




作为【推荐系统】系列文章第二十一讲,将以 “Co-Action Network” 作为今天的主角,阿里团队在CAN: Feature Co-Action for Click-Through Rate Prediction中提出了CAN模型,这个工作提供了一种新的特征交互思路,在「特征工程上手动特征交叉」和「模型上自动特征交叉」之间做了折衷,也是「记忆性」和「泛化性」的互补。可以认为是开创了特征交互的新路线。
CTR预估中的特征交叉
在广告系统中,一个user u在一个ad m上的点击的predicted CTR 计算如下:
其中:
是包含了user features的集合,包含了:浏览历史、点击历史、user profile feature等。 是:items features的集合 User和Item features通常是unique IDs 表示size d的embedding,它会将sparse IDs映射到可学习的dense vectors上作为inputs DNNs。
除了这些一元项(unary terms)外,之前的工作会将feture interaction建模成二元项(binary terms):
其中:
表示了user feature 和item feature 之前的交叉。
模型可以从feature interaction受益,因为会存在feature共现性,如之前的示例:“啤酒与尿布”。因此,如何有效建模feature interaction对提升效性非常重要。
在仔细回顾之前方法,可以发现:不管是将feature interaction可以作为weights,还是同时学习隐式相关性和其它目标(满意度等),都会产生不满意的结果。学习feature interaction的最直接方式是:将特征组合(feature combinations)作为新特征,并为每个特征组合直接学习一个embedding,例如:笛卡尔积(catesian product)。笛卡尔积可以提供独立的参数空间,因此对于学习co-action信息来提升预估能力来说足够灵活。
然而,存在一些严重缺点。
首先:存在参数爆炸问题。笛卡尔积的参数空间会产生size N的两个features,可以从展开成,其中:D是embeddings的维度,它会对在线系统带来主要开销。 另外,由于笛卡尔积会将<A,B>和<A,C>看成是完全不同的features,在两个组合间没有信息共享,这也会限制representation的能力。
考虑到笛卡尔积和计算的服务有效性,文章引入一种新方式来建模feature interaction。如下图a所示,对于每个feature pair,它的笛卡尔积会产生一个新的feature和相应的embedding。由于不同的feature pairs会共享相同的feature,在两个feature pairs间存在一个隐式相似度,这在笛卡尔积下会被忽略。如果隐式相似度可以被有效处理,在这些pairs间的feature interaction可以使用更小的参数规模进行有效和高效建模。受笛卡尔积的独立编码的启发,首先会将embedding的参数和feature interaction进行区分,以便避免相互干扰。考虑DNNs具有强大的拟合能力,作者设计了一个co-action unit,它可以以一个micro-network的形式对feature embeddings进行参数化。由于不同的feature pairs会共享相同的micro-network,相似度信息会被学到,并自然地存储到micro-network中,如下图(b)所示。
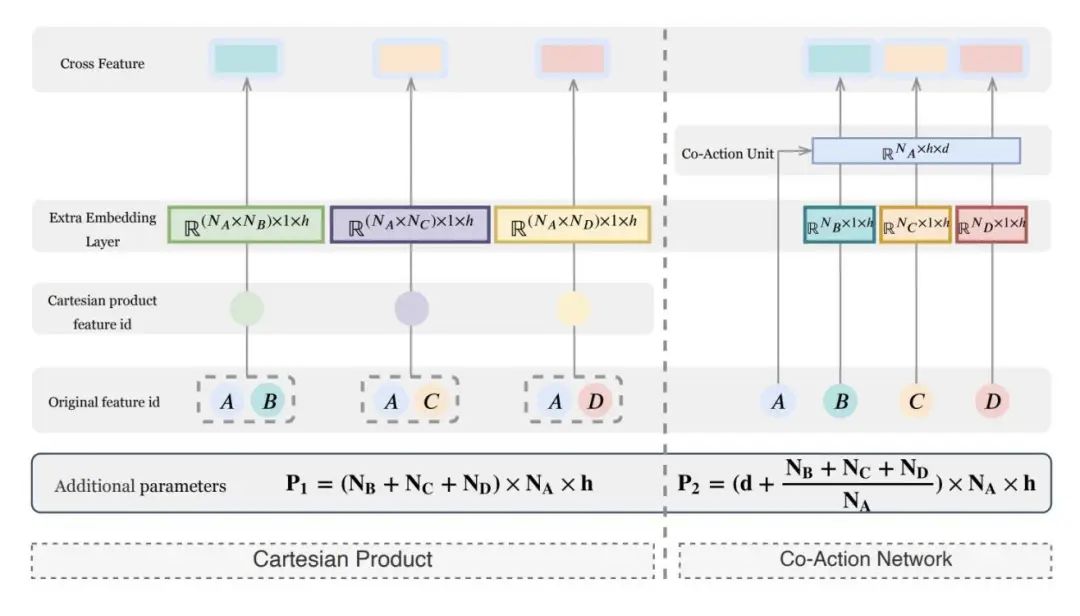
上图从cartesian product到co-action network的演进,其中,A,B,C与D表示4种feature。分别表示A,B,C,D的特征数目。h是feature embedding的维度,d是从co-action unit的output的维度。在图中,使用A与其它3个features进行交叉。
Co-Action Network
在本节中,作者提出了CAN来有效捕获feature interaction,它会首先引入一个可插入的模块co-action unit。该unit对于embedding和feature interaction learning的参数会进行区别。特别的,它会由来自raw features的两个side info组成,例如:induction side和feed side。induction side被用于构建一个micro-MLP,而feed side为它提供input。另外,为了提升更多非线性,以及深度挖掘特征交叉,多阶增强和multi-level独立性会被引入。
结构总览
CAN的整个结构如下图所示:

上图Co-Action Network的整体框架。给定target item和user features,embedding layer会将sparse features编码成dense embeddings。一些选中的features会被划分成两部分:,它它是co-action unit的组成部分。会将micro MLP进行参数化,则作为input使用。co-action unit的output,会与公共feature embeddings一起,被用来做出最终的CTR预估。一个user和target item的features U和M被会以两种方式feed到CAN中。
第一种方式下,他们会使用embedding layer被编码成dense vectors 和 ,并分别进一步cancatenated成和。 第二种方式下,他们会从U和M中 选择一个subset 和,使用co-action unit来建模特征交叉:。
co-action unit的详细解释会在下一节详细介绍,CAN的公式如下:
其中:
表示在模型中的参数, 是点击行为的预估概率
click信息的ground truth被表示为。最终对prediction和label 间的cross-entropy loss function进行最小化:
Co-Action Unit
总的来说,co-action unit为每个feature pair提供一个独立MLP,称为micro-MLP,它的输入有:由feature pair提供的带weight、bias、MLP的input。
对于一个指定的user feature ID ,使用参数查询(parameter lookup)来获得可学习参数 , 而对于item feature ID 对应获取的是
接着,会被reshape,为micro-MLP划分成weight matrix和bias vector。该process可以公式化成:
其中:
和表示micro-MLP的第i个layer的weight和bias 表示concatenation操作 L决定了micro-MLP的深度 则可以获得变量的size
该过程的可视化如下图左侧所示:
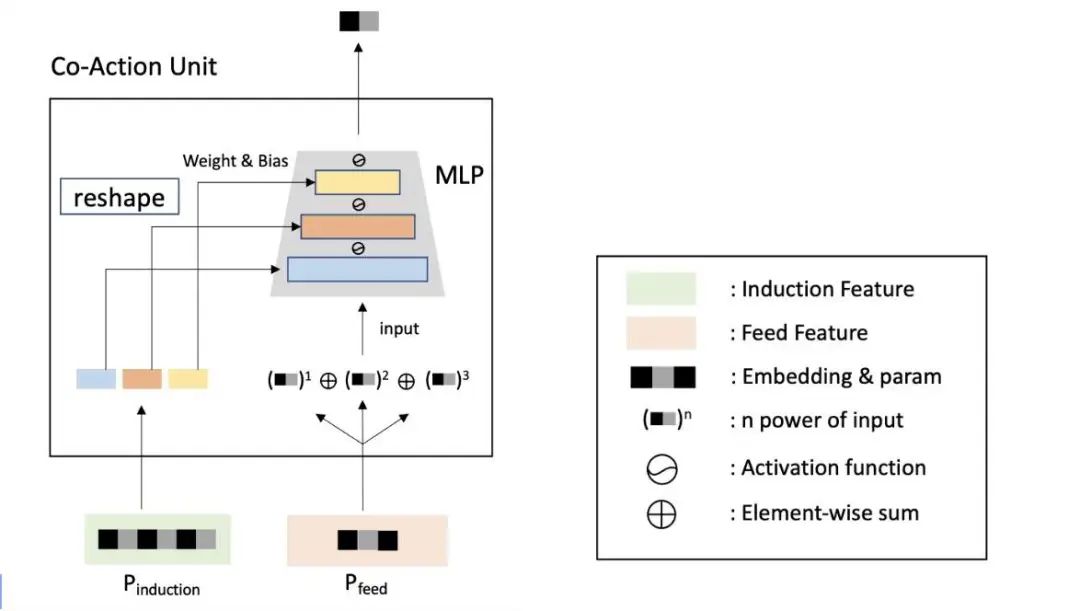
接着被feed到micro-MLP,特征交叉可以通过每个layer的output的concatentation来实现:
其中:
表示了矩阵乘法 表示activation function H表示co-cation unit,它具有vector input 和,而非使用原始符法F,它的inputs是features 和。
对于序列features,比如:用户行为历史 ,co-action unit会被应用到每个点击行为上,在序列后跟着一个sum-pooling:
在论文的实现中,会获得来自item features的信息,而则来自user features。然而,可以充当micro-MLP的参数,也一样。经验上,在广告系统中,candidate items是所有items的很小一部分,他们的数目要小于在用户点击历史中的items。这里,作者选择作为micro-MLP参数来减小总参数量,它使得学习过程更容易且稳定。
注意:micro-MLP layers的数目依赖于学习的难度。经验上,一个更大的feature size通常需要更深的MLP。实际上,FM可以被看成是CAN的一个特殊case,其中:micro-MLP是一层的1xD matrix,没有bias和activation function。
对比其它方法,提出的co-action unit具有至少三个优点:
首先,之前的工作使用的都是关于inter-field交叉的相同的latent vectors,而co-action unit则使用micro-MLP的计算能力,将两个组成特征和进行动态解耦,而非使用一个固定的模型,这提供了更多的能力来保证:两个field features的分开更新。 第二,可以学习一个更小规模的参数。例如:考虑上具有N个IDs的两个features,笛卡尔积的参数规模可以是:,其中,D是embeddings的维度。然而,通过使用co-action unit,该scale会递减到上,而是在co-aciton unit中的的维度。更少参数不仅有助于学习,也可以有效减小在线系统的开销。 第三,对比起笛卡尔积,co-action unit对于新的特征组合具有一个更好的泛化。对比起笛卡尔积,给定一个新的特征组合(feature combination),只有在这之前,只要两侧embeddings在这之前被训练,co-action unit仍能工作。
多阶增强
之前的feature基于1阶features形成。然而,特征交叉可以通过高阶进行估计。考虑到micro-MLP的非线性,尽管co-action unit可以隐式学习高阶特征交叉,因为特征交叉的稀疏性导致学习过程很难。结尾处,论文会显式引入高阶信息来获得一个多项式输入。可以通过使用micro-MLP到的不同阶上来实现:
其中:
C是orders的数目
使用tanh来避免由高阶项带来的数目问题。多阶增强可以有效提升模型的非线性拟合能力,无需带来额外的计算和存储开销。
Multi-Level独立性
学习独立性是特征交叉建模的一个主要关注点。为了确保学习的独立性,提出了一种基于不同角度的3-level策略。
第一层,参数独立性,它是必需的。如Co-Action Unit节所示,所提方法会解决representation learning的更新和特征交叉建模。参数独立性是CAN的基础。
第二层,组合独立性,推荐使用。特征交叉会随着特征组合数目的增加而线性增长。经验上,target item features,如:“item_id”和"category_id"会被选中作为induction side,而user features则作为feed side。由于一个induction side micro-MLP可以使用多个feed sides进行组合,并且反之亦然,作者的方法可以轻易扩大模型指数的表达能力。
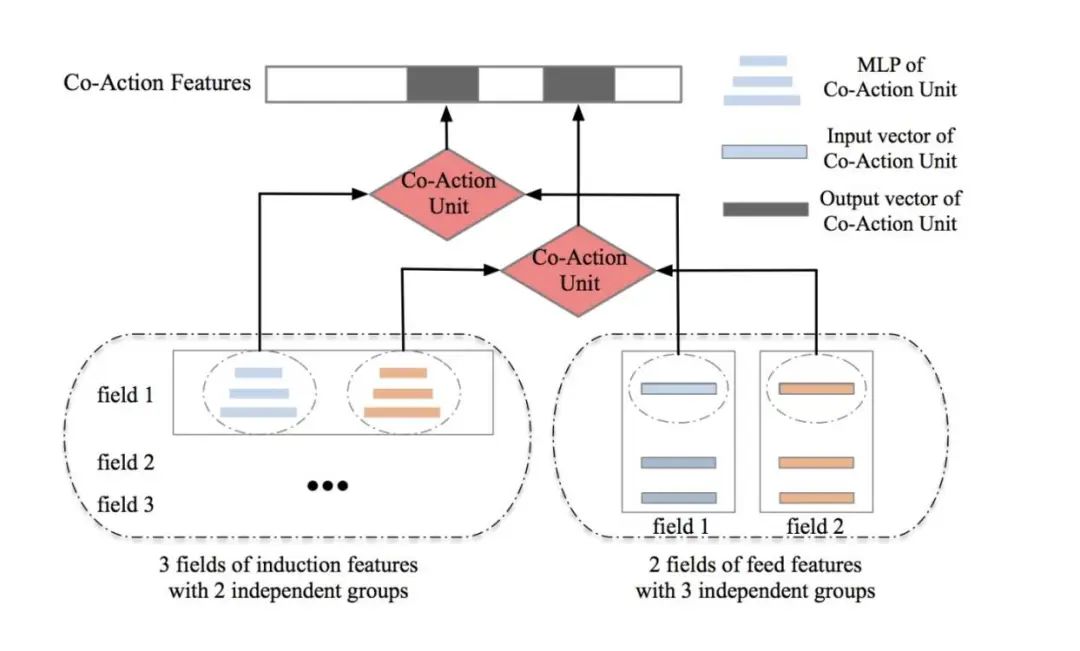
如上图(组合独立性的演示)所示,如果induction和feed sides具有Q和S个分组,特征交叉组合应满足:
其中,是第q个micro-MLP的input维度。在forward pass中,特征交叉被划分成几个部分来满足每个micro-MLP。
第3个level,阶数独立性,它是可选的。为了进一步提升特征交叉建模在多阶输入的灵活性,作者的方法会为不同orders做出不同的induction side embedding。然而,与上面等式相似,这些embedding的维度相对增加C倍。
multi-level独立性帮助特征交叉建模,同时,会带来额外的内存访问和开销。这需要在independence level和部署开销间进行tradeoff。经验上,模型使用越高的independence level,需要训练更多训练数据。在我们的实际系统中,independence的3个levels会被使用;而在公共数据集中,由于缺少训练样本,只有参数独立性会使用。
更多干货获取
Kaggle竞赛2022年鉴:公众号回复 kaggle2022
获取推荐系统知识卡片:公众号回复 推荐系统
获取数据科学速查表(传统CTR、深度学习CTR、Graph Embedding、多任务学习):公众号回复 速查表
获取历届腾讯广告算法大赛答辩PPT:公众号回复 腾讯赛
获取KDD Cup历史比赛合集:公众号回复 KDD2020
获取


