





图数据库介绍
图数据库是非关系型数据库(NoSQL)的一种类型,使用点和边的形式把数据组织保存到图引擎中,其中“点”表示实体,“边”表示实体间的关系。使用者可以通过某个顶点查询到与其相关联的所有其它顶点以及之间的关联关系,图数据库能够快速响应复杂的关联查询。目前图技术已经被广泛应用在社交媒体、风险管理、知识图谱以及物联网等场景中。
工厂内应用场景介绍
SMT 贴片是指在印刷电路板(PCB)基础上进行加工的系列工艺流程的简称,这个流程是电子组装行业中使用最广泛的技术和工艺之一,特别是在针对电子产品的离散制造场景中被大量使用。SMT 线贴片机每周会出现各种各样的计划外故障,每次故障会产生多个故障码,通过故障码的出现逻辑以及历史经验,产线工程师可以定位出现问题的组件以及故障的原因,进而找到问题的解决方案。以往整个过程需要依靠产线工程师的经验知识进行判断,但产线工程师特别是资历较浅的初级工程师需要花费大量的时间从多个不同位置的记录中找寻答案,搜索到的答案也有可能不够准确。客户希望通过在现有 OEE 系统中增加智能推荐的能力,在故障出现时,基于过去30分钟内的 error code 推荐出3种可能的故障现象描述,产线工程师从中选择出准确的故障,系统再结合图数据库和领域知识推荐出5种可能的故障模块以及故障根因的组合,最终产线工程师可以定位到准确的故障原因以及对应的解决方案。通过实现智能推荐的能力,可以辅助产线工程师快速定位并解决产线上的故障,提升整个产线的 OEE。
使用云原生图数据库的优势
更契合工厂业务数据的结构
相对于使用传统的关系型数据库,使用图数据库存储已积累的历史数据可以直接反应业务数据的含义以及数据之间的关联关系。例如贴片机包含大量的组件,其中有贴片头、PC 控制系统、供料系统以及升降台等组件。每个组件又包涵若干的零部件,例如贴片头包含吸嘴、发光板、电磁阀等。这两个部分可以保存为图数据库中的顶点,两个点之间的边表示关联关系,例如吸嘴属于贴片头。同样的结构也可以直观表示这些内容项与故障原因、原因分类、故障描述以及解决方案之间的关联关系。
更低的基础架构管理复杂度
以 Neptune 的云原生数据库在设备故障分析和排查的应用为例,能够减少工厂 IT 团队从零开始准备硬件环境、软件安装、升级修补等管理任务的工作,随着未来数据量的增加和访问频度的提升,可以充分利用云原生数据库自身提供的高扩展性和高性能的处理能力,让工厂团队更聚焦于以数据驱动业务,以数据服务应用的工作目标。
更快的答案搜索速度
针对拥有复杂关系的数据结构(例如关联关系超过100层的场景),相比使用传统的关系型数据库做联合查询(多表 Join),使用图数据库可以更快地找到目标结果。
更轻松地与云端的其它服务做进一步创新
在云端,您也可以结合面向不同业务场景的数据分析以及机器学习服务作进一步的创新。例如在本例中,我们使用了 Neptune 图引擎完成了工业知识的保存和关联查询,但在数据保存到图数据库前,还使用了 SageMaker 机器学习服务基于归因分析完成了故障码与故障描述以及故障根因之间的关联关系的分析。将处理后的数据保存到了 Neptune 中。随着知识数据的不断积累,数据科学家还可以持续使用 SageMaker 更新知识之间的关联关系。
Amazon Neptune 服务介绍
Amazon Neptune 是一项快速、可靠且完全托管式的图数据库服务,可帮助您轻松构建和运行适用于高度互连数据集的应用程序。Neptune 的核心是一个专门打造的高性能图形数据库引擎。此引擎经过优化,可存储数十亿个关系并以数毫秒的延迟查询图形。Neptune 支持流行的图形查询语言 Apache TinkerPop Gremlin、W3C 的 SPARQL 和 Neo4j 的 OpencyPher,可让您构建查询,高效地浏览高度互连数据集。Neptune 支持图形用例,如建议引擎、欺诈检测、知识图形、药物开发和网络安全。
Neptune 具有高可用性,具有只读副本、point-in-time 恢复、持续备份到 Amazon S3,以及跨可用区的复制。Neptune 提供了数据安全功能,并支持加密静态数据和传输中的数据。Neptune 是完全托管的,因此,您再也无需担心数据库管理任务,例如硬件预置、软件修补、设置、配置或备份。
解决方案架构
架构:

描述:
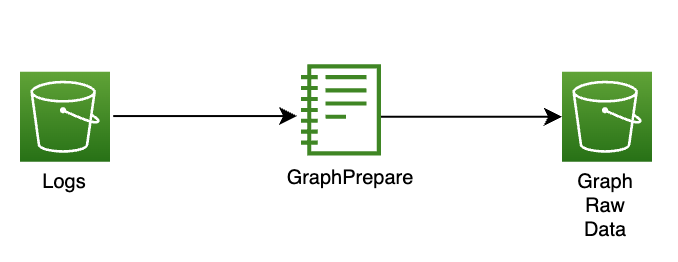
● SMT 设备在日常操作过程中会生成包含错误代码的日志,并将其存储在工厂的本地 SQL Server 中。数据传输服务器每天从 SQL 服务器调用日志数据并上传到 Amazon S3。
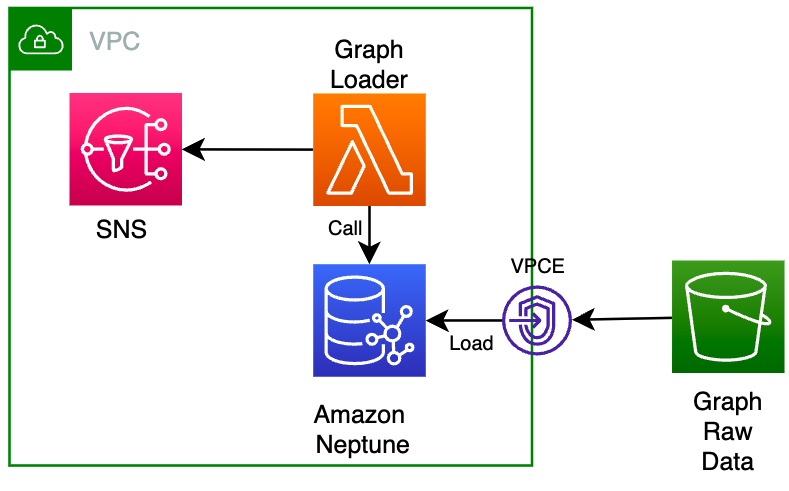
● GraphPrepare 函数根据错误代码和代码对应的模块、模块部分和根本原因、解决方案构建图数据模式。然后,操作员触发 Lambda 函数调用 Neptune API 从 S3 加载数据并构建知识图谱。
● 工程师利用 Amazon Neptune Workbench (Amazon SageMaker Notebook) 调用 Neptune 数据库来编辑基于 Gremlin Graph Model 的知识图谱。
● OEE 系统根据计划外停机事件触发对Amazon API 网关的 API 调用。API 网关会触发 Amazon Lambda 查询 Neptune 数据,找出对应 Module、Module part 和 Root cause 的错误码,然后返回给 OEE 系统。
方案部署说明
数据上传
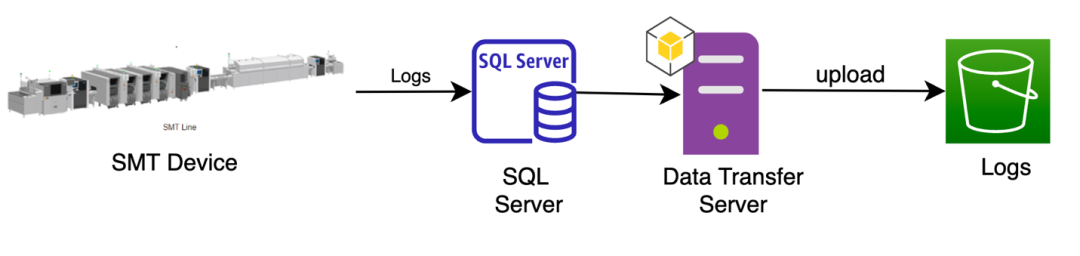
SMT 设备在日常操作中会生成日志,并将其存储在工厂的本地 SQL Server 中。数据传输服务器从 SQL 服务器获取包括错误代码数据/事件数据等信息的日志并上传到 Amazon S3。
数据转换
1)创建 S3 桶来分别存储 log raw data 和转化后符合 Neptune 格式的数据,命名为 Factory logs 和 Neptune Raw data。
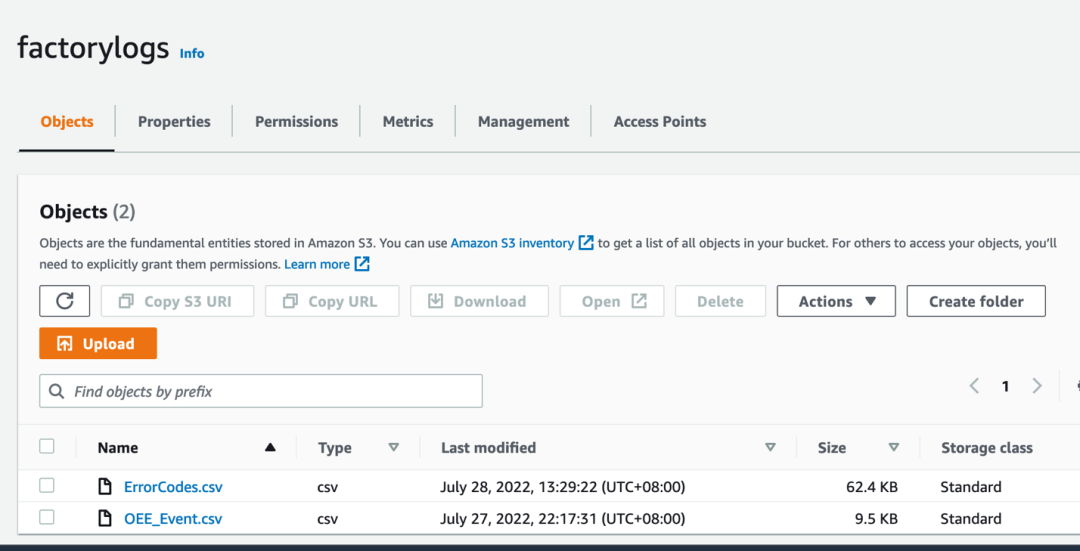
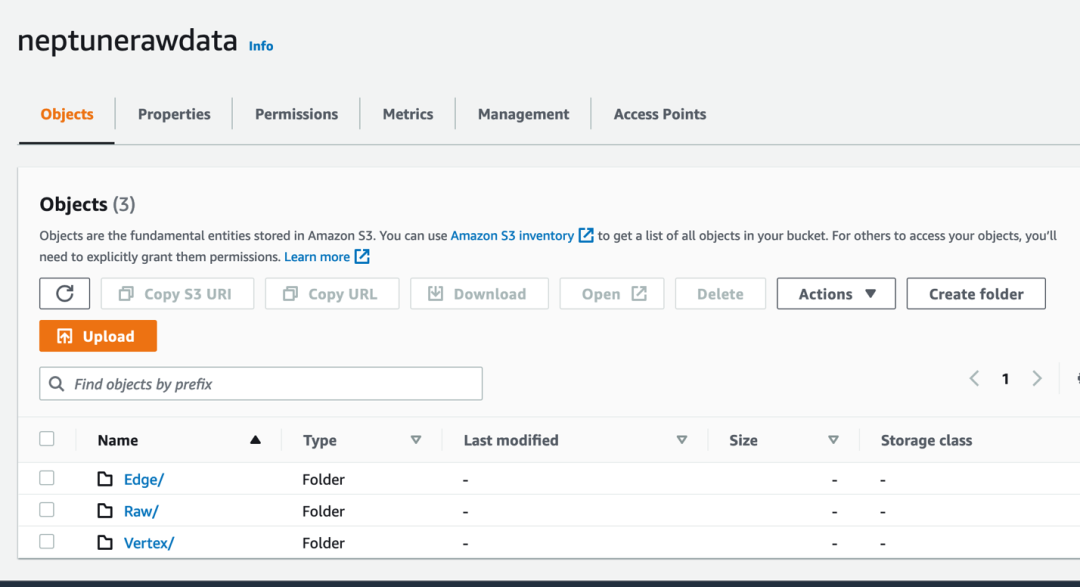
数据格式说明:
原始数据:ErrorCode 从机器产生,但是跟机器发生故障的 OEEEvent 的 root cause 不是一对一的关系,当 OEEEvent 发生的时候,需要工程师去 ErrorCode 里面对应时间段进行分析。
转化后的数据:Neptune Raw data 主要包含一系列 Vertex、Edge,定义了 ErrorCode 和 Event 的相关关系以及产线相关组成部分。
2) 创建 SageMaker notebook: GraphPrepare, 这个段逻辑是用来将工厂原数据转化为 Neptune 所需要的格式。
3 )使用 Notebook 进行数据转化
• 倒入需要的包,Boto3、Pandas、sagemaker execution_role.
#Import Sagemaker to get excution role to read from S3#Import Boto3 for S3 IO#Import Pandas for Data analysis using DataFramefrom sagemaker import get_execution_roleimport boto3import pandas as pd#Grant role to access s3role = get_execution_role()
左滑查看更多
• 定义原始数据为止
logs_bucket='factorylogs'err_codes_data_key = 'ErrorCodes.csv'err_codes_data_location = 's3://{}/{}'.format(logs_bucket, err_codes_data_key)event_data_key = 'OEE_Event.csv'event_data_location = 's3://{}/{}'.format(logs_bucket, event_data_key)
左滑查看更多
• 定义转化后数据位置
output_bucket='neptunerawdata'output_key='Raw/occurs_when.csv'output_location = 's3://{}/{}'.format(output_bucket, output_key)
左滑查看更多
• 创建 Data Frame
#Create ErrorCode Dataframedf_error = pd.read_csv(err_codes_data_location)df_error['Creation Time'] = pd.to_datetime(df_error['Creation Time'])df_error.head()#Create Event Dataframedf_event = pd.read_csv(event_data_location)df_event['Creation Time'] = pd.to_datetime(df_event['Creation Time'])display(df_event)
左滑查看更多
• 定义数据转化逻辑,(下面的代码仅供参考),使用下面两个函数去找出每次 Event 发生时前30分钟、20分钟、10分钟出现的最高的频率的 ErrorCode,整理出最高频率的 ErrorCode 与 Event 的对应关系
import datetimefrom datetime import timedeltadef dataframe_strip(dataframe: pd.DataFrame, timestamp: datetime,duration: timedelta):endtime = timestamp+durationoutputdataframe = dataframe[(dataframe['Creation Time']>timestamp)&(dataframe['Creation Time']<endtime)]return outputdataframe#Create ErrorCode and Event Mappingsdef mapping(df_error:pd.DataFrame, df_event:pd.DataFrame):df_occurs_when = pd.DataFrame(columns = ['~id','~from', '~to','~label' ,'in30:Integer','in20:Integer','in10:Integer'])id = 1for timestamp, RootCauseID in zip(df_event['Creation Time'], df_event["RottCauseID"]):#Get current event mapping error code and occuring requency in 30 minutes piece on current timesatmperror_slice = dataframe_strip(df_error,timestamp,timedelta(minutes=30))error_code = error_slice['ErrorCode'].value_counts().nlargest(1).keys().tolist()[0]in30 = error_slice['ErrorCode'].value_counts().nlargest(1).tolist()[0]#Get the "error_code" occuring requency in 20 minutes timeframeerror_slice_in20 = dataframe_strip(df_error,timestamp,timedelta(minutes=20))in20 = len(error_slice_in20[error_slice_in20['ErrorCode']== error_code])#Get the "error_code" occuring requency in 10 minutes timeframeerror_slice_in10 = dataframe_strip(df_error,timestamp,timedelta(minutes=10))in10 = len(error_slice_in10[error_slice_in10['ErrorCode']== error_code])#append to output dataframe df_occurs_when of current event mapping error code and its requencydf_occurs_when = df_occurs_when.append({'~id': 'occurs_when_{}'.format(id),'~from' : error_code,'~to' : RootCauseID,'~label':'occurs_when' , 'in30:Integer' : in30,'in20:Integer' : in20, 'in10:Integer' : in10},ignore_index = True)id = id + 1return df_occurs_when
左滑查看更多
• 执行转化逻辑并输出
#Excute the Mapping logic with df_error and df_eventoutput_df_occurs_when = mapping(df_error,df_event)display(output_df_occurs_when)#Ouptput to Rawdata Folder in out S3 Bucket for nepotune to consumeoutput_df_occurs_when.to_csv(output_location,index=False)
左滑查看更多
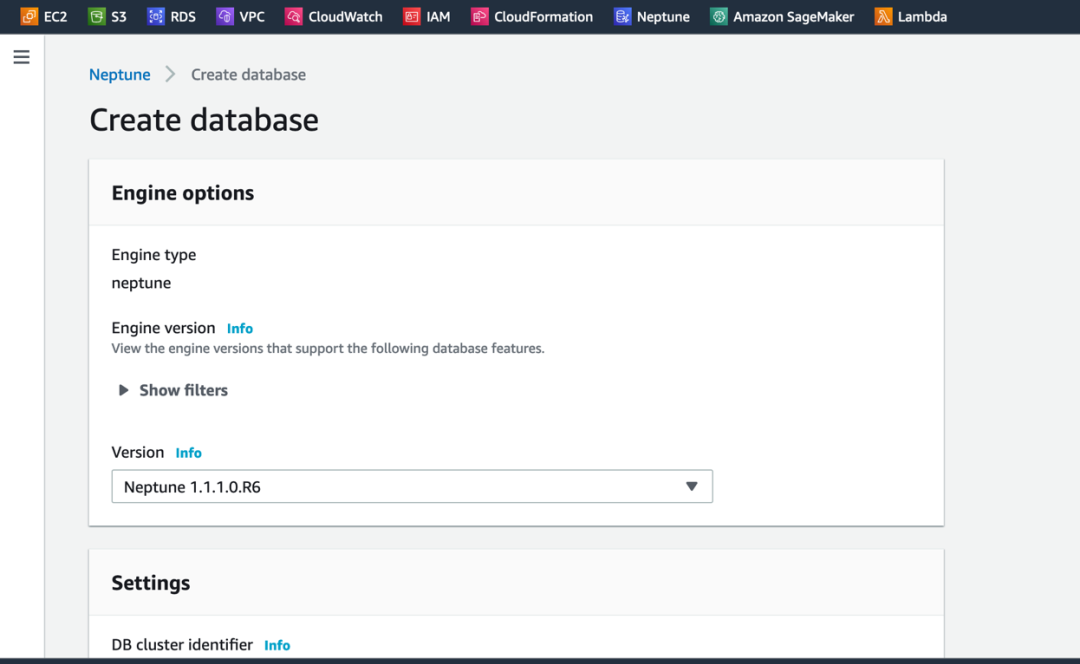
4) 创建 Neptune 图数据库
5) Create Lambda which can access the Neptune and S3 at the same time to import S3 data to Neptune. As shown as graph loader in above pic.
https://docs.aws.amazon.com/neptune/latest/userguide/bulk-load-tutorial-IAM.html and trigger the Lambda to ingest data.
图数据库查询
我们使用图数据库的 workbench 进行图数据库查询
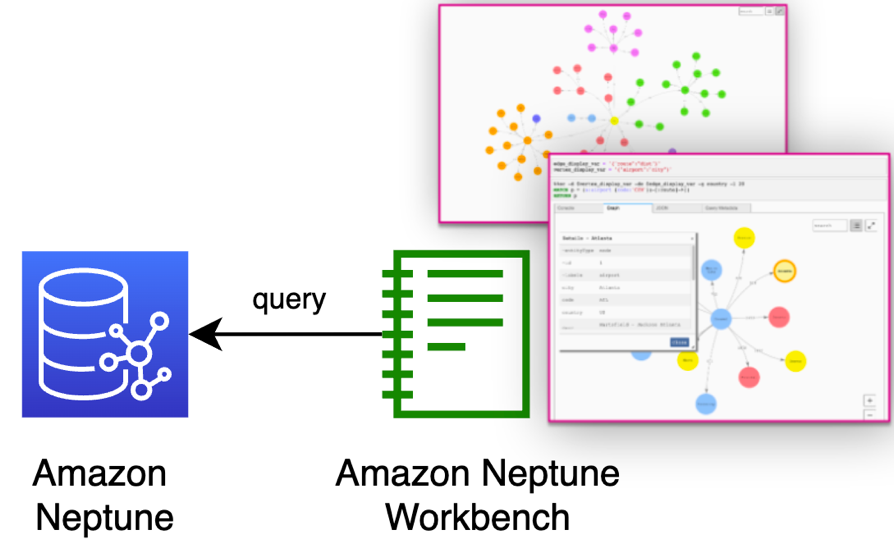
1) 创建 Neptune Workbench:
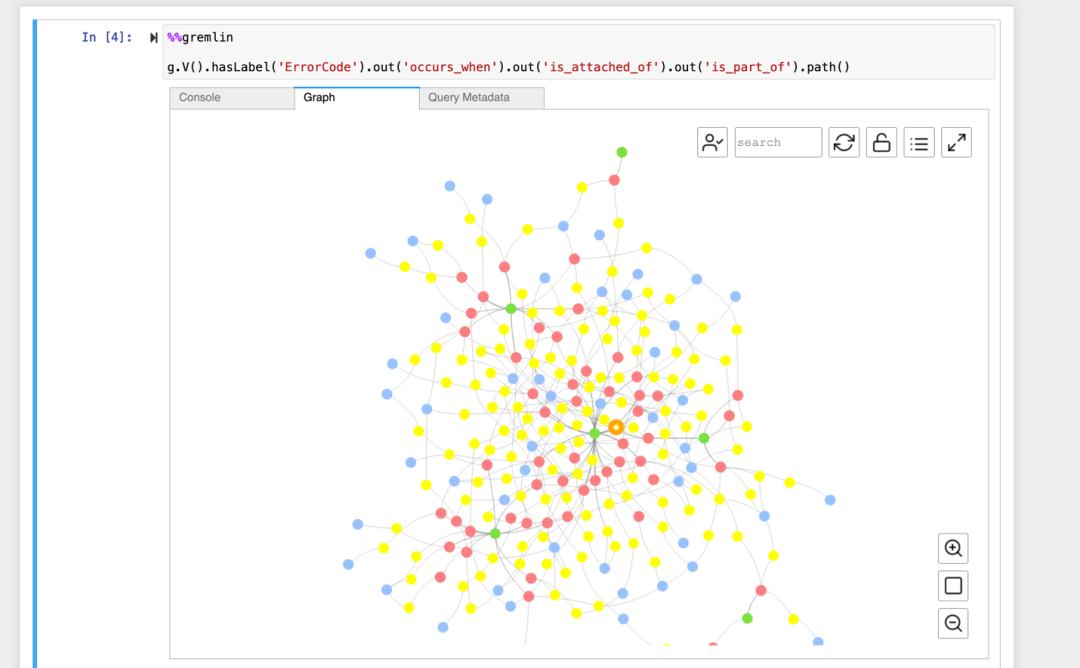
2) 使用 Workbench 进行数据查询
数据调用
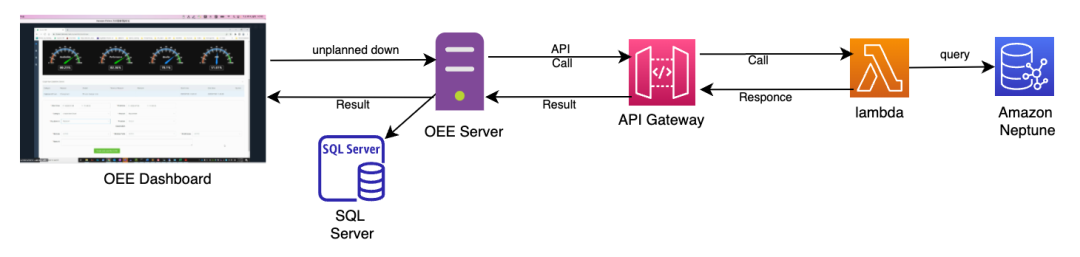
OEE 系统会调用 API 网关查询错误码,返回可能的模块和模块部分以及问题的根本原因。
1) 创建 API Gateway 与 Lambda 来调用 Neptune 数据库接口
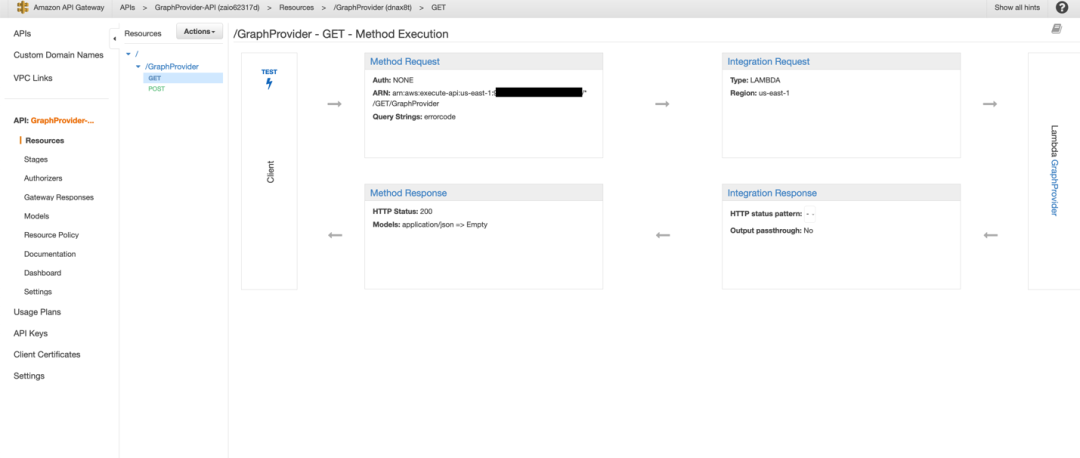
2) 从客户端发起查询请求,来返回 Neptune 数据库中的内容,完成查询
总结
本文实现了工厂 OEE 系统上传数据,在 Amazon SageMaker 里面转化数据,以及在 Neptune 存放数据的过程,最后在 API Gateway 以及 Lambda 中实现对数据的调用。针对每次 OEEEvent 发生的 ErrorCode 进行分析,同时关联工厂产线相关知识比如机器模块,子模块,故障描述,故障原因等一系列机器对应的数据。随着知识数据的不断积累,数据科学家还可以持续使用 SageMaker 更新知识之间的关联关系,相关的工业场景可以根据实际场景利用本文的方案进行架构设计。
本篇作者

丁煜恒
亚马逊云科技解决方案架构师,有7年企业上云项目管理和交付经验。目前负责亚马逊云科技海外客户的落地中国区的方案设计,咨询,实施等相关工作。在计算,存储,安全,数据分析,DevOps 等领域有丰富的架构设计及实践经验。在加入亚马逊云科技前,曾在微软公司任职,负责过微软 Azure 云上若干世界500强中零售和制造行业客户的云上项目落地。

魏羽
亚马逊云科技高级解决方案架构师,在 IT 行业有从业超过13年的工作经验,其中超过7年作为公有云架构师角色帮助企业级客户完成业务上云的需求。当前在 Amazon 云主要负责若干世界500强中的制造业和高科技行业客户的上云规划和支持,技术上致力于推广 Amazon 云 IoT 和大数据分析相关技术在企业中的应用。在加入亚马逊云科技前,曾在华为、微软等公司任职,负责过华为云以及微软 Azure 云上的项目落地。

听说,点完下面4个按钮
就不会碰到bug了!
