




作为【推荐系统】系列文章第二十二讲,将以 “Domain-Aware DNN” 作为今天的主角,JD团队在《DADNN: Multi-Scene CTR Prediction via Domain-Aware Deep Neural Network》提了一种domain-aware DNN介绍,这个工作提供了一种新的多场景联合优化算法。
特别介绍:超单体路径是推荐系统精排模型一个核心的迭代方向,主要的方式为多目标、多场景、多模块;主要路径是 ESMM->MMOE->PLE 多目标路径,进一步的DADNN->DBMTL1/2/3->STAR,我称之为多业务路径;这条路径下,超单体的叫法其实有些问题,因为从单体到超单体太广泛了,很难找到一个持续迭代的视角,或者找到多个路径之间的关系;这条路径的本质是引入横向的信息来增强单一模块;

模型结构
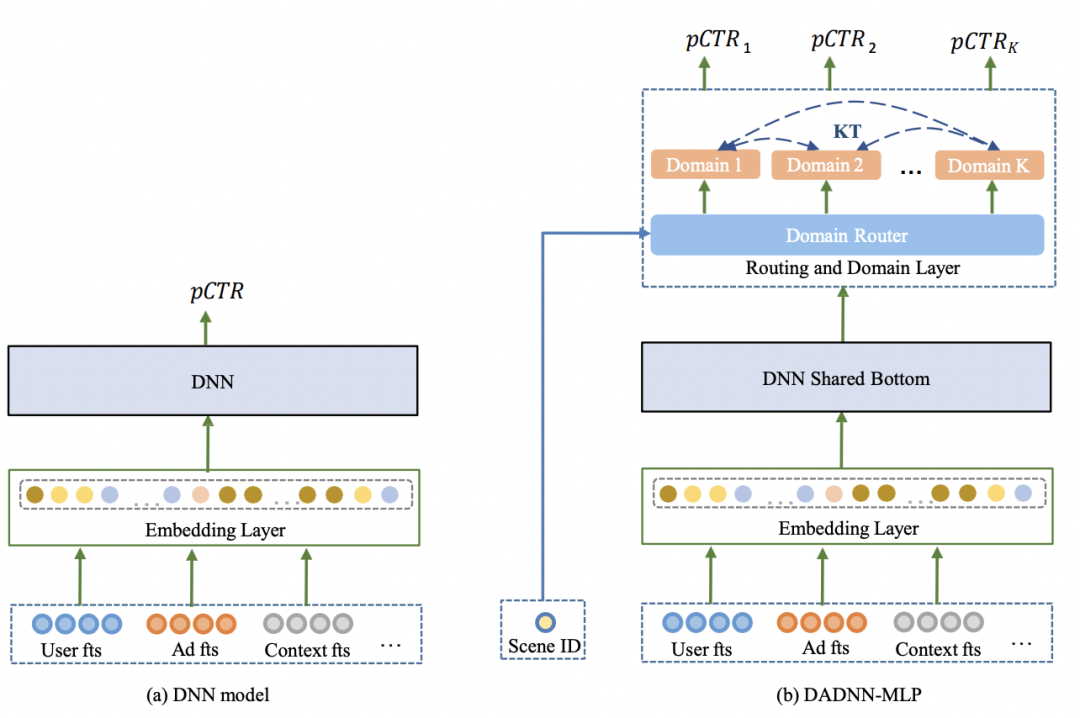 上图为模型结构展示(fts-features)。(a) DNN model,它仅会考虑单个场景 (b) DADNN-MLP model,它会进一步考虑对于每个单独场景裁减出的差异特性。routing layer会使用关于scene id的一个wide input来区分场景。KT表示在多个场景间的内部知识迁移(internal knowledge transfer) 。
上图为模型结构展示(fts-features)。(a) DNN model,它仅会考虑单个场景 (b) DADNN-MLP model,它会进一步考虑对于每个单独场景裁减出的差异特性。routing layer会使用关于scene id的一个wide input来区分场景。KT表示在多个场景间的内部知识迁移(internal knowledge transfer) 。
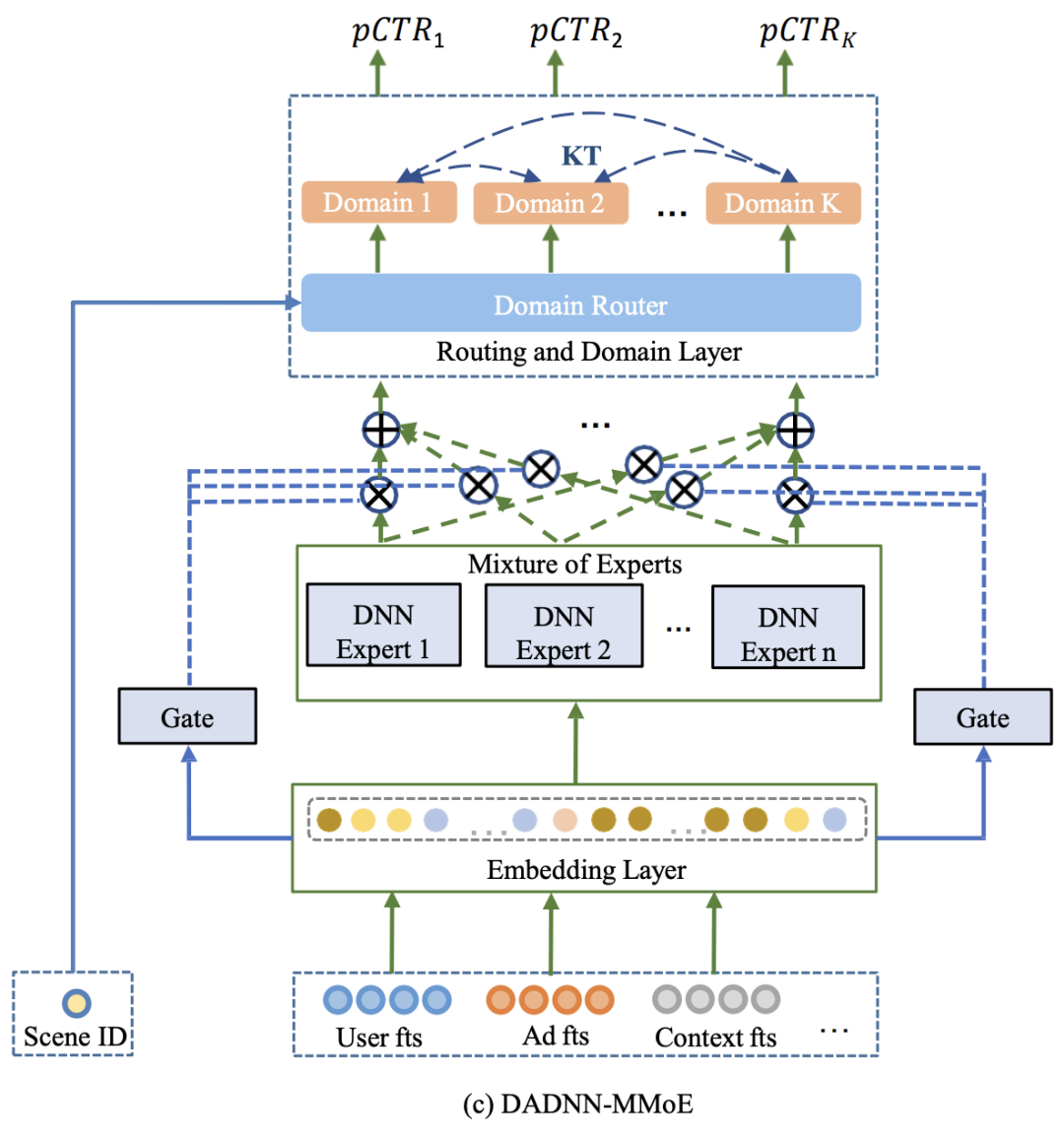
(c)DADNN-MMoE model,它引入了multi-gage mixture-of-experts来替换hard shared-bottom block。gate的weights允许为每个单独scene进行差异化representations。
Routing & Domain Layer
如果遵循相同的分布,独立场景的数据很少。为了减小跨场景的domain shift,routing layer会将通过场景来将样本划分给各自的domain layer,这样,对于对于每个独立的场景可以进行裁减出差异的representations。routing layer会通过一个scene id的wide input来区分场景。当在线进行serving时,对于每个场景来说只有一个domain layer会激活。routing和domain layer如图(b)和图(c)所示。更特别的,每个场景具有一个domain layer,它只会使用它自己的数据来调整模型参数。为了这个目的,domain layer可以来缓解引入多个数据分布带来的效果退化。给定一个dataset ,我们的模型的objective function定义如下:
其中:
是在training set的total loss。它的公式为:其中:
是第k个场景的loss 是它相应的weight K是场景号
通过探索,可以发现当将动态地设置为第k个场景的样本百分比时效果最好。特别的,通常定义为cross-entropy loss function:
其中:
是第k个场景样本的size 是第i个实例的ground truth 是第k个domain layer的output,它表示样本被点击的概率
Knowledge Transfer
尽管routing和domain layer可以缓和domain shift,domain layer对于流量有限的场景可能会训练得不够充分。另外,在实验中,这些场景都是特定比较相似的feeds。为了这个目的,论文提出了一个knowledge transfer模块,它位于每两个场景间,允许综合知识交互(knowledge interactions)和信息共享(information sharing)。一旦这些来自teacher domain classifier的knowledge被生成,它可以通过其它cross-entropy loss来指导其它domain layers。另外,论文会描述作者提出的knowledge transer方法。给定一个dataset ,我们的模型的objective function如下所定义:
特别的:是knowledge matching loss,它表示pairwise probabilistic prediction mimicking loss,它的定义如下:
其中:
和q(x)分别表示teacher network和student network。 是classifier p到q的weight,是teacher样本的size。在实验中,设置为0.03。
实验
在本节中,会详细描述实验部分。作者会从公司中的在线广告系统中收集到的数据集来进行实验。另外,作者设计实验来验证routing和domain layer,MMoE模块和knowledge transfer的的效果。最后,会共享在线serving的结果和技术。

Metrics
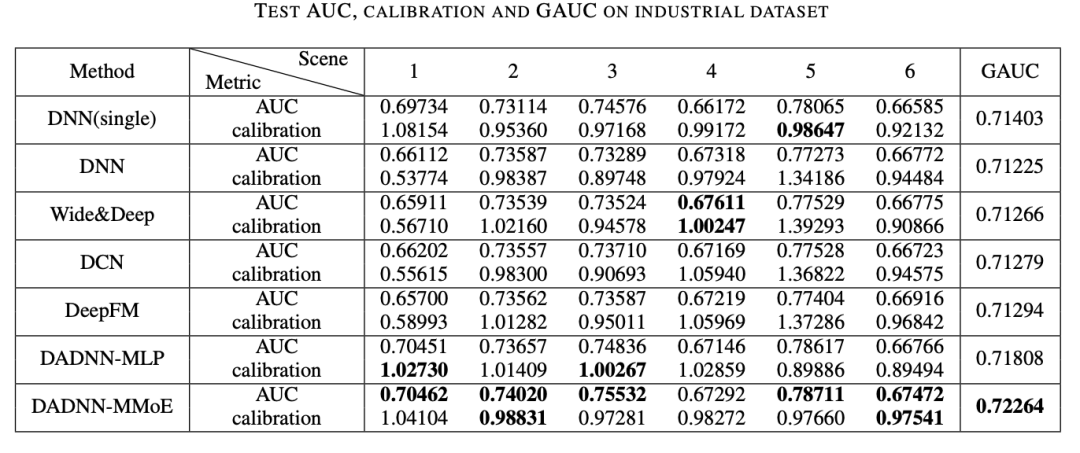
AUC是在线CTR预估领域广泛使用的metrics。它表示:一个CTR predictor对于随机选择一个postive item高于一个随机选择negative item的概率。由于私有场景的数据分布通常是多样的,我们会使用一个派生自GAUC的metric,它表示了一个通过将每个场景的样本group计算而来的weighted average AUC。一个基于impression的GAUC计算如下:
其中,weight是每个场景的曝光数。该metric会measures intra-scene order的好坏,并表明了在广告系统中的在线效果更相关。特别的,作者使用calibration metric来measure模块稳定性,因为CTR的accurate prediction对于在线广告的成功来说是必要的。它是average estimated CTR和empirical CTR之间的ratio:
calibration = pCTR / CTR
calibration与1的差异越小,模型越好。
更多干货获取
Kaggle竞赛2022年鉴:公众号回复 kaggle2022
获取推荐系统知识卡片:公众号回复 推荐系统
获取数据科学速查表(传统CTR、深度学习CTR、Graph Embedding、多任务学习):公众号回复 速查表
获取历届腾讯广告算法大赛答辩PPT:公众号回复 腾讯赛
获取KDD Cup历史比赛合集:公众号回复 KDD2020
获取


