




之前写过一个这方面的内容:让MIMIC数据库变快2000倍,mimic iv更新2.0后好多朋友私我原来那个不能用了。另外也有人说应用了代码后查询还是慢。所以再次说明下。
查询加速保姆级教程
为啥查询会这么慢?
还以原来那个查询为例
select * from labevents
where subject_id=10208468
这句话是查找subject_id为10208468的记录,如果表里没有没有对subject_id建立索引,需要对表里所有记录进行比对,才能找到符合条件记录,labevents表有124,342,638行,就要进行124,342,638次比对,慢是正常的。
为啥那个代码能加速?
SET search_path TO mimic_hosp;
DROP INDEX IF EXISTS labevents_idx03;
CREATE INDEX labevents_idx03
ON labevents (subject_id);
DROP INDEX IF EXISTS labevents_idx04;
CREATE INDEX labevents_idx04
ON labevents (hadm_id);
DROP INDEX IF EXISTS labevents_idx05;
CREATE INDEX labevents_idx05
ON labevents (itemid);
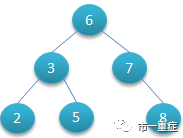
这个代码就是对subject_id,hadm_id,item_id这几个查询常用字段建立了索引,Postgresql用的是B-Tree方法建立了索引,简单点理解就像下面这棵树,如果我要找5,先跟6比对,比6小,往左边找,下一个节点比3大,再往右边找,很快就找到了,减少了比对次数,查询就快了。
为啥2.0以后这个代码不能用了
上面代码第一句
SET search_path TO mimic_hosp;
是说在mimic_hosp进行操作,但是2.0,改名了,叫mimiciv_hosp所以改下就行。
SET search_path TO mimiciv_hosp;
为啥我用了这个代码查询还是不快?
我看了下他的查询代码
select * from chartevents
where itemid=226512
之前那个只对labevents表的字段做了索引,chartevents表并没有动,这个表itemid字段没有索引,当然没有用。
我怎么知道我要查询的这个表的这个字段有没有建立索引
右击表格,选择设计表,然后看索引标签卡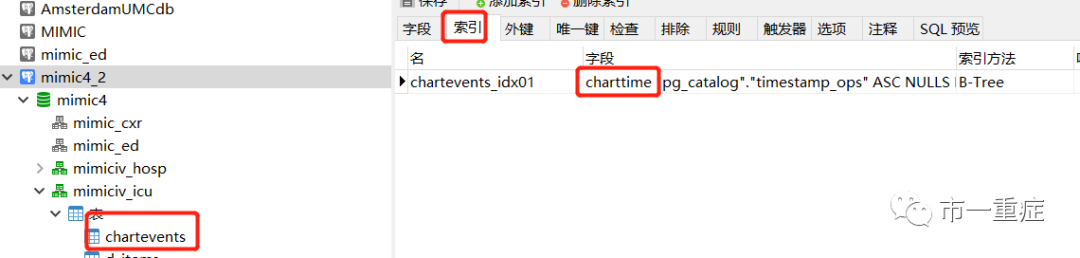 可以看到,只有charttime建立了索引
可以看到,只有charttime建立了索引
下面怎么办?
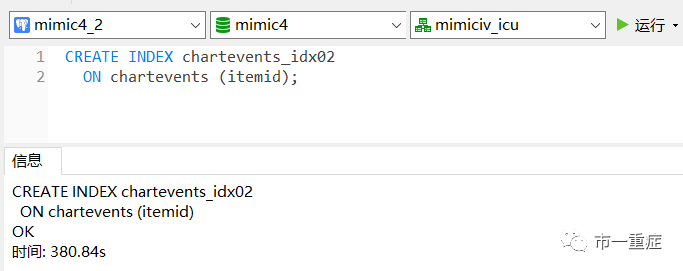
要对chartevents的itemid查询加速,就建立这个字段的索引。在navicat里面打开这个表,新建查询,输入下面这句
 就新建了itemid的所有,index的名字chartevents_idx02只要不与现有的重复就好。on后面写表名和字段名。
就新建了itemid的所有,index的名字chartevents_idx02只要不与现有的重复就好。on后面写表名和字段名。
然后点运行,跑下要不少时间,但是一劳永逸了。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
