




√掌握TIK C+算子端到端开发流程
√掌握TIK C++矢量算子动态shape输入的实现
√掌握CPU模式下的算子调试技术
√掌握UT和ST的测试编码方法
√了解NPU模式下的性能采集与分析
1 动态算子
1.1 tiling结构体
主要的操作流程如下:

tiling结构体中的信息:
- BLOCK_DIN:并行计算使用的核数
- TOTAL_LENGTH:总共需要计算的数据个数
- TILE_NUM:每个核上计算数据分块的个数
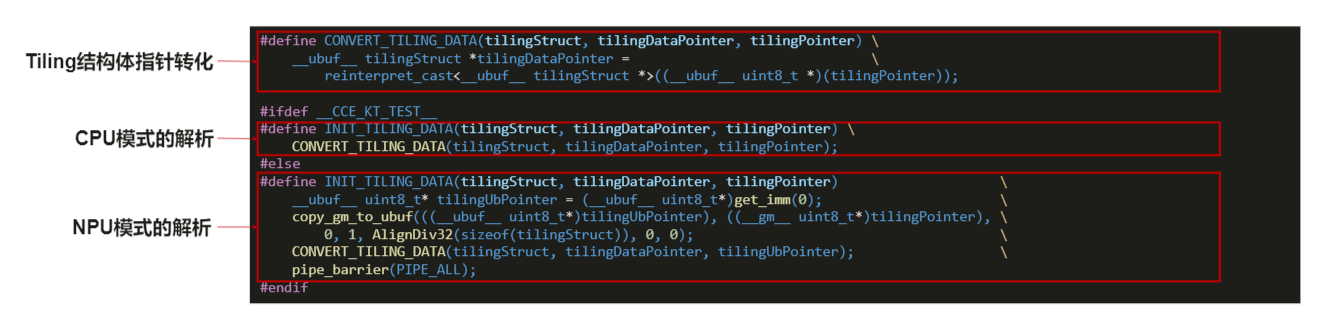
1.2 tiling解析函数
核函数传入tiling指针,与x,y,z的角色相同,添加获得tiling结构体的宏函数调用GET_TILING_DATA

2 动态与固态shape对比

2.1 Init()函数
- 固定shape
__aicore__ inline void Init(gm_ uint8_t* x,_gm_ uint8_t* y,_gm_uint8_t* z)
{
// get start index for current core,core parallel
xGm.SetGlobalBuffer(( gm _ half*)x + block_idx *BLOCK_LENGTH);
yGm.SetGlobalBuffer(( gm _ half*)y + block_idx * BLOCK_LENGTH);
zGm.SetGlobalBuffer((gm__ half*)z + block_idx * BLOCK_LENGTH);
//pipe alloc memory to queue,the unit is Bytes
pipe.InitBuffer(inQueueX,BUFFER_NUM,TILE_LENGTH * sizeof(half));
pipe.InitBuffer(inQueueY,BUFFER_NUM,TILE_LENGTH * sizeof(half));
pipe.InitBuffer(outQueueZ,BUFFER_NUM,TILE_LENGTH * sizeof(half));
}
- 动态shape
__aicore__ inline void Init( gm_ uint8_t* x,__gm_ _uint8_t*y,gm__ uint8_t*z,
uint32_t blockDim,uint32_t totalLength,uint32_t tileNum)
{
this->blockLength = totalLength / blockDim;
this->tileNum = tileNum;
this->tileLength = this->blockLength / tileNum / BUFFER_NUM;
// get start index for current core,core parallel
xGm.SetGlobalBuffer((gm_ half*)x + block_idx * this->blockLength);
yGm.SetGlobalBuffer(( gm_ half*)y + block_idx * this->blockLength);
zGm.SetGlobalBuffer(( gm _ half*)z + block_idx * this->blockLength);
// pipe alloc memory to queue,the unit is Bytes
pipe.InitBuffer(inQueueX,BUFFER_NUM,this->tileLength * sizeof(half));
pipe.InitBuffer(inQueueY,BUFFER_NUM,this->tileLength * sizeof(half));
pipe.InitBuffer(outQueueZ,BUFFER_NUM,this->tileLength * sizeof(half));
}
2.2 add_tik2.py
- 固定shape输入的真值生成脚本
def gen_ golden_data_simple():
input_x = np.random.uniform( -100,100,[8,2048]).astype(np.float16)
inputy =np.random.uniform( -100,100,[8,2048]).astype(np.float16)
golden =(input_x + input y).astype(np.float16)
input_x.tofile("./ input/input_x.bin")
input_y.toftlef"./input/input_y.bin")
golden.tofile(i./output/golden.bin")
- 动态shape输入的真值生成脚本
def gen golden data simple():
one_repeat_calcount = 128#fixed
block dim imm = 8
tile_num imm = 8
double_buffer_imm = 2# fixed
total_length_imm = block_dim imm *one_repeat_calcount* tile_num imm*double_buffer_im
block_dim = np.array(block_dim_imm,dtype=np.uint32)
total_length = np.array(total_length_imm,dtype=np.uint32)
tile_num = np.array(tile_num_imm,dtype=np.uint32)
tiling = (block_dim,total_length, tile_num)
tiling_data = b'-join(x.tobytes( for x in tiling)
with open( ' ./input/tiling.bin', 'wb') as f:
f.write(tiling_data)
input_x = np.random.uniform(-100,100,[total_length_imm, ]).astype(np.float16)
input_y = np.random.uniform(-100,100,[total_length_imm, ]).astype(np.float16)
golden = (input_x + input y).astype(np.float16)
input_x.tofile("-/input/input_x.bin")
input y.tofile(" -/input/inputy.bin")
golden.tofile("-/output/golden.bin")
2.3 main.cpp
- 固定shape
size_t inputByteSize = 8* 2048* sizeof(uint16_t);
size_t outputBytesize = 8* 2048 * sizeof(uint16_t);
uint32_t blockDim = 8;
- 动态shape
uint8_t* tiling = (uint8_t*)tik2: : GmAlloc(tilingSize);
ReadFile("./input/tiling.bin" , tilingSize, tiling, tilingSize);uint32_t blockDim =(*(const uint32_t*) (tiling));
size_t inputByteSize = blockDim *2048 * sizeof(uint16_t);size_t outputByteSize = blockDim * 2048 * sizeof(uint16_t);
//========================================
aclrtMallocHost((void**) (&tilingHost), tilingSize);
ReadFile("./input/tiling.bin", tilingSize, tilingHost,tilingSize);
uint32_t blockDim =(*(const uint32_t*) (tilingHost));
size_t inputByteSize = blockDim * 2048 * sizeof(uint16_t);
size_t outputByteSize = blockDim * 2048 * sizeof(uint16_t);
2.4 代码文件对比总结

2.5 TiKi C++算子在不同模式下实操演示
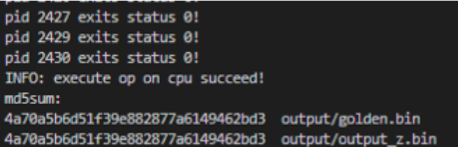
CPU下运行结果
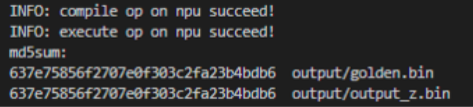
NPU下运行结果
3 CPU 模式下对算子功能的调试
- 使用GDB调试
-
- 使用printf进行调试(或者std::cout)也可以

「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
