




点击蓝字 关注我们

文章摘要:用一杯星巴克的钱,自己动手2小时的时间,就可以拥有自己训练的开源大模型,并可以根据不同的训练数据方向加强各种不同的技能,医疗、编程、炒股、恋爱,让你的大模型更“懂”你…..来吧,一起尝试下开源DolphinScheduler加持训练的开源大模型!
导读
让人人都拥有自己的ChatGPT
面向人群——每一个屏幕面前的你
仅用三步,构造出更“懂”你的ChatGPT
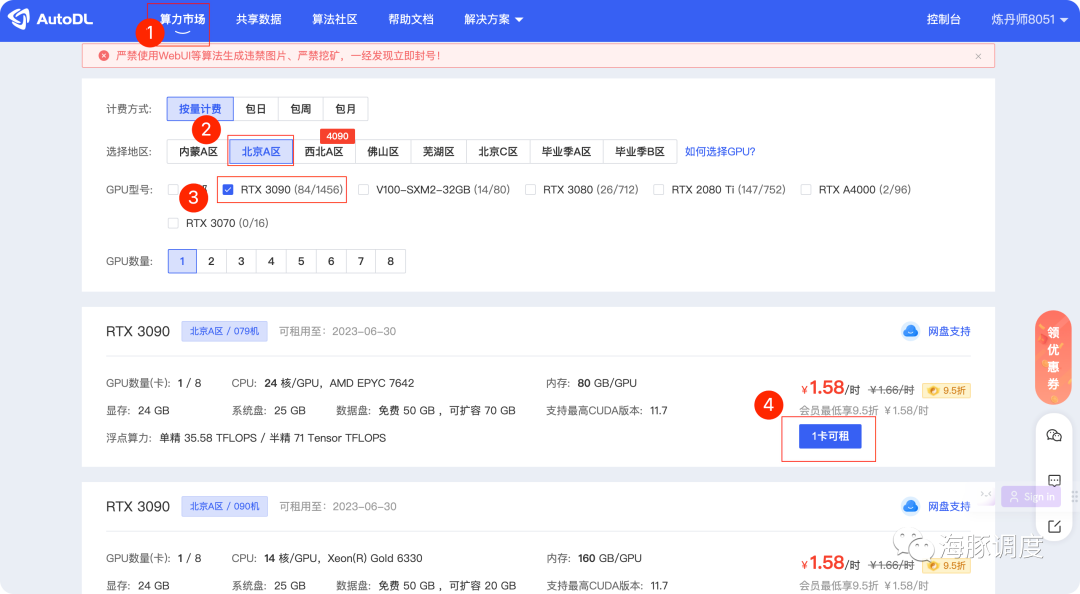
用低成本租用一个拥有3090级别以上的GPU显卡 启动DolphinScheduler 在DolphinScheduler页面点击训练工作流和部署工作流,直接体验自己的ChatGPT吧
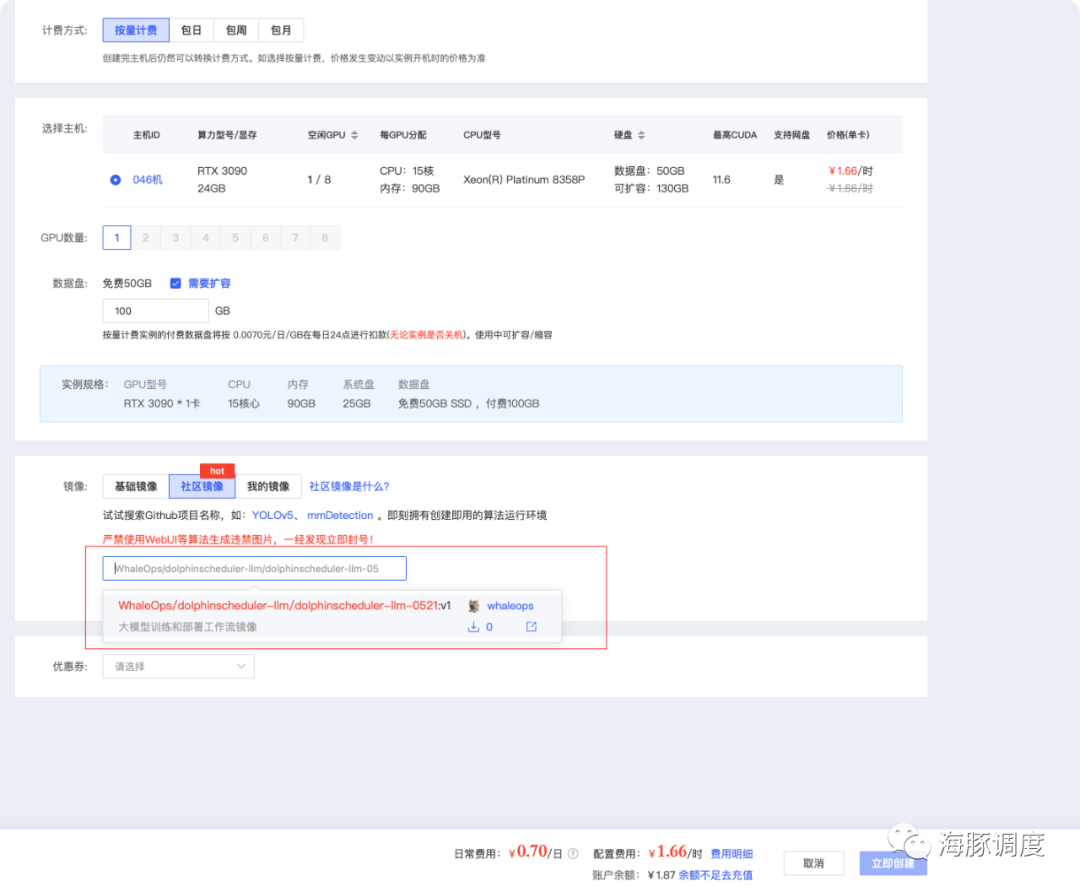
镜像
WhaleOps/dolphinscheduler-llm/dolphinscheduler-llm-0521之后,即可选择镜像,如下如所示,目前只有V1版本的,后面随着版本更新,有最新可以选择最新

启动DolphinScheduler
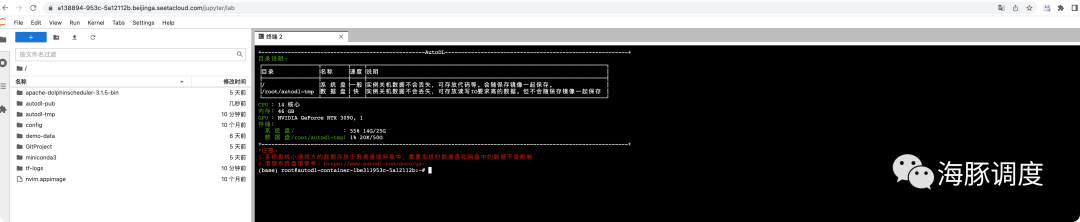
进入服务器
1. 通过JupyterLab页面登录(不懂代码的请进)


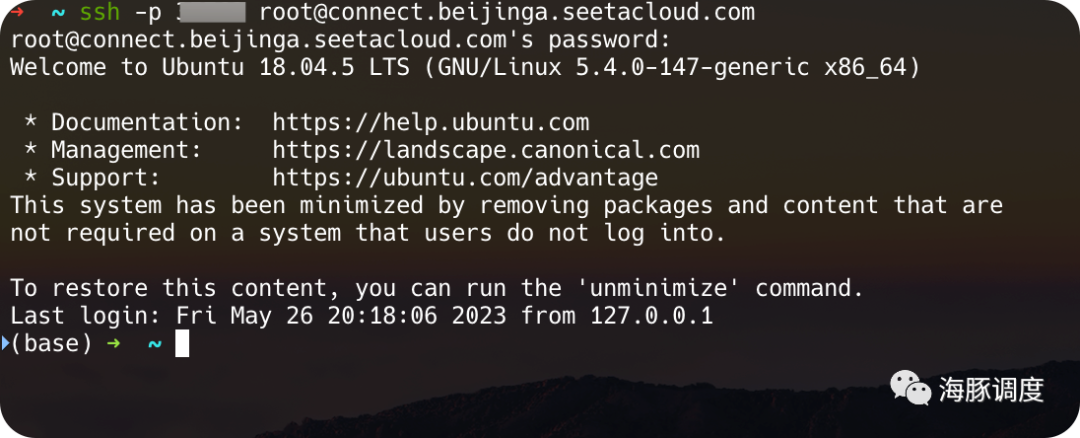
2. 通过终端登录(懂代码的请进)

导入DolphinScheduler的元数据
cd apache-dolphinscheduler-3.1.5-bin
vim import_ds_metadata.sh打开
import_ds_metadata.sh文件
#!/bin/bash
# 设置变量
# 主机名
HOST="xxx.xxx.xxx.x"
# 用户名
USERNAME="root"
# 密码
PASSWORD="xxxx"
# 端口
PORT=3306
# 导入到的数据库名
DATABASE="ds315_llm_test"
# SQL 文件名
SQL_FILE="ds315_llm.sql"
mysql -h $HOST -P $PORT -u $USERNAME -p$PASSWORD -e "CREATE DATABASE $DATABASE;"
mysql -h $HOST -P $PORT -u $USERNAME -p$PASSWORD $DATABASE < $SQL_FILE
bash import_ds_metadata.sh
启动DolphinScheduler
/root/apache-dolphinscheduler-3.1.5-bin/bin/env/dolphinscheduler_env.sh
......
export DATABASE=mysql
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:mysql://HOST:3306/ds315_llm_test?useUnicode=true&characterEncoding=UTF-8&useSSL=false"
export SPRING_DATASOURCE_USERNAME="root"
export SPRING_DATASOURCE_PASSWORD="xxxxxx"
......
bash ./bin/dolphinscheduler-daemon.sh start standalone-server
tail -200f standalone-server/logs/dolphinscheduler-standalone.log查看日志,这时候,DolphinScheduler就正式启动了!
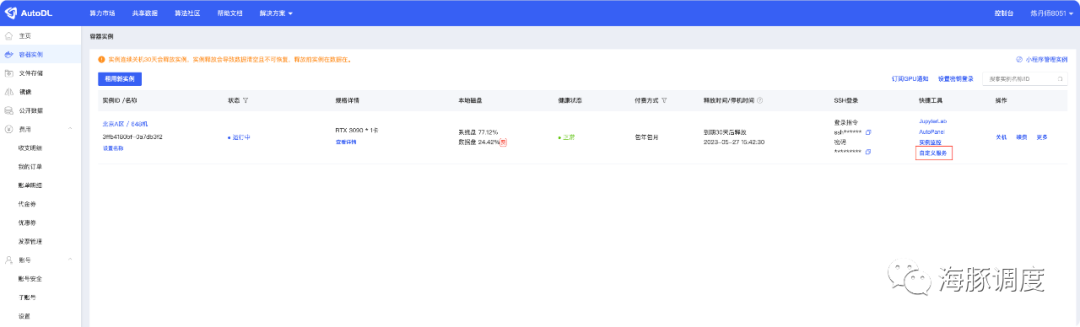

AutoDL模块开放一个6006的端口,我们将DolphinScheduler的端口配置成6006之后,可以通过上面的入口进入,但是因为跳转的url补全,所以404,因此我们补全URL即可
admindolphinscheduler123
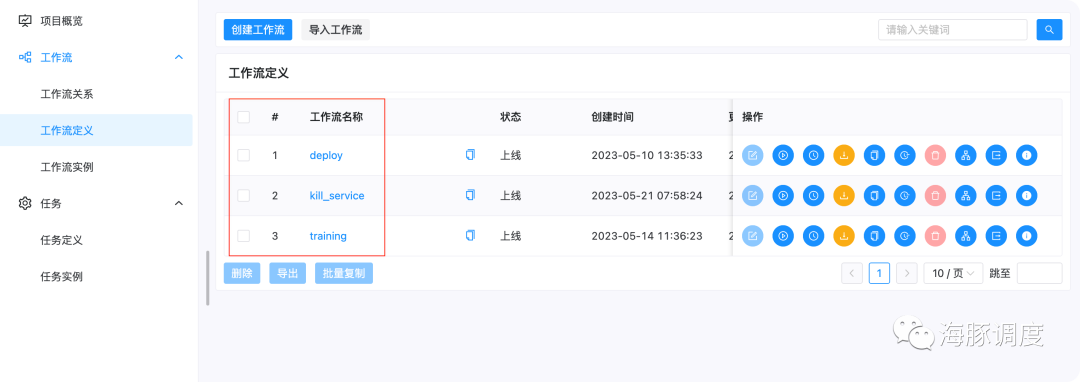
开源大模型训练与部署
工作流定义

Training
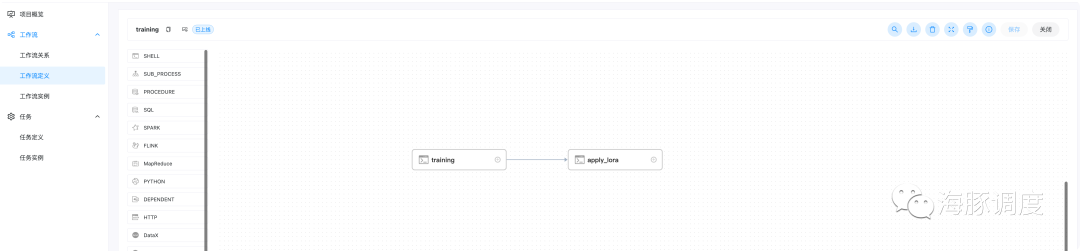
base_model: 基础模型,根据个人情况选择自行下载,注意开源大模型仅为学习和体验用途,目前默认为 TheBloke/vicuna-7B-1.1-HFdata_path: 你要训练的个性化数据和领域数据的路径,默认为 /root/demo-data/llama_data.jsonlora_path: 训练出来的lora权重的保持路径 /root/autodl-tmp/vicuna-7b-lora-weightoutput_path: 将基础模型和lora权重合并之后,最终模型的保存路径,记下来部署的时候需要用到 num_epochs: 训练参数,训练的轮次,可以设为1用于测试,一般设为3~10即可 cutoff_len: 文本最大长度,默认1024 micro_batch_size: batch_size

Deploy
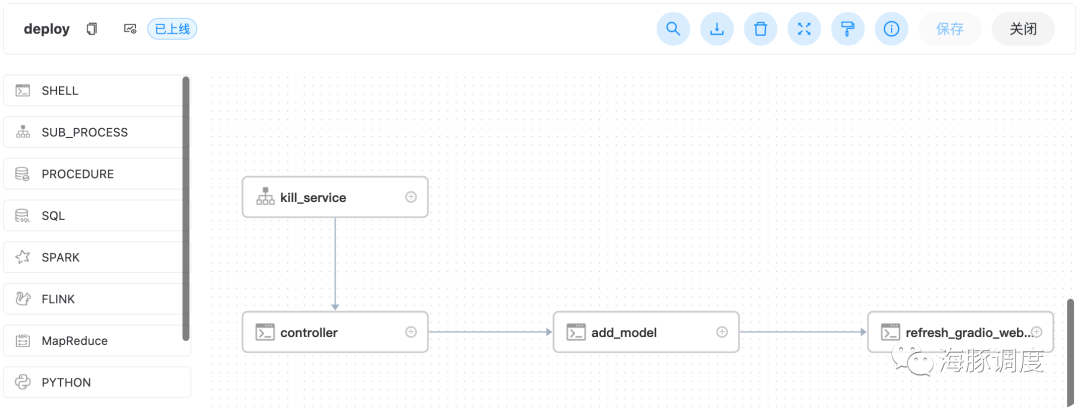

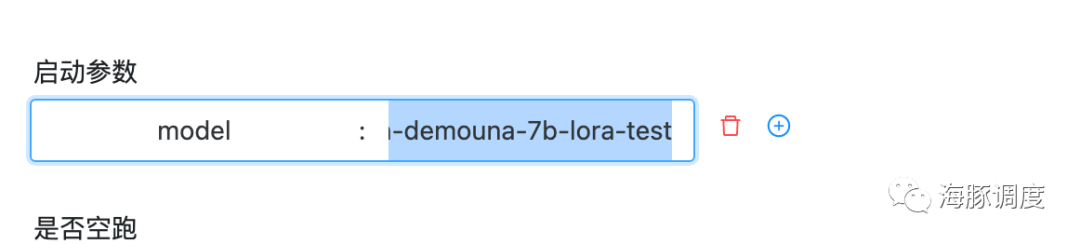
model: 模型路径,可以为huggingface的模型id,也可以为我们训练出来的模型地址,即上面training工作流的output_path。默认为 TheBloke/vicuna-7B-1.1-HF
使用默认,将直接部署vicuna-7b
的模型
Kill_service
大模型操作实例演示
1. 训练大模型

step = 数据量 * epoch batchsize


/root/demo-data/llama_data.json,当前数据来源于下面华佗,一个使用中文医学数据finetune的医学模型,对,我们样例是训练一个家庭医生出来:

instruction
****: 指令,为给模型指令input
: 输入output
: 期望模型的输出
{"instruction": "计算算数题", "input": "1+1等于几", "output": "2"}
instruction和
input合并为
instruction, input为空也可以。
data_path参数执行自己的数据即可。
TheBloke/vicuna-7B-1.1-HF,会有下载的过程,稍等下载完成即可,这个模型下载是由用户指定的,你也可以任选下载其他的开源大模型(注意使用时遵守开源大模型的相关协议)。


部署工作流

TheBloke/vicuna-7B-1.1-HF,部署
vicuna-7b的模型,如下图所示:

output_path即可


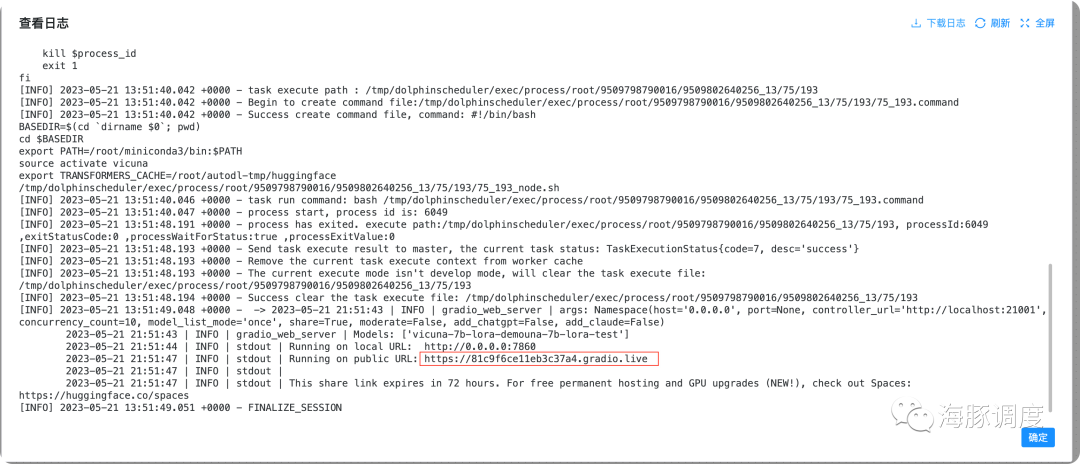
0.0.0.0:7860因为AutoDL只开放了6006端口,并且已经用于dolphinscheduler,所以我们暂时无法访问该接口,我们可以直接访问下面的链接
[https://81c9f6ce11eb3c37a4.gradio.live](https://81c9f6ce11eb3c37a4.gradio.live)这个链接每次部署都会不一样,因此需要从日志找重新找链接。
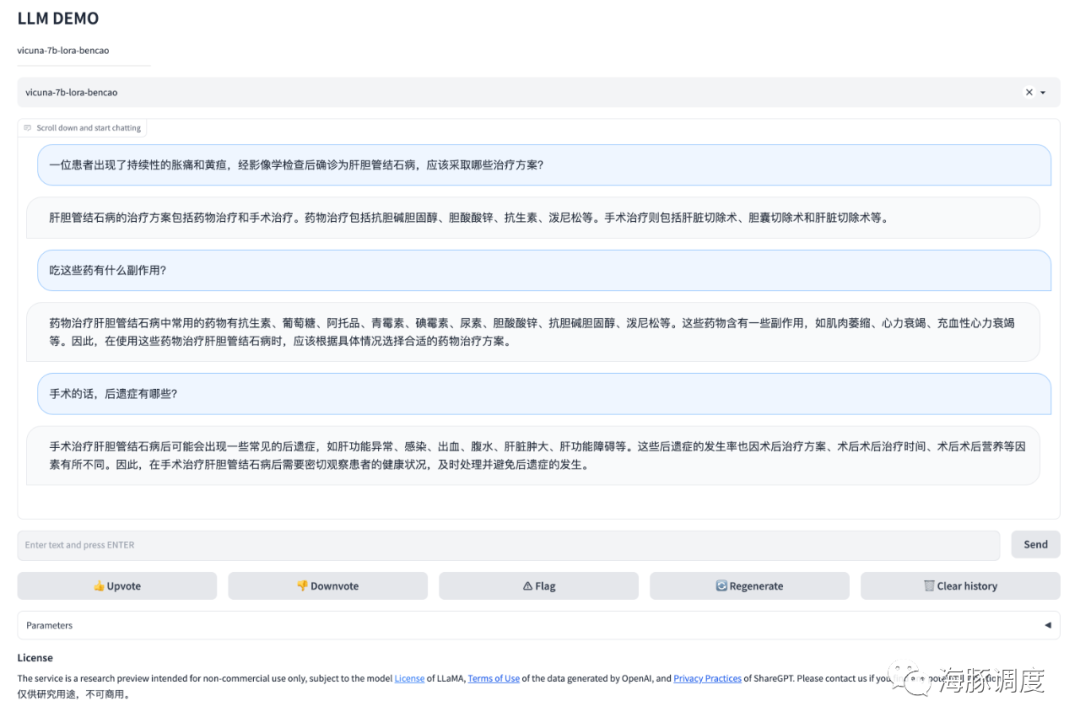
总结
附注意事项:
数据安全与隐私
特定领域知识
投入成本
DolphinScheduler
开源大模型法律法规约束
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。

添加社区小助手微信(Leonard-ds)
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
☞Apache DolphinScheduler 深圳 Meetup,走进OPPO不容错过的大数据盛宴!
☞Apache DolphinScheduler 发布 3.1.6 版本,支持 SeaTunnel Zeta 引擎

