





导语
PostgreSQL的numeric类型
在介绍Vastbase的number类型之前,我们先介绍一下PostgreSQL的numeric类型。浮点数的通用表示方式为: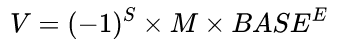
注:
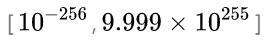 。NumericLong的表示范围高达:
。NumericLong的表示范围高达: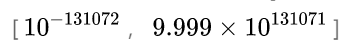 。小范围的数值使用NumericShort格式存储,可以节省存储空间。当数值的表示范围超过NumericShort的范围时,PostgreSQL把数值切换为NumericLong格式进行存储,以占用2字节的代价换取更大的数值表示范围。但同时,这种实现方式增加了运算和比较的复杂度,使性能降低。
。小范围的数值使用NumericShort格式存储,可以节省存储空间。当数值的表示范围超过NumericShort的范围时,PostgreSQL把数值切换为NumericLong格式进行存储,以占用2字节的代价换取更大的数值表示范围。但同时,这种实现方式增加了运算和比较的复杂度,使性能降低。● 特殊值,numeric除了可以表示普通的数值外,还可以表示NAN、
+INF、-INF这些特殊值,比较和运算时,需要判断numeric是否为特殊
值,大量的if分支判断增加比较和运算的开销,性能下降。
代码片段1:/*在header里设置了相应的特殊值,则浮点数可以表示NAN、+INF、-INF这些特殊值*/#define NUMERIC_IS_NAN(n) ((n)->choice.n_header == NUMERIC_NAN)#define NUMERIC_IS_PINF(n) ((n)->choice.n_header == NUMERIC_PINF)#define NUMERIC_IS_NINF(n) (n)->choice.n_header == NUMERIC_NINF)
01
精度高,几乎没有限制。但同时,精度越高,需要占用存储空间就越大,运算时,需要在堆上申请一次内存,增加其运算开销。
代码片段2:/*由于numeric最多可以占用1G空间,中间结果无法在栈上分配内存*需要在堆上申请足够的内存来保存中间结果,运算完成后,又要释放其中间结果*频繁申请和释放内存,增加了numeric运算的开销 */Numeric numeric_add(NumericVar arg1, NumericVar arg2){add_var(&arg1, &arg2, &result); *需要在堆上申请内存保存中间结果*/res = make_result_opt_error(&result);free_var(&result); /*释放中间结果的内存*/return res;}
02
代码片段3:/*因为numeric有两种存储格式,无法直接进行运算和比较*计算开始前,需要先从存储格式转为内存格式*计算完成后,根据数值的范围,选择一种合适的存储格式,又把内存格式转为该存储格式*这些转换操作,增加了numeric的运算和比较的开销,导致性能下降*/Numeric numeric_add(Numeric num1, Numeric num2){NumericVar arg1;NumericVar arg2;init_var_from_num(num1, &arg1); *num1从存储格式转为内存格式*/init_var_from_num(num2, &arg2); *num2从存储格式转为内存格式*/add_var(&arg1, &arg2, &result); /*使用内存格式进行运算*/res = make_result(&result); *把结果从内存格式转换为合适的存储格式*/return res;}
03
Vastbase的number类型
01
注:
02
03
04
number类型的内存布局:

注:
注:
我们规定,尾数规范化为[1, 10000) 之间的一个小数。规范化操作非常重要,考虑符号相等、E值不等的两个数值: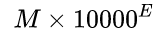 ,M值已经规范化,我们通过比较E值的大小,即可得出两个数值的大小关系,从而避免复杂度较高的M值比较。
,M值已经规范化,我们通过比较E值的大小,即可得出两个数值的大小关系,从而避免复杂度较高的M值比较。
范围和精度均比Oracle number类型大,可以满足Oracle兼容性要求,满足大部分场景的使用需求。
通过限制其最大精度,使得number运算时,不再需要在堆上申请内存保存中间结果,减少了运算的开销。
统一了存储格式,运算和比较时,可以直接使用存储结构,避免存储格式和内存格式间的互转带来的开销。
number类型的排序规则
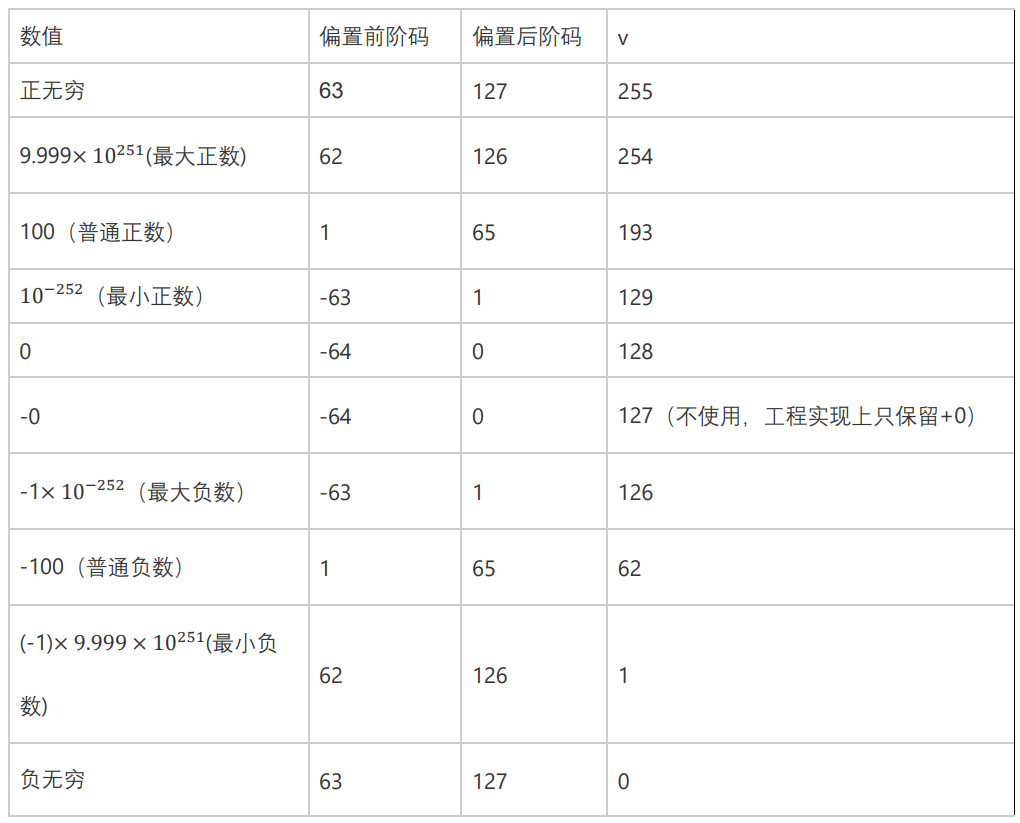
比较uint8的值,如果两个uint8大小不相等,则可以直接推断出两个number的大小关系
uint8的值相等,说明其符号、E值均相等,只需要再比较M值,就可以得出number的大小关系
+INF
普通正数,E值越大,number越大(注意E值为负数的情况)
0
普通负数,E值越小,number越大(注意E值为负数的情况)
-INF
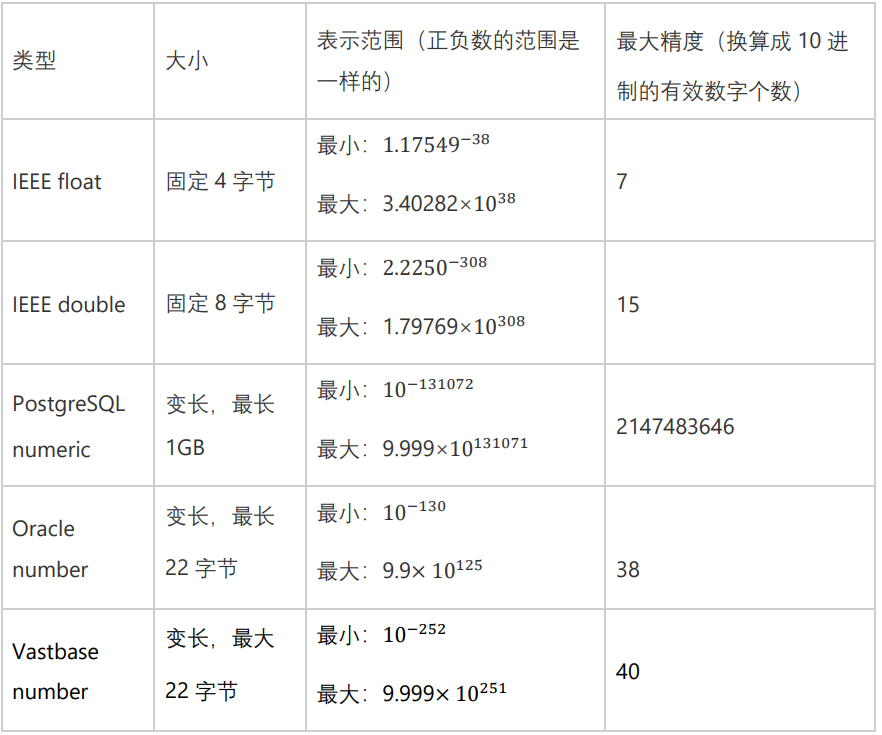
对于所有number,E值+64,记作v。我们把+64称为偏置值,这条规则保证所有E值偏置后都大于等于0。
对于所有number,v = v + 128(等价于v值与sign值取或运算,注意规则3对负数取反码,正好抵消了+128这个操作),这条规则保证了所有正数比负数都大
如果number为负数,v = 255 - v(等价于uint8按位取反码),这条规则保证了所有负数的number,v值越大,number的值越大。
性能对比
运算
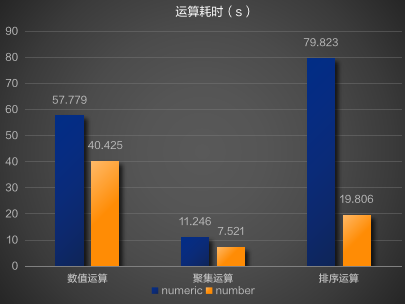
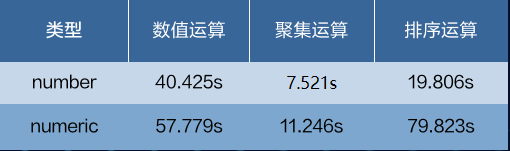
只统计ProjectSet算子,即只包含数值运算,number的运行时间是numeric的69.9%
numeric: 57.779s
number: 40.425s
排序
聚集
总结:
测试结果显示,number的运算、聚集、排序的性能均比numeric有较大的提升,其中排序性能提升约4倍。
图文编辑|程筱淇
内容审核|市场营销部
关于海量数据
北京海量数据技术股份有限公司(股票代码:603138.SH)成立于2007年,是国内首家以数据库为主营业务的主板上市企业。公司十余年来秉承“专注做好数据库”的初心,始终致力于数据库产品的研发、销售和服务。核心产品海量数据库Vastbase系列、数据库一体机Vastcube系列,全栈国产化,应用满足度高,目前广泛应用于政务、制造、金融、通信、能源、交通等多个重点行业,已成为国产企业级数据库的首选之一。

