前言
知识图谱、知识表示与图算法等是CVTE DM团队的核心研究方向之一,HugeGraph 作为优秀的开源图数据库,在打造教育、招聘、供应链等垂域知识存储与计算时,成为了不可或缺的基础设施。
下面是CVTE DM团队的Simon大佬在刚刚结束的GOTC 2023全球开源技术峰会「基础设计与软件架构」专场为大家带来的关于图数据库HugeGraph主题演讲~
整体分为三个部分
1. HugeGraph简介
2.Apache HugeGraph的架构演进
3.HugeGraph在CVTE的应用与Apache HugeGraph展望
 一、HugeGraph 简介
一、HugeGraph 简介
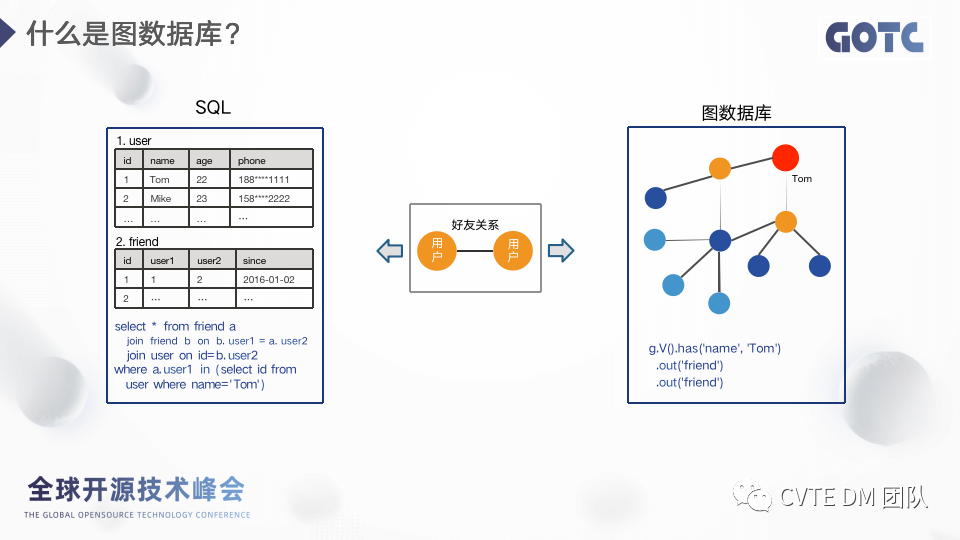
1.1 什么是图数据库?
关系型数据库是以表结构存储数据,SQL语言查询做查询,表之间的关联关系用 Join 来表示,但是在关联关系复杂的场景下,比如社交场景,需要查询 “Tom的朋友的朋友的朋友” ,也就是多度查询的场景,SQL会变得很复杂,且执行效率低下,对于这种复杂关系类数据的表示和存储有更好的选择——图数据库。
图数据库可以更好更直观地表示实体间地关系,也提供了更便捷的查询语言和更快的关系检索性能,如图所示的 Gremlin 图查询语句,从“Tom”点出发,迭代两次找到所有的好友,相比用SQL表示,语法上更简单直接,灵活度更高,也更利于理解。
1.2 HugeGraph简介
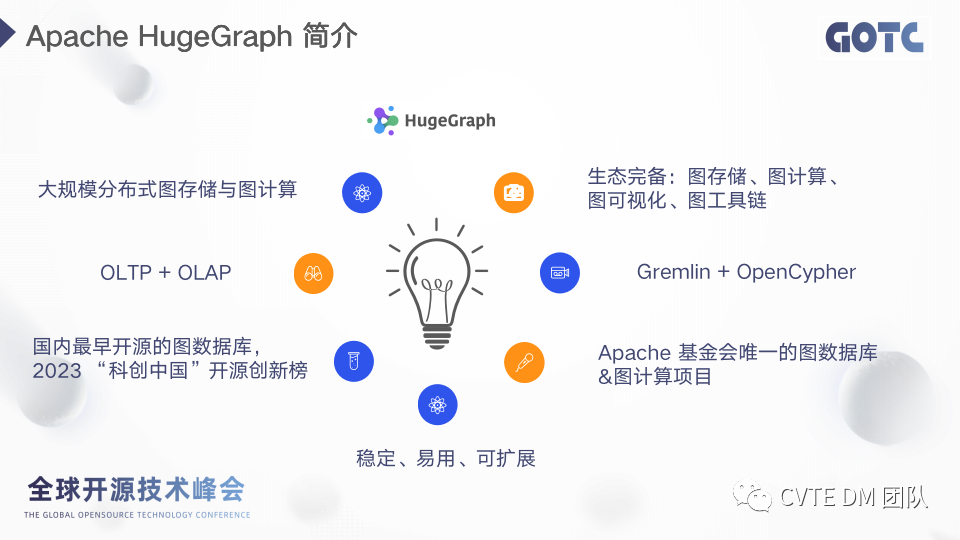
HugeGraph 就是一款高性能分布式图数据库,除了图存储之外,项目还包括了图计算、图可视化、图导入工具、客户端、备份、监控等等,具有完整的图生态。HugeGraph 对 OLTP 和 OLAP 两种常用的查询场景都做了支持,用户可以通过 Gremlin 和 cypher 两种图语言对 HugeGraph 进行操作。还有值得一提的是 HugeGraph 是国内最早开源的图数据库,也是 Apache 软件基金会目前唯一的图数据库项目。1.3 为什么加入Apache?
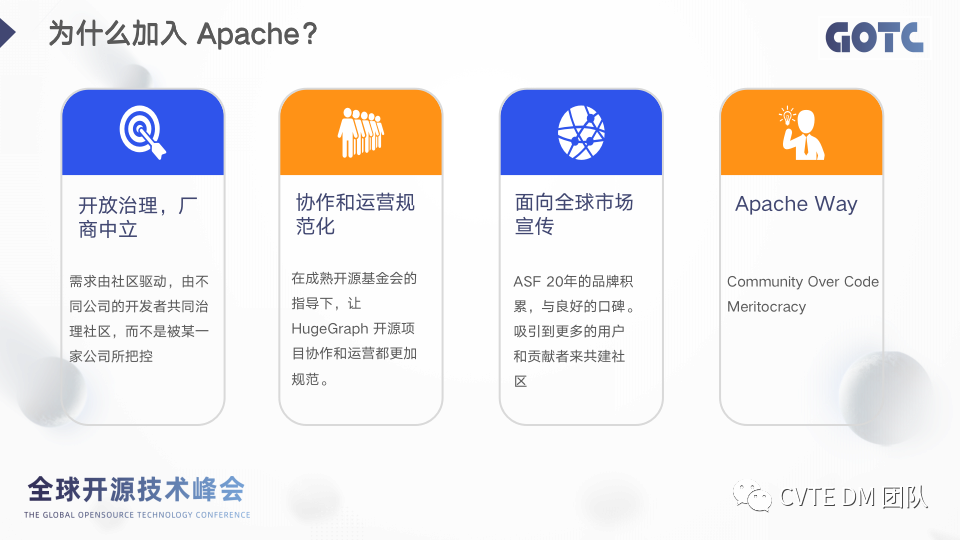
至于为什么会选择加入 Apache ,因为 Apache 组织的项目都是厂商中立,意味着需求由社区驱动,由不同公司的开发者共同治理社区,而不是被某一家公司所把控。另外 Apache 有一套成熟的协作和运营规范,并且会有专业的导师帮助项目的规范化。Apache 是非常强调社区协作的一个组织,Apache Way 的核心就是社区高于代码,这也是 Apache 20年运营总结出来的可持续开源的成功经验。另外,Apache 是一个全球性的组织,20年的口碑大家也是有目共睹,HugeGraph 希望借助 Apache 的影响力能够吸引到更多的用户和贡献者来共建社区。1.4 HugeGraph发展历程
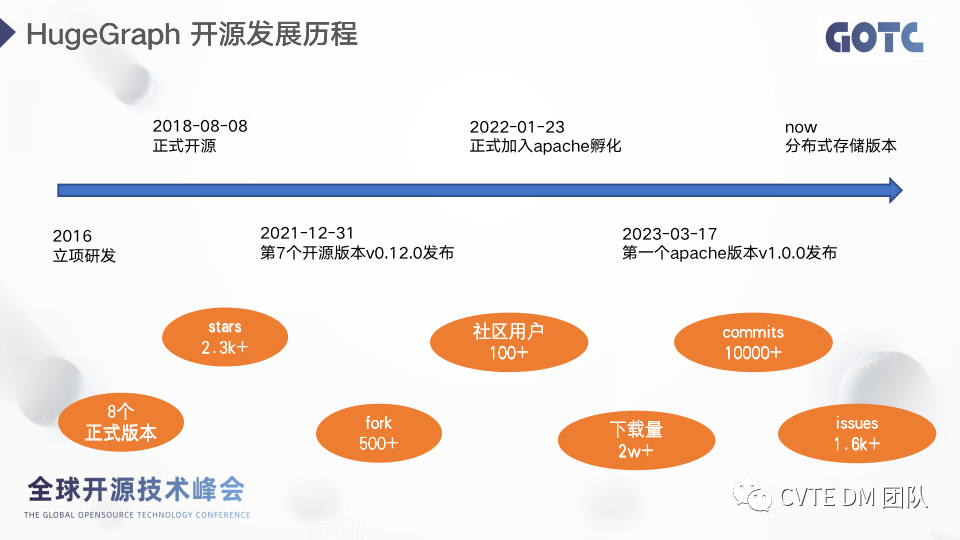
HugeGraph 2016 年在百度内部立项,18 年正式开源,到 21 年为止已经发布了 7 个正式版本,在去年5月份正式加入 Apache,今年 2 月份发布了第一个 Apache 版本,目前正在全力推动分布式版本的研发。自 18 年开源以来,社区的关注度、用户数、贡献者、下载量等等的指标都在稳步提升,社区在努力吸引更多用户的同时,也在鼓励用户成为贡献者回馈社区,形成良性循环。 二、架构演进
2.1 HugeGraph 1.0 架构
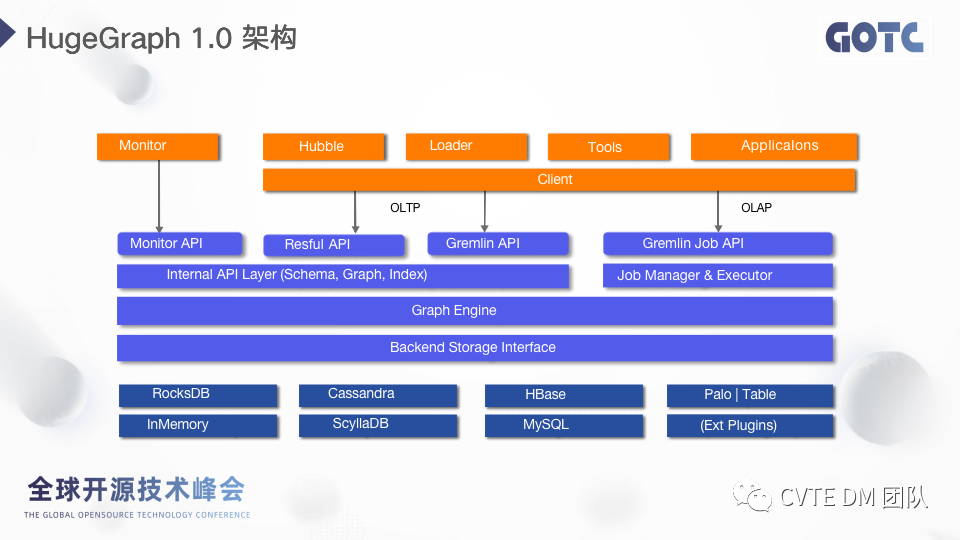
HugeGraph 1.0 版本的架构整体上可以分成3层,存储层、计算层和应用层。· 存储层负责图数据存储,包括顶点、边和属性等、系统数据存储和 Schema 存储。存储层是通过插件化的方式实现的,这也是 HugeGraph 的亮点之一,用户可以根据自己的需求去选择后端存储,目前已经支持 RocksDB、HBase 和 MySQL 等。· 计算层为了适配底层不同的存储结构,增加了后端适配层,用于屏蔽底层数据库的差异,适配层往上的 Graph Engine 是 HugeGraph 的核心,负责图查询语句的解析,序列化等等,最上层支持了基于 Restful 和 Gremlin 的 OLTP 查询,同时在 OLAP 方面也支持了环路检测、最短路径、Personal Rank 等16种图算法,并且实现了异步的执行方式,对于执行时间比较久的算法或者 Gremlin 语句可以通过异步的方式去提交和执行。· 在应用层,HugeGraph 提供了丰富的工具给用户使用,包括可视化、Loader、备份、客户端等等。方便用户来构建和使用图数据。2.2 目前支持的分布式存储架构与瓶颈
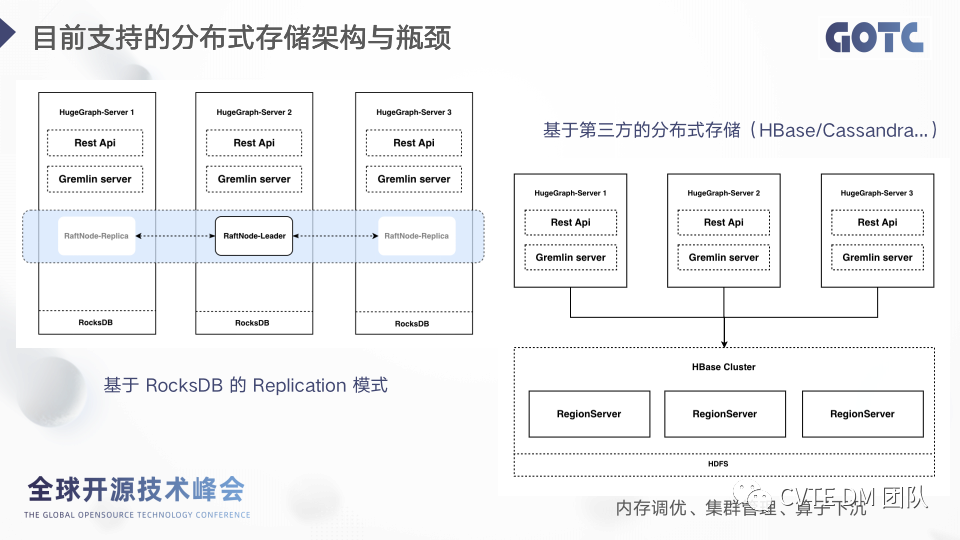
目前版本支持的分布式架构大致可以分为两种,基于 Rocksdb 存储的复制集模式,和基于第三方分布式存储的方式,比如 HBaseBackendStore。这两种架构的弊端都非常明显。· RocksDB 的 Replicate 模式虽然也是基于 raft 对数据集进行复制,能保证数据的一致性,但是每个节点都保留了全量的数据,并没有增加可存储的数据量,只是有了高可用的支持,而且 server 的执行逻辑基本也是串行的。· HBaseBackendStore 的模式,过于依赖 HBase 的存储,HBase 的调优原本就是一件比较复杂的工程,很容易成为瓶颈,特别是内存的调优,HBase 的集群管理挑战也非常大,依赖的组件非常多,HDFS,zk 等等,而且在需要进行条件过滤/或者聚合的场景下,需要拉取数据在 Server 端进行,下推到存储端的成本非常高。所以更好的方案是我们在 Rocksdb Replicate Mode 的基础上支持 shard mode,单 raft group 改造成 multi raftgroup,这样的话为了能有更好地扩展性。基于目前的问题我们看看2.0版本的变化。2.3 HugeGraph 2.0 的重大变化

2.0 版本我们有 4 大设计目标,万亿级别的图数据存储万张图存储、高性能的读写效率、支持自动运维、提高用户的使用便捷性。基于此,我们设计了分布式的架构,支持图数据的分区和多副本,并且将存储与计算分离便于灵活地伸缩。分布式带来了海量数据的支持,同时也提升了集群管理的复杂性,所以增加了高可用的设计,支持容灾和故障恢复,以及更多的监控指标等等。在性能方面,因为要跨节点读写数据,无法避免网络传输。因此,在查询上,我们做了很多的针对性优化,包括 Gremlin 并行化、算子下沉。使用上主要是接口的优化和功能的增强。2.4 HugeGraph 2.0 的重大变化-计算

图计算 hugegraph-computer 是相对对立的模块,是 HugeGraph 的子项目,基于 pregel 实现的,对于这次升级hugegraph-computer 支持了更多的图计算算法,另外在使用便捷性和性能上也做了很多的优化。2.0 版本的 computer,与 hugegraph-server 端做了集成,server 内置了 k8s-driver,支持用户通过 api 的方式去开启一个计算,提高易用性。另外在以往的计算过程中,针对同一个图的每个算法计算都需要从 Server 端拉数据,这版中我们在 worker 端做了 snapshot,大大提高执行效率。2.5 分布式存储架构设计
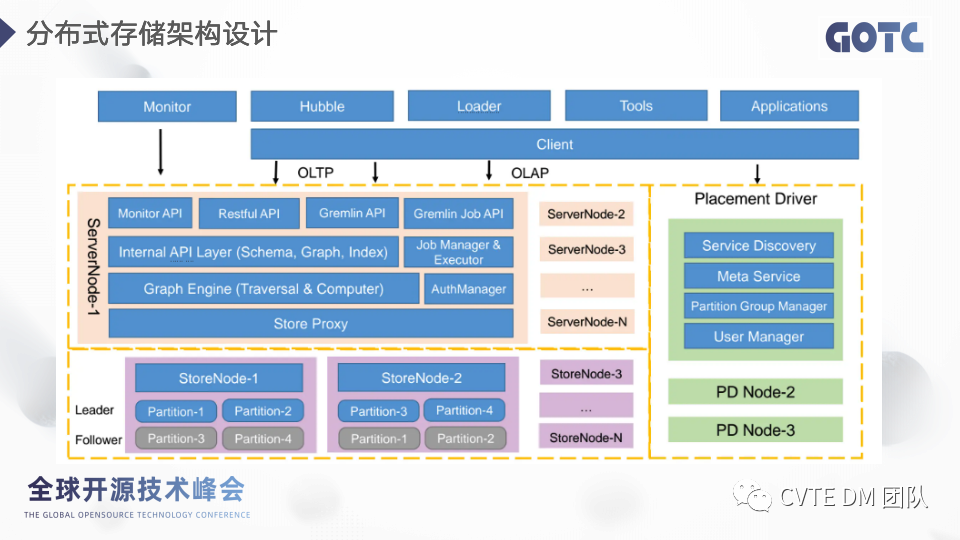
对比之前的那张单机版本的架构图,这一版中除了server之外,额外引入 PD 和 Store角色,图中可以看出各个角色都是分布式可扩展的,多个节点通过 Raft 来保证数据的一致性,Raft 也是 HugeGraph 实现分布式的核心,在 PD 和 Store 中都应用到了 Raft 来做副本的数据同步,raft 的核心是 leader 选举和日志同步。· Store 启动时,RaftGroup 会通过投票选举出 leader 节点,leader 负责写请求的处理,follower 负责同步数据,所有角色都可以响应读请求。另外,v1 版本架构基于 rocksdb 的存储是嵌入在 server 端的,分布式做了存算分离,store 底层仍然是用 rocksdb 实现,每个 store 管理多个分区的数据。· pd 是控制中心,负责服务发现,分区信息存储与节点调度,key 所属分区,分区所属 store;store 之间的数据平衡,以及用户管理。
· Server 端由于存储层做了分离,需要与Store、PD做交互,因此引入了storeProxy 代理层,内嵌 store 和 pd 的 client 负责与二者交互,代理层有三个比较重要的功能,缓存存储 PD 返回的分区信息、实现并行入库、实现网络迭代器,支持从不同节点返回迭代结果。
在用户层虽然看起来和之前的内容类似,但是实现上还是有很大区别的,比如client和loader,发起请求和数据流转的方式都有了很大变化。2.6 分布式架构交互逻辑
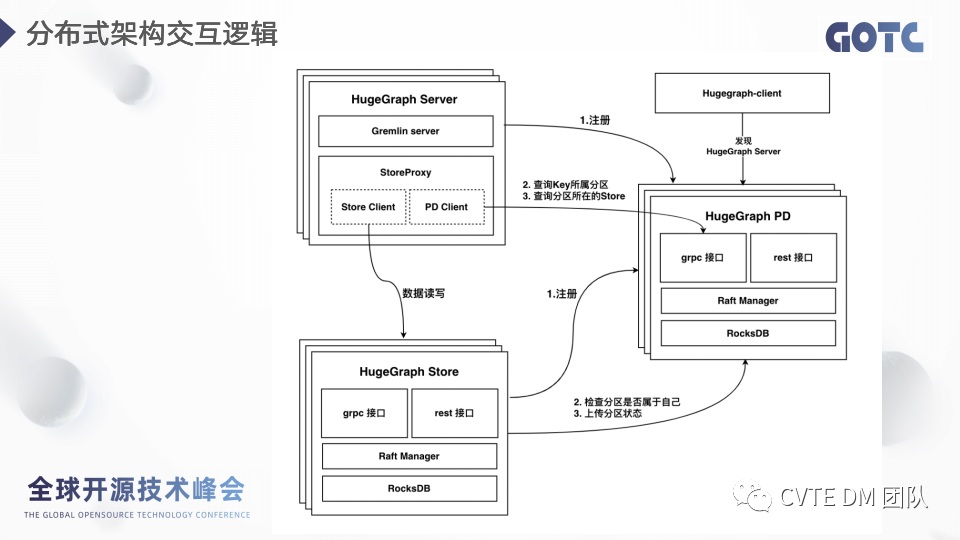
确定了各个角色的职责之后,我们看看角色之间的交互逻辑,首先 pd 和 store 都有 grpc 和 rest 接口,grpc 接口用于集群消息的同步和数据的传输,rest 接口用于给用户提供集群管理功能和获取监控指标等等。· server 和 store 服务启动都会向 pd 注册,因此 pd 知道集群所有节点的信息。所以 client 端首先与 pd 通信,拿到可读的 server 节点 ip,然后向 server 发起请求。· server 端解析查询语句同时向 pd 查询 key 所在的分区以及分区 leader 所在的 store,另外代理层会维护一个缓存,存放分区的信息。· 拿到 store 信息后,即向 store 发起请求,store 拿到请求之后会向 pd 再次确认,分区是否属于自己,这一步其实是为了保证分区数据的一致性。2.7 数据模型、分区、副本策略
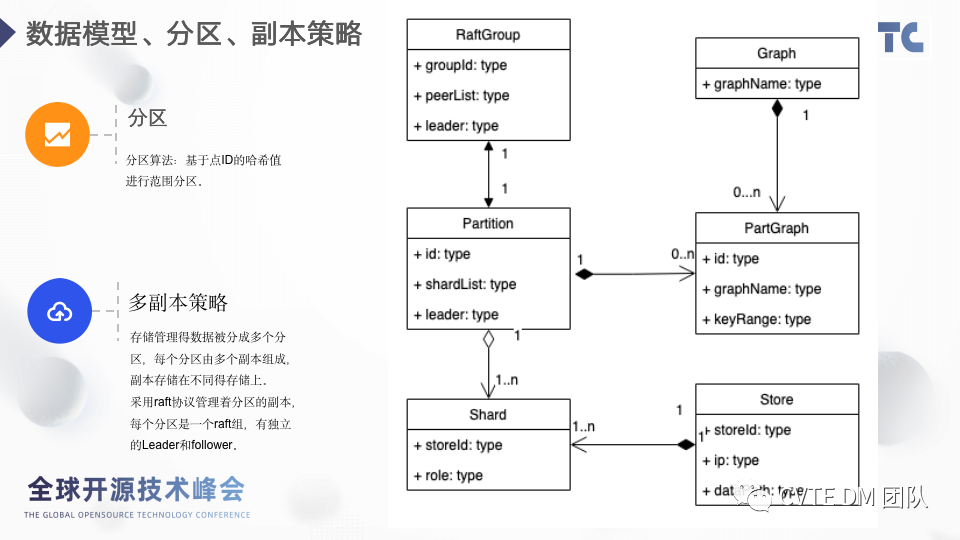
HugeGraph 中分区的逻辑是通过 Graph 的点 id 取 hash 值。然后根据值进行范围划分,分为多个 PartGraph,可以看到PartGraph对象中包含了 keyRange 信息和 graphName。前面提到 hugegraph 是通过 raft 来保证副本一致性的,因为一个raftGroup内部需要通过投票来选举leader,所以RaftGroup 只允许半数以下的副本故障,也就是说 5 副本允许 2 个故障,6 个副本也是允许 2 个故障,可见5 个和 6 个节点的容灾能力是一样的,所以一般来说建议用户配置的副本数量为奇数。从图中可以看到 RaftGroup 和 patition 是一一对应的,patition 是逻辑上的概念,是多个 PartGraph 的集合,因为RaftGroup 是横跨多个服务器节点的,每一个节点就是一个数据分片,也就是 shard,所以 partition 和 shard 是一对多的关系,partition 有几个副本就对应几个 shard。因为一台服务器会有多个 RaftGroup,也就是有多个 shard,而一个图实例对应的是一个 rocksdb 实例,所以 shard 和 store 是多对一的关系。2.8 图结构与存储
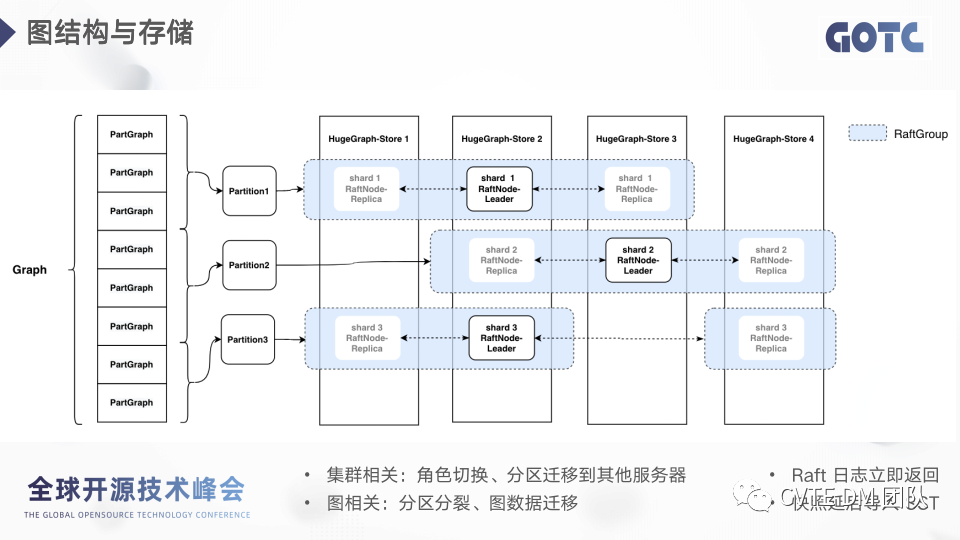
从左往右,一张图划分为多个 PartGraph,多个 PartGraph 对应一个分区,分区与 RaftGroup 一一对应,RaftGroup 内部管理着不同节点之间多个 shard 的同步。
我们注意到 graph 和集群之间我们有两层的映射,为什么不能直接将 PartGraph 与 RaftGroup 映射上?这样做会带来一个很大的弊端,raft 的集群信息有变动,比如角色切换,分区迁移等,那么涉及到这个 RaftGroup 的所有图实例的所有分区都需要做更新。所以我们分开了两个对象,partition 负责集群相关信息,PartGraph 负责图相关信息,二者通过id关联。有效避免牵一发动全身的问题。在写数据上,分区数据写入 Shard,写完 Raft 日志即可返回,不需要等待 rocksdb 的反馈,Raft 快照采用延后导出 sst 模式,有利于提升写的效率。另外在批量写入的场景下,支持只写单个 shard,完成后再做 RaftGroup 内部的数据同步,避免边写边传输的问题。另外,从图中可以看出,每个节点会需要维护多个 RaftGroup, raft 自身维护着日志发送队列和 raft 状态信息,对内存消耗比较大,因此每个 Store 上启动的 RaftGroup 数量不能太多。后续我们会对 raft 做针对性的优化。比如每个 RaftGroup 会维护单独的心跳,后续单个 store 内部的心跳会做合并。了解了整体的图划分,节点分配,数据同步的逻辑之后,我们把单个 store 放大,看看他内部是怎么样的。2.9 Store 存储结构

Store 内部是可以存储多张图实例的,每个图实例分区后通过 raft 机制将副本存储在不同的 store 中,保持各个副本数据一致性。分区是逻辑划分,一个图在一个节点上保存为一个rocksdb,多个分区的数据实际上是存储在一起的分区是通过切边法实现的,也就是点和该点对应的出边、入边、索引都会存储在同一个分区中。 1. 大部分场景下都能分得比较均匀,并发写入性能好。 2. 点和边集中存储,可以很方便实现微计算(算子下沉)例如属性过滤,基于边过滤点等。· 缺点
1. 点和索引的顺序遍历不友好,对点和索引进行顺序遍历、范围查询或前缀查询时需要遍历所有分区。边的遍历不受影响
2. 无法处理超级节点。因为点的所有数据存储在一起。
最上面的Graph接口,支持了网络迭代器和算子下沉的接口,hugegraph 就是基于此做的查询优化。2.10 Gremlin 并行化
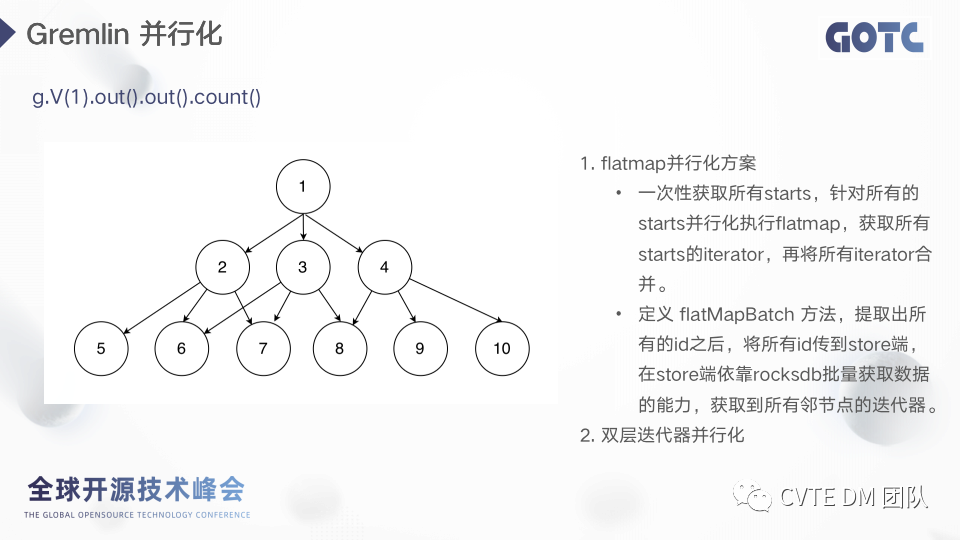
接下来是查询优化的方面,原生的 Gremlin 算子执行逻辑如图所示,举个例子,左上角的gremlin语言表示“查询id为1的点二度的所有节点,并做统计”。gremlin的查询逻辑是根据初始节点1找到邻接节点234,当然他返回的是一个迭代器,然后再把2作为起始节点找到567,再把3作为起始节点,找到678,以此类推,串行执行的逻辑效率非常低下。在这个场景下,我们有两个优化方案。· 一次性获取所有starts,针对所有的starts并行化执行flatmap,获取所有starts的iterator,再将所有iterator合并。· 定义 flatMapBatch 方法,提取出所有的id之后,将所有id传到store端,在store端依靠rocksdb批量获取数据的能力,获取到所有邻节点的迭代器。在 Gremlin 查询中,通常会有多个查询,每个查询有多个结果,因此双层迭代器的结构非常常见,双层迭代器通常用串行的方式一层层执行,我们将第二次迭代逻辑做了并行,并做了测试对比,10个线程的情况下,读效率提升7倍。2.11 算子下沉
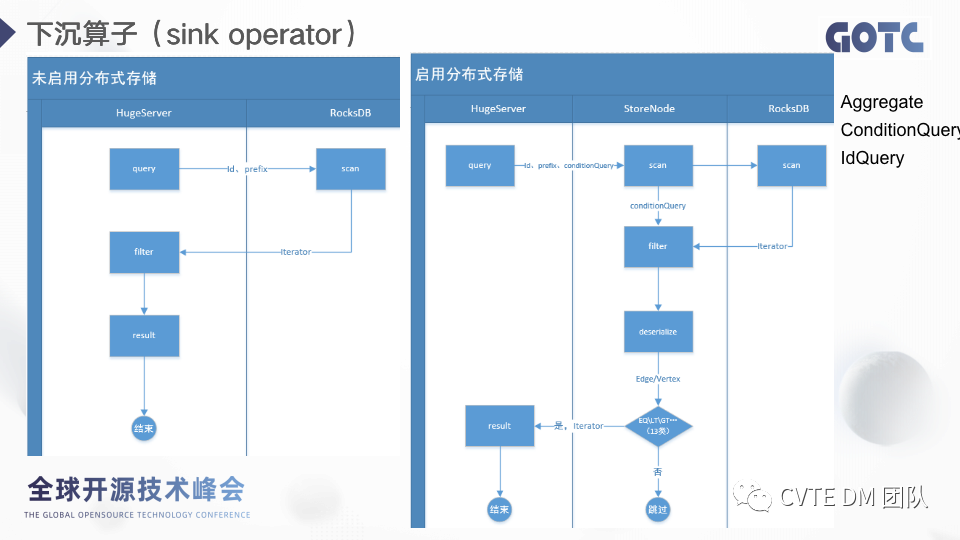
第二个重要的优化点:下沉算子,在单机版本的逻辑中,如果底层存储不支持条件的过滤,我们是先从存储中拿到数据然后通过 server 端的进行过滤。分布式的场景下,如果继续在server端进行过滤,那么需要走网络返回大量的数据,效率非常低下,所以应用了算子下沉的方案在store端把数据处理完成再返回 server 端。2.12 分布式集群管理-增加新的节点(peer迁移)
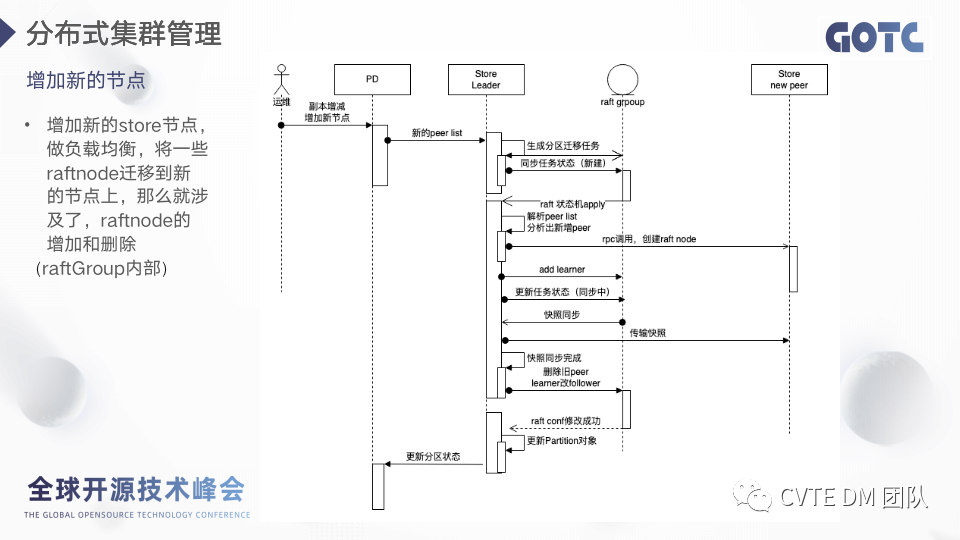
这个场景是指增加新的 store 节点,然后做负载均衡,将一些 raftnode 迁移到新的节点上,那么就涉及了,raftnode 的增加和删除。这种操作是单个raftgroup内部的操作,不涉及 raft 之上数据的读写。所以会先在新的store节点上创建raftnode,成为learner,然后将raftgroup的快照同步过去完成之后learner会转变为follower,预示着新节点的数据与其他节点是完全一致的了,这个时候再删除旧的raftnode即可。最后是更新pd的分区信息。2.13 分布式集群管理-分区分裂与合并

这个场景是指的是单个分区的数据大到一定程度,需要分裂成多个分区,或者单个分区的数据小到一定程度,需要与其他的合并。很明显这种操作是跨多个raftgroup的数据同步,需要在raft上层进行数据的读写。
序列图是分裂的流程,首先会新建一个新的raftgroup,然后从源分区leader读取数据,批量写入,然后更新分区信息,最后清除数据。
合并的流程也是类似,把数据从一个raftgroup,批量copy到另外一个raftgroup,完成之后,更新源数据,销毁raftgroup。 三、应用与展望
3.1 CVTE 基于 HugeGraph 的图平台建设
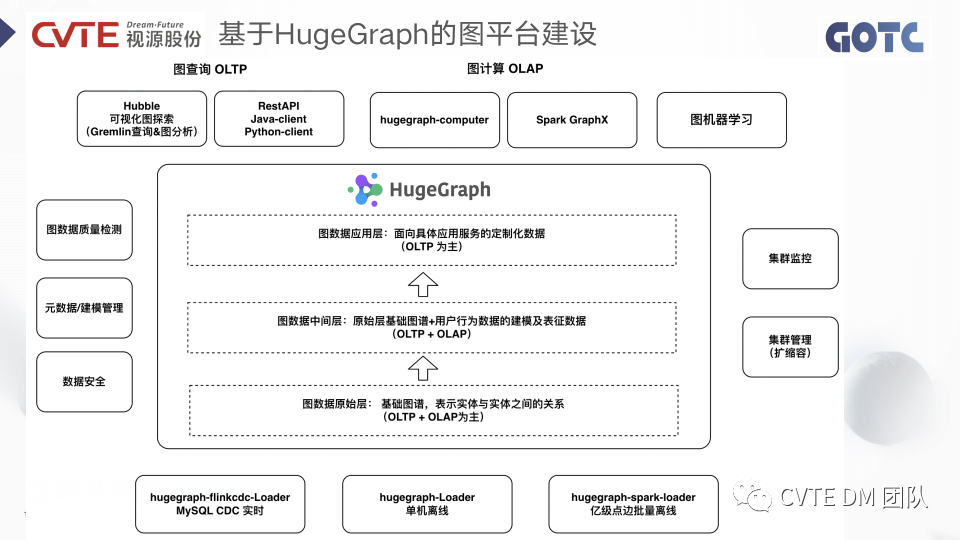
CVTE 目前基于 HugeGraph 构建了图数据平台支撑不同场景的业务需求。以 HugeGraph 作为底座,分为了三层,原始层,中间层和应用层,以教育搜推场景举例,原始层负责存储基础图谱数据,比如知识点、概念、题目、学生等等实体之间的关联关系,这一层的查询场景主要以图计算 OLAP 为主,同时也会涉及一些实体关系的可视化查询。中间层由原始层的基础图谱结合用户行为数据以及表征数据构建,比如学生对知识点的掌握度情况,班级掌握度情况等等,图数据应用层是直接面向具体应用服务的定制化数据,比如学生的推荐题目、课程等等,以 OLTP 为主,性能要求较高。为了保证图平台的稳定性和易用性,我们做了很多的工作。· 在数据接入端支持了 flinkcdc 和 spark ,以适应图数据实时和批量写入的场景。
· 集群管理方面包括节点管理、扩缩容、服务器监控、服务进程监控、告警。
· 图数据管理方面包括图数据质量检测,元数据/建模管理,数据安全管理等等。
· 在应用层针对 OLTP 做了更多客户端和可视化的支持,针对 OLAP 集成了 Spark Graphx ,基于 computer 支持了更多的图算法,同时打通了基于 HugeGraph 的图机器学习pipeline。
目前团队也将很多二次开发的成果贡献给了社区,包括python客户端、flinkLoader、sparkLoader、toolchain的优化等等,同时也在积极参与分布式版本的研发。3.2 HugeGraph 在 CVTE 的应用

基于HugeGraph实现的图平台, 支撑了 CVTE 包括教育和企业服务等多个业务场景的应用,例如,基于 hugegraph-computer 做的搜索推荐召回、风险控制,基于图库和可视化做的知识图谱、知识库,另外我们自研了一套数据血缘系统,用于做数仓海量数据的问题溯源,结构变更的影响范围等等,图机器学习方面,将HugeGraph作为数据数据端,构建基于HugeGraph的图机器学习pipline...... 目前正在做或者已经实现的应用包括:· 搜索推荐:个性化推题、推荐关注、薄弱知识点智能复习、教师资源推荐....· 知识图谱:教育知识概念图谱,产业链图谱,人才图谱......· 知识库:教育知识库,人才知识库(知识库包括规则,过程性知识(知识抽取)等)......· 数据血缘:基于 Hive、SparkSQL、FlinkSQL 等大数据组件的全局数仓数据血缘实现......· 图机器学习:作为图机器学习(图表示学习/图神经网络)的数据输入端,构建基于HugeGraph的图机器学习pipline......3.3 目前版本的痛点
· 单次查询数据量大时内存占用多, 线程无法提前终止, 没有细粒度的内存管控
· Hbase 方案体系重, 依赖多, 难上云, 虽能支持千亿数据但是难以同时保证高性能
· RocksDB 方案维护难, 观测难, 调优难, 对普通用户使用门槛高
· 新用户仍然需要学习较为复杂的图查询语言, 并有较高的迁移门槛
· 缺少一体化的业务解决方案, 单纯图数据/图计算系统离用户距离远
3.4 Apache HugeGraph 后续规划
· 基于分布式版本持续做更多的优化,保证集群稳定性
· 持续优化图查询, 实现内存管控的完整体系
· 更多的图分析算法支持, 尤其是提供图产品化的解决方案, 大幅降低使用门槛
· 更完整的生态建设,包括与大数据生态的集成、与图计算、图可视化框架的集成等等
· 查询辅助功能,通过类 GPT 模型将自然语言转化为图查询语言
· 探索优化/增强 RocksDB, 改善 RocksDB 难维护, 易用性弱, 配置复杂等问题

作者介绍:Simon Cheung,CVTE中央研究院数据挖掘团队-图数据库负责人,主要研究方向为大数据与图数据库领域的技术与应用。Apache HugeGraph及Apache Seatunnel Committer。