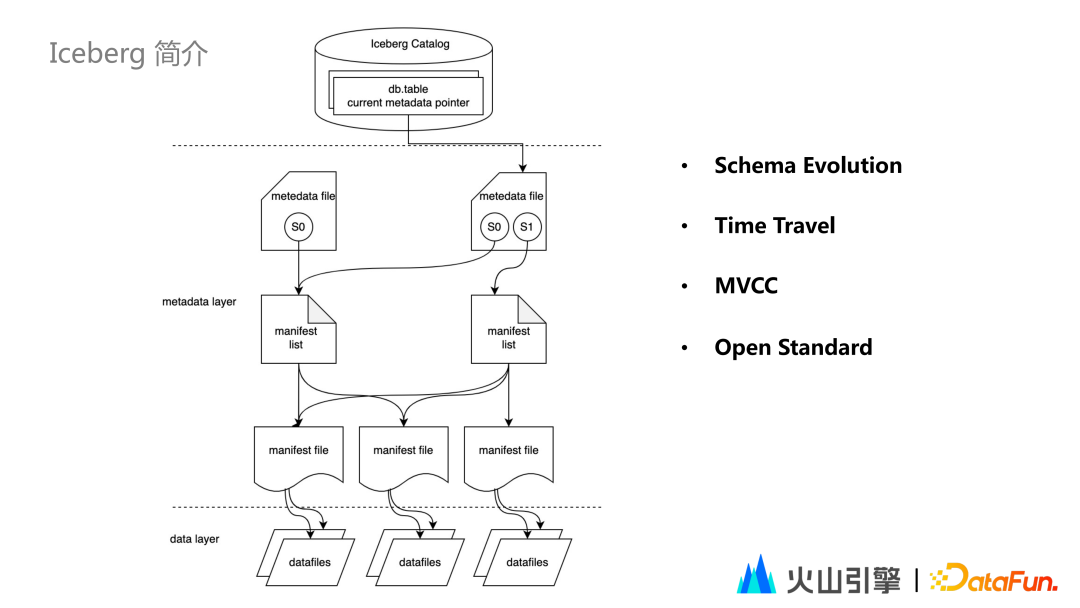
Iceberg Catalog 共有8种实现方式,包括 HadoopCatalog,HiveCatalog,JDBCCatalog,RestCatalog 等 不同的实现方式,其底层存储信息会略有不同;RestCatalog 方式无需对接任何一种具体的存储,而是通过提供 Restful API 接口,借助 Web 服务实现 Catalog,进一步实现了底层存储的解耦。
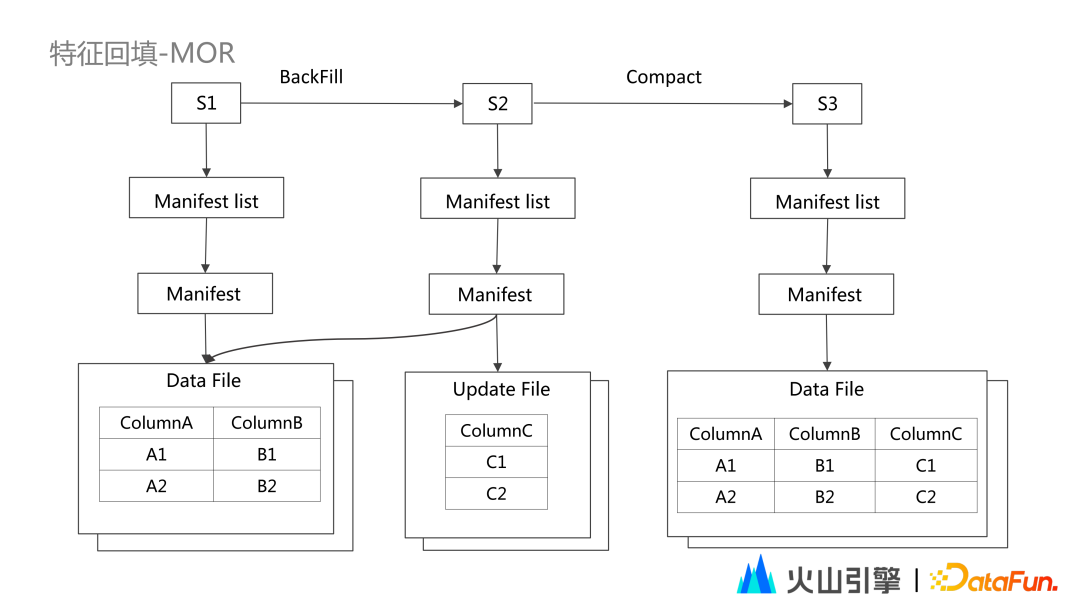
Snapshot 是快照信息,表示表在某一时刻的状态;用户每次对 Table 进行一次写操作,均会生成一个新的 SnapShot。 Manifestlist 是清单文件列表,用于存储单个快照的清单文件。 Manifestfile 是存储的每个数据文件对应的清单文件,用来追踪这个数据文件的位置、分区信息、列的最大最小值、是否存在 null 值等统计信息。
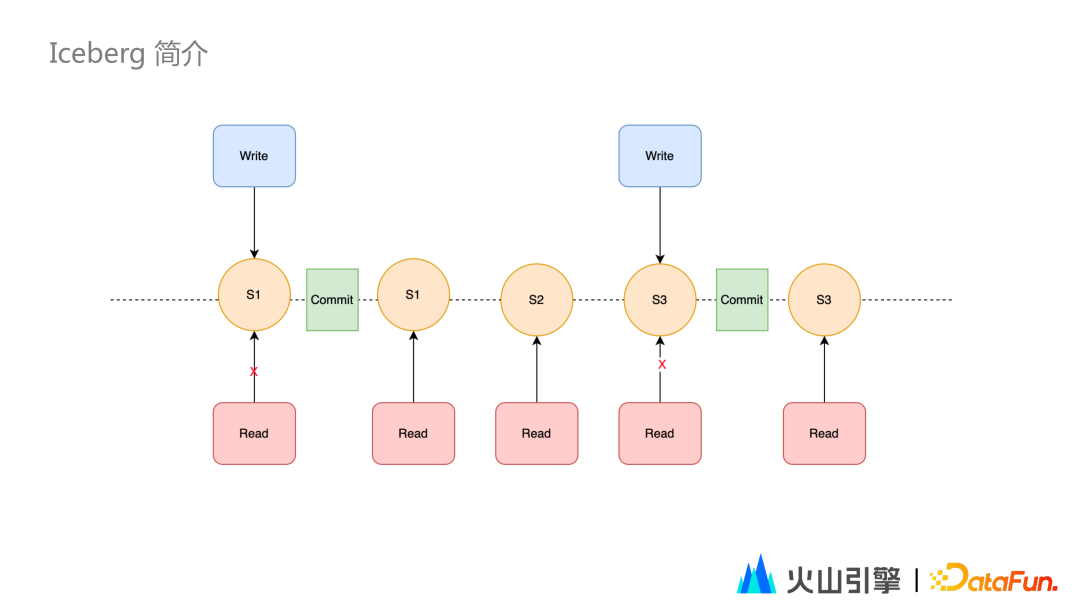
每次 Iceberg 的写操作,只有发生 commit 之后,才是可读的;如有多个线程同时在读,但一部分线程在写,可以实现:只有 commit 完整的数据之后,对用户的读操作才能被用户的读线程所看到,实现读写分离。 例如上图中,在对 S3 进行写操作的时候,S2、S1 的读操作是不受影响的;此时 S3 无法被读到,只有 commit 之后 S3 才会被读到。此时 Current Snapshot 会指向 S3。 Iceberg 默认从最新 Current Snapshot 读取数据;如果读更早的数据,可指定对应的Snapshot 的 id ,实现数据回溯。
写操作:记录当前元数据的版本——base version,创建新的元数据以及 manifest 文件,原子性将 base version 替换为新的版本。 原子性替换:原子性替换保证了线性历史,通过元数据管理器所提供的能力,以及 HDFS 或本地文件系统所提供的原子化 rename 能力实现。 冲突解决:基于乐观锁实现,每一个 writer 假定当前没有其他的写操作,对表的 write 进行原子性的 commit,若遇到冲突则基于当前最新的元数据进行重试。
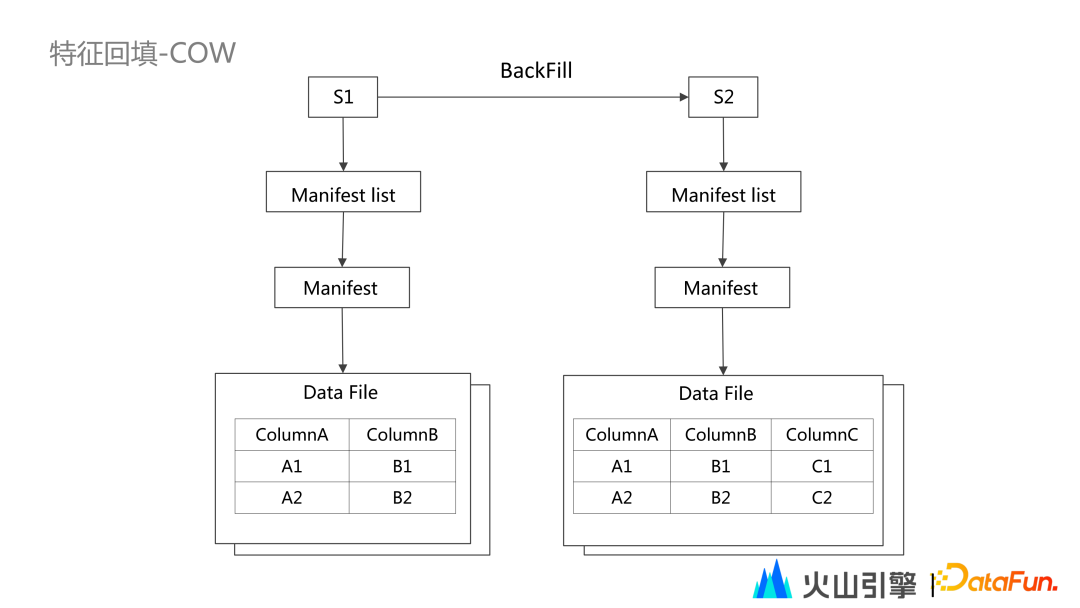
读写放大严重。 存储空间浪费。 读取逻辑简单。 写入耗费更多资源。 读取无需额外计算资源。
没有读写放大。 节省存储空间。 读取逻辑复杂。 写入耗费较少资源。 绝大多数场景,不需要额外资源。

问答环节
Q2:为什么字节选择 Iceberg 而不是 Hudi?如何看待未来数据湖的发展?


分享嘉宾
INTRODUCTION

刘纬
字节跳动
火山引擎云原生计算研发工程师
本科就读于北邮,硕士就读于中科院,五年半大数据及云原生研发从业经验,先后就职于百度,字节跳动,目前在字节跳动从事云原生批式计算研发工作,关注方向:大数据+云原生相关。
▌2023数据智能创新与实践大会
4大体系,专业解构数据智能
16个主题论坛,覆盖当下热点与趋势
70+演讲,兼具创新与最佳实践
1000+专业观众,内行人的技术盛会
欢迎大家,扫码加好友,限时领取8折购票优惠(立减¥1000)👇


👇点击阅读原文直达线下大会官网
文章转载自DataFunTalk,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
