最近因为项目期,很久没有更新了,以后会尽量更新上来,今天带来的话题是,串行流her并行流的区别,和什么场景使用那种类型的流,对于技术而言,没有什么好技术或者坏技术,就算是效率不高的技术简称 “坏技术”。跟特定的场景搭配也是好技术。同理,好技术跟不同的场景搭配,也不见的效率杠杠的。所以场景为先,技术为后,两者搭配才是宗旨。
一 前言
其实一开始也没有 并行流及串行流。完全是jdk8以后除了stream的API。才引进了并行流及串行流的概念
二 是什么
流有串行和并行两种,串行流上的操作是在一个线程中依次完成,而并行流则是在多个线程上同时执行。并行与串行的流可以相互切换:通过 stream.sequential() 返回串行的流,通过 stream.parallel() 返回并行的流。相比较串行的流,并行的流可以很大程度上提高程序的执行效率。
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。Java 8 中将并行进行了优化,我们可以很容
易的对数据进行并行操作。Stream API 可以声明性地通过 parallel() 与 sequential() 在并行流与顺序流之间进行切换。
三 并行流的概述
举例
串行流
myList.stream().sum();
改为并行流
myList.parallelStream().sum();或者myList.stream().parallel.sum();
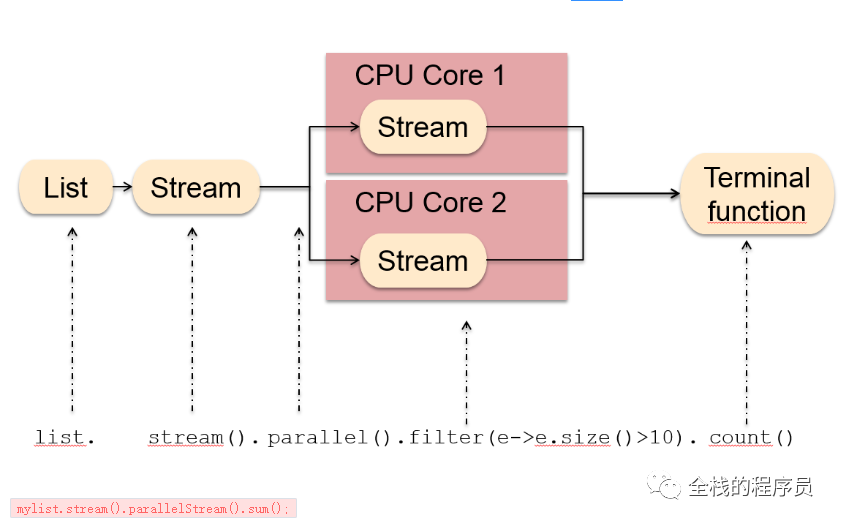
过程如下,并行流做了拆分
四 使用场景
这样就可以成功的变为并行程序,所以将一个计算扩展到线程和CPU内核上并可用很容易就可以实现。但是我们都知道,多线程和并行处理的开销很大,所以重点是什么时候使用并行流,什么时候使用串行流才能获得更好的性能。
首先,让我们看看在幕后发生的事情。parallel stream 使用的是 Fork/Join 框架进行处理的,这意味着 stream 流的源会被拆分并移交给 fork/join 池中执行。
首先,我们找到了要考虑的第一点:并非所有的stream的源会像其它的stream的源一样可拆分。例如:ArrayList的内部实现是数组,由于可以通过计算出中间元素的索引来拆分,所以拆分这样的源会非常容易;假如使用LinkedList,则拆分数据会复杂的多:该实现必须遍历第一个条目中的所有元素,以便找到可以拆分的元素,所以LinkedList是并行流中性能差的例子。
第二点:拆分集合、管理 Fork/Join 任务、对象创建及 GC 也是算法上的开销,当且仅当在CPU核心上可简单完成或者集合足够大时,才值得这样做。数据量不大不建议。
第三点:由于管理开销,在单核计算机上的并行流始终比串行流的性能差。越多越好:实际上,这句话并不是在所有情况下都正确。例如:集合太小且CPU核心启动时处于节能模式进而导致CPU无事可做。
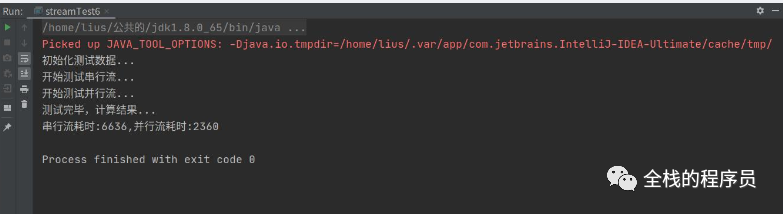
五 效率举例
package com.lius.stream;import java.util.List;import java.util.UUID;import java.util.concurrent.TimeUnit;import java.util.function.BiFunction;import java.util.stream.Collectors;import java.util.stream.Stream;/*** 串行流与并行流性能比较*/public class streamTest6 {public static void main(String[] args) {//初始化1千W条随机数据System.out.println("初始化测试数据...");List<UUID> datas= Stream.iterate(UUID.randomUUID(), t->UUID.randomUUID()).limit(10000000).collect(Collectors.toList());//开始测试串行流System.out.println("开始测试串行流...");long streamStartTime = System.nanoTime();//纳秒datas.stream().sorted().count();long streamEndTime = System.nanoTime();//纳秒//开始测试并行流System.out.println("开始测试并行流...");long paralStreamStartTime = System.nanoTime();//纳秒datas.parallelStream().sorted().count();long paralStreamEndTime = System.nanoTime();//纳秒System.out.println("测试完毕,计算结果...");BiFunction<Long, Long,Long> workMillionTime = (start,end)->TimeUnit.NANOSECONDS.toMillis(end-start);long streamTime = workMillionTime.apply(streamStartTime,streamEndTime);//计算串行耗时long paramStreamTime = workMillionTime.apply(paralStreamStartTime,paralStreamEndTime);//计算并行耗时//串行并行耗时测试结果System.out.println(String.format("串行流耗时:%d,并行流耗时:%d",streamTime,paramStreamTime));}}