





# 环境说明
数据库:MySQL 8.0.20双主
# 问题现象
MySQL数据库从库所在虚拟机异常宕机,虚拟机恢复后,从库SQL线程无法正常启动,报错如下:
Last_Errno: 1782Last_Error: Error executing row event: '@@SESSION.GTID_NEXT cannot be set to ANONYMOUS when @@GLOBAL.GTID_MODE = ON.'
# 问题分析
简单回顾下主从复制过程:
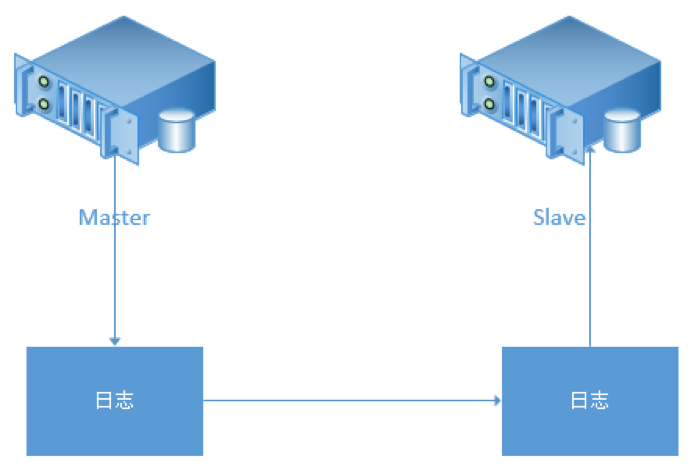
不同类型的数据库,主从复制原理大致相同,通常经历下面三个步骤:
主库日志发送;
从库日志接收;
从库日志应用。
对于MySQL数据库,主库的更新事件(update、insert、delete)会按照顺序写入binlog日志中,主库binlog dump thread读取binlog数据,并发送给从库I/O线程,从库I/O线程将接收到binlog数据写入到从库本地relaylog文件,从库SQL线程解析relaylog文件,将数据按顺序回放到从库,从而实现主从数据同步。
同理,Oracle DG同步原理也是类似,具体名称和实现方式略有差异,Oracle的RFS进程负责接收日志,类似于MySQL的I/O线程,MRP/LSP负责日志应用,类似于MySQL的SQL进程。
原理了解以后,再回到一开始的问题,数据库从库所在虚拟机异常宕机,恢复后,MySQL从库I/O线程、SQL线程是如何自动恢复的,这时面临两个问题:
(1)I/O线程如何找到最后一次接收主库数据的位置信息,进行数据的断点续传。
(2)SQL线程如何找到宕机前最后一次应用relaylog日志的位置信息,进行断点数据的继续应用。
I/O线程断点续传方式如下:
从库的I/O线程通过读取mysql.gtid_executed表以及binlog文件获取Executed_Gtid_Set,通过读取realy_log文件获取Retrieved_Gtid_Set,并将三者的并集发送到主库请求binlog。
(1)mysql.gtid_executed
mysql.gtid_executed记录从库执行过的事务开始ID(UUID、开始事务ID、结束事务ID)。
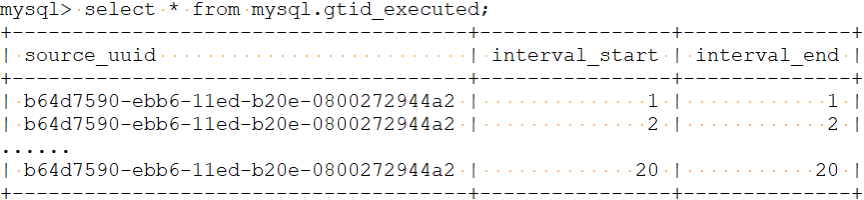
(2)binlog
例如:

通过上面查到的mysql.gtid_executed、binlog、relaylog取并集发送到主库,并和主库的gtid做比较。
主库查询方式:
Select * from mysql.gtid_executed;show global variables like 'GTID_EXECUTED';show master status\G;
具体从库发给主库的GTID:
UNION(@@global.gtid_executed, Retrieved_gtid_set - last_received_GTID)
为什么需要减去last_received_GTID?
因为I/O线程读取主库binlog时,是以event为单位进行读取的,而一个事务包含了一个event组,当突然执行stop slave或者其他异常行为时,可能导致一个事务只读取了部分event,如果不减去这个binlog读取不完整的GTID,有可能导致SQL线程复制报错终止。
名词解释:
Retrieved_Gtid_Set:表示slave从master接收的gtid set。
Executed_Gtid_Set:表示slave已执行的gtid set。
last_received_GTID:表示最后一个事务信息。
最终:
将主库的GTID事务和从库事务做差集就是从库没有接收到的事务,主库会将这部分事务对应的binlog数据发送给从库,从库接收后写入自己本地的relaylog日志。
例如:
主库存在1,2,3,4,5个事务,从库存在1,2,3,4个事务,经过比对后,主库会将事务5对应的binlog数据发送给从库。
SQL线程断点续传方式如下:
对于备库的SQL线程其应用relay log的起始从mysql.slave_relay_log_info表读取,slave_relay_log_info表记录了SQL线程工作位置信息,它会把值传给”show slave status”中的Relay_Log_File、Relay_Log_Pos。
slave_relay_log_info表数据来源:
当relay_log_info_repository=TABLE时,apply event和更新slave_relay_log_info表是在一个事务内完成的,也就是事务提交信息同步到slave_relay_log_info表。
mysql> select * from mysql.slave_relay_log_info\G;
例如:
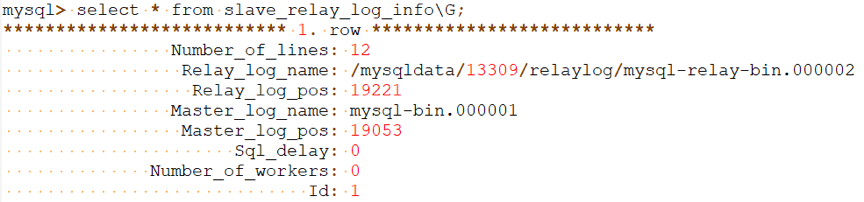
备库通过查询mysql.slave_relay_log_info表,知道了宕机前最后一次读取到的文件是mysql-relay-bin.000002,位置信息是19221,那么SQL线程就会从这个位置开始应用数据回放到从库。
下面回到最开始的问题,SQL线程启动报错1782:
启动SQL线程,报错1782:
Last_Errno: 1782Last_Error: Error executing row event: '@@SESSION.GTID_NEXT cannot be set to ANONYMOUS when @@GLOBAL.GTID_MODE = ON.'
SQL线程在读取指定relaylog日志,回放数据时发生了错误,通过报错信息,从库启用了GTID复制,在应用数据时发现存在匿名事务,导致失败。
通过mysqlbinlog分析relaylog日志数据:
mysqlbinlog --base64-output=decode-rows --verbose mysql-relay-bin.00xxx
部分内容如下:
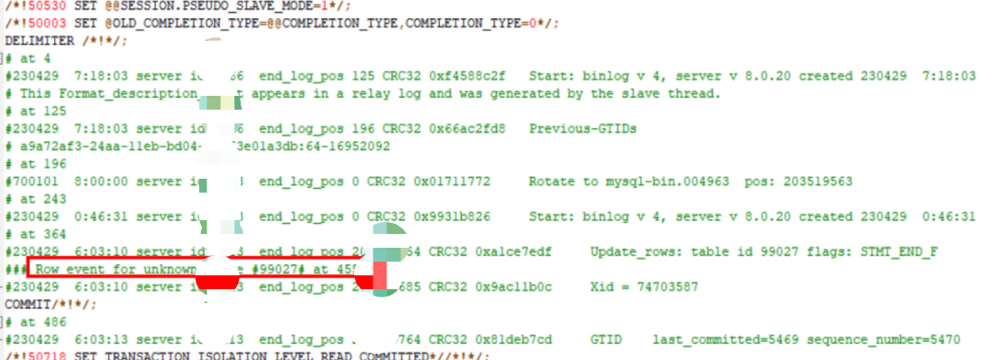
at 364 出现 Row event for unknown table #99027
还有一个没有分配GTID的commit,被SQL线程识别为匿名事务,从而导致SQL线程启动失败。
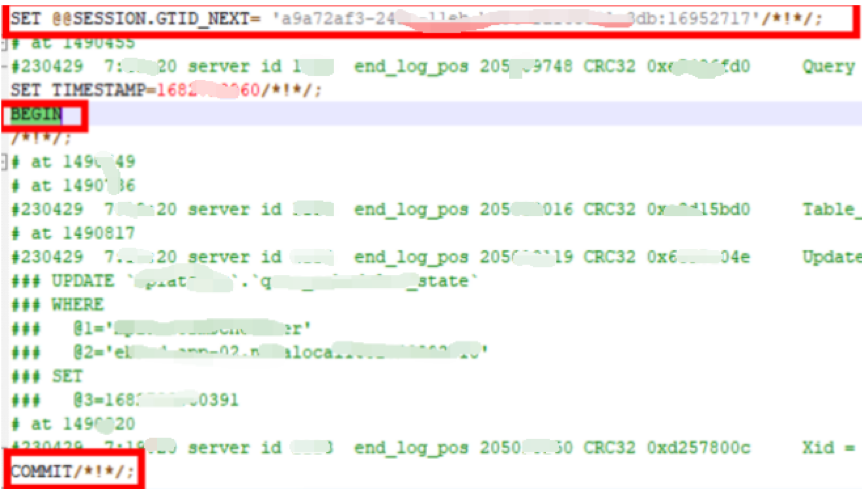
正常的事务
应该具有明确的GTID.NEXT、BEGIN、COMMIT信息。
例如:
# 故障原因
relaylog日志中为什么会出现不完整的事务,经分析,导致1782错误可能的原因如下:
(1)BUG
在5.7之前的版本,同一个事务不能跨多个binlog,但是可以跨越多个relaylog。
这意味着mysql在读取以半事务开始的中继日志时会生成类似于1782的错误。
参数max_relay_log_size限制单个relaylog大小,当达到最大大小,会自动切换到新的relaylog。
但是5.7开始,同一个事务也不会跨多个relaylog,当有一个大事务发生时,relaylog大小会超过max_relay_log_size。
当前数据库版本8.0.20,经测试,不存在这个BUG导致。
(2)GTID复制模式并不是一开始就启动的
例如,一开始是传统复制模式,后来通过命令转换为GTID复制模式。
参考:甲骨文官网知识库 https://support.oracle.com 文章编号 2807183.1


原因:

当前数据库GTID复制模式已经运行很长时间,并不是刚刚转换成GTID模式。
(3)relaylog损坏
当前relaylog部分内容损坏,导致SQL线程无法正常解析relaylog日志,本次故障初步怀疑文件损坏导致的。
# 解决方案
官网知识库提供的解决方案如下:
具体解决步骤如下:
参考:甲骨文官网知识库 https://support.oracle.com 文章编号 2807183.1
从库:
(1)停同步
stop slave;
(2)清空同步信息
reset slave all;
(3)重新配置主从连接
CHANGE MASTER TOMASTER_HOST='主库IP',MASTER_USER='XXXX',MASTER_PASSWORD='******',MASTER_PORT=XXXX,MASTER_AUTO_POSITION=1;
(4)启动同步
start slave;
(5)验证
show slave status\G;
经验证,此方法确实可以解决测试复现后的1782问题。
当然,如果此方法仍然部分解决1782问题,也可以考虑重新初始化从库。
# 问题思考
为什么重启slave不能解决1782错误,change master创建主从关系可以解决呢?
原因是两种方式在启动slave时,查找复制位置方式不同。
通过重启slave查找复制位置:
(1)从库mysql.gtid_executed表、binlog文件、relaylog文件中取出gtid事务信息和主库gtid事务做比较,差集对应的binlog数据需要重新从主库拉取。
(2)然后在根据mysql.slave_relay_log_info的位置信息开始应用relaylog日志。
通过change master查找复制位置:
因为change master后又执行了reset slave all,清空了本地所有的relaylog日志,同时清空了show slave status\G中的Retrieved_Gtid_Set信息(记录slave从master接收的gtid set)和mysql.slave_relay_log_info表数据,但不会清空mysql.slave_relay_log_info信息(记录slave已执行的gtid set),除非执行reset master;
从库SQL线程位置为起点重新向主库拉取binlog日志并生成新的relaylog日志,从而避免了从库因relaylog损坏或不完整导致的复制中断问题。
(1)从库根据mysql.slave_relay_log_info的位置信息拉取主库的binlog数据。
(2)然后在根据mysql.slave_relay_log_info的位置信息开始应用relaylog日志。
如何避免此类问题再次发生?
如何避免从库异常宕机,并且从库当前relaylog损坏导致复制中断?
需要改变从库启动slave拉取binlog或relaylog的方式:
由原来的:以I/O线程位置为起点向主库拉取binlog方式。
改成:以SQL线程位置为起点向主库拉取binlog方式。
优点:
避免了因relaylog损坏导致复制中断的问题。
缺点:
当SQL线程速度远远落后于I/O线程时,以SQL线程位置为起点向主库拉取binlog方式需要拉取更多的binlog日志,速度较慢。
例如:
主库执行了1,2,3,4,5共五个事务。
从库I/O线程已经拉取完成了1,2,3,4共四事务。
从库SQL线程应用了1,2共两个事务。
这时如果从库异常宕机,启动后,会从事务3开始重新拉取。
如何更改这种方式?
受参数relay_log_recovery控制,默认OFF。
当启用relay_log_recovery后,会变成以SQL线程位置为起点向主库拉取binlog方式。
此参数为只读参数,不支持在线修改,更改完配置文件后,重启数据库生效。
实际上,早在MySQL5.6就已经提供了crash safe slaves功能。
该功能主要解决之前版本中系统异常断电等场景可能导致的I/O、SQL线程信息不准确问题。
那么哪些场景可能会出现I/O,SQL线程信息不准确?
1.relay log损坏,导致SQL线程失败,可以通过relay_log_recovery参数解决。
2.binlog位置信息不准确,当master_info_repository为FILE时,binlog位置信息不是实时记录的,因为表数据更新和磁盘FILE文件更新很难做到实时同步,需要将master_info_repository改成TABLE,也就是将binlog位置信息记录到数据库表里,这样就可以将业务操作和更新binlog信息的操作放到一个事务里,从而解决数据不一致的问题。
3.和第2点类似,relaylog位置信息也可能不准确,也需要将relay_log_info_repository改成TABLE。
除此以外,sync_binlog、sync_relay_log、innodb_flush_log_at_trx_commit等参数也会影响数据的准确性,当然参数的安全级别越高,性能通常也是最差,实际使用过程中,需要结合每套库的特点,选择适合的参数。
主从复制源码解析:
由于篇幅有限,MySQL主从同步还有很多细节没有讨论,例如Relay_log_info记录了哪些信息,如何更新,更新触发条件等,如果感兴趣可以下载源码进行深入研究。
获取MySQL源码方式:
官网下载指定版本源码安装介质,例如MySQL 8.0.22:
解压后,进入sql目录下
Relay_log_info相关信息,可以查看rpl_rli.cc文件,部分内容如下:


- E N D -
文章作者:陈举超
手绘插画:岳 媛


