





数据库的查询优化器是整个系统的"大脑",一条SQL语句执行是否高效在不同的优化决策下可能会产生几个数量级的性能差异,因此优化器也是数据库系统中最为核心的组件和竞争力之一。阿里云瑶池旗下的云原生数据库PolarDB MySQL版作为领先的云原生数据库,希望能够应对广泛用户场景、承接各类用户负载,助力企业数据业务持续在线、数据价值不断放大,因此对优化器能力的打磨是必须要做的工作之一。
本系列将从PolarDB for MySQL的查询变换能力开始,介绍我们在这个优化器方向上逐步积累的一些工作。

create table t1 (id int, PRIMARY KEY(id));create table t2 (id int, t1_id int,constraint `t1_id_fk` foreign key (`t1_id`) references `t1` (`id`));select t2.id from t2 join t1 on t2.t1_id = t1.id;
可以看到t2的t1_id列是t1 id列的外键,因此对t2的每一行,一定有且只有一行t1的数据可以和t2 join上,同时整个查询最终并不需要t1表的数据,查询可以简化为:
select t2.id from t2;
基本的思路并不复杂,考虑如下这个join
outer_table LEFT JOIN (inner_table) ON condition(outer_table,inner_table)
由于是LEFT JOIN,外表的数据是不会丢失的,如果同时可以保证:
但实际的查询不可能总是这么简单,我们可以考虑如下几种情况:
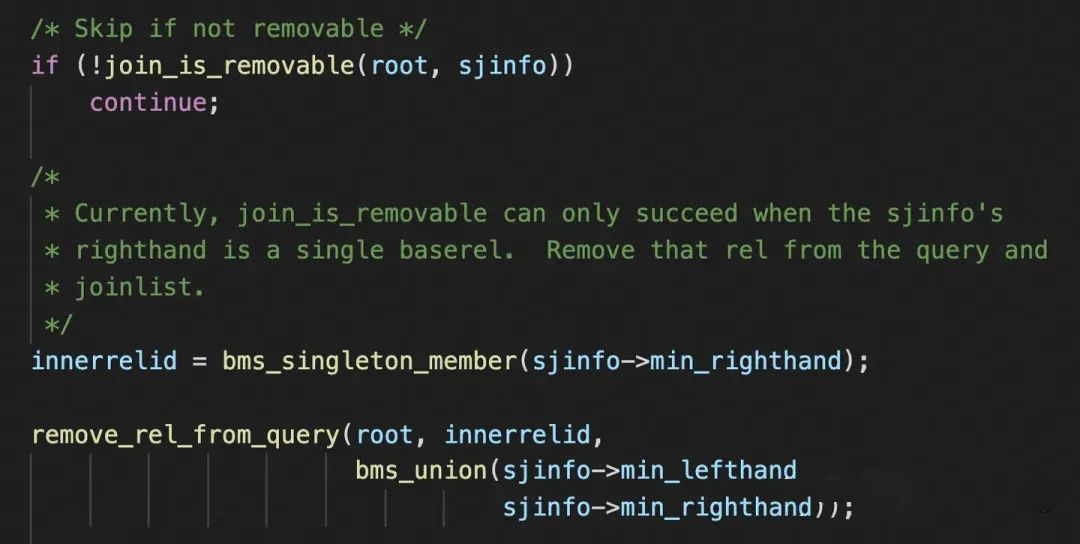
● 一个LEFT JOIN的内部(单表/多表),只有当所有表都保证唯一输出一行时,整个LEFT JOIN才能消除;
● 对内侧的每个单表,当其join条件中涉及的所有列,是某个唯一索引的超集时,该表才能保证输出一行;
● 如果内侧再次包含有LEFT JOIN,则要先深度递归进去,判断这个内侧的LEFT JOIN是否可以消除,消除后再返回来考察外层;
遵循以上的思路依次处理每个子问题,就可以实现对各种复杂场景的可消除性的判定。具体算法和代码这里就先略过了。
看下上面几个问题的具体效果:
create table t1 (a int);create table t2 (a int primary key, b int);create table t3 (a int primary key, b int);1. inner table包含多张表?select t1.a from t1 left join (t2 join t3) on t2.a=t1.a and t3.a=t1.a;=>select t1.a from t1;2. inner table中包含新的left join?select t1.* from t1 left join (t2 left join t3 on t3.a=t2.b) on t2.a=t1.a;=>select t1.* from t1;3. inner table本身是个derived table?select t1.* from t1 left join(select t2.b as v2b, count(*) as v2cfrom t2 left join t3 on t3.a=t2.bgroup by t2.b) v2on v2.v2b=t1.a;=>select t1.* from t1;
当然各种其他场景还有很多,但只要遵循前面提到的几个判定原则,就都可以逐一的完成消除。
与PostgreSQL的对比
PG在计算层的能力一直是其比较引以为傲的点,其统计信息和代价模型是非常优秀的,加上更完备的join ordering算法,确实可以生成较高质量的执行计划。
不过在查询变换方面,Postgres的能力也只能说相当一般(有机会后续会写文章介绍PG的优化器),它也实现了left join消除的功能,基本思路与PolarDB的一致,基于内表的唯一性判定,但其支持的场景就更为简单了:
● 只能支持left join的内侧是一个base relation,或者是一个subquery;
query_is_distinct_for(Query *query, List *colnos, List *opids)
这个函数,不过其思路和实现都非常简单,PolarDB后续也会类似去扩展下。
EXPLAIN SELECT count(*)FROM t1LEFT JOIN (t2LEFT JOIN t3ON t2.b = t3.bAND EXISTS (SELECT t0.aFROM t0WHERE t0.a = t3.b)) ON t1.a = t2.a;
这里由于t2.b = t3.b这样的join条件,t3.b不是唯一键,这个查询是无法消除join的,而MariaDB的执行计划如下:
+------+--------------------+-------+--------+---------------+---------+---------+-----------+------+-------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+------+--------------------+-------+--------+---------------+---------+---------+-----------+------+-------------+| 1 | PRIMARY | t1 | ALL | NULL | NULL | NULL | NULL | 4 | || 1 | PRIMARY | t2 | eq_ref | PRIMARY | PRIMARY | 4 | test.t1.a | 1 | Using where || 1 | PRIMARY | t3 | ALL | NULL | NULL | NULL | NULL | 2 | Using where || 2 | DEPENDENT SUBQUERY | t0 | ALL | NULL | NULL | NULL | NULL | 4 | Using where |+------+--------------------+-------+--------+---------------+---------+---------+-----------+------+-------------+
+----+--------------+-------------+------------+--------+---------------------+---------------------+---------+--------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+--------------+-------------+------------+--------+---------------------+---------------------+---------+--------------+------+----------+-------------+| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL || 1 | SIMPLE | t2 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 2 | 100.00 | Using where || 1 | SIMPLE | t3 | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | Using where || 1 | SIMPLE | <subquery2> | NULL | eq_ref | <auto_distinct_key> | <auto_distinct_key> | 5 | je_test.t3.b | 1 | 100.00 | Using where || 2 | MATERIALIZED | t0 | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL |+----+--------------+-------------+------------+--------+---------------------+---------------------+---------+--------------+------+----------+-------------+
t0还是通过semi-join MATERIALIZATION的方式来实现,效率会高很多。
EXPLAIN SELECT count(*)FROM t1LEFT JOIN t2 ON t1.a = t2.aLEFT JOIN t3 ON t2.b = t3.a;
MariaDB由于算法和实现的限制,效果如下:
+------+-------------+-------+--------+---------------+---------+---------+-----------+------+-------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+------+-------------+-------+--------+---------------+---------+---------+-----------+------+-------------+| 1 | SIMPLE | t1 | ALL | NULL | NULL | NULL | NULL | 4 | || 1 | SIMPLE | t2 | eq_ref | PRIMARY | PRIMARY | 4 | test.t1.a | 1 | Using where |+------+-------------+-------+--------+---------------+---------+---------+-----------+------+-------------+
在这样一个简单查询中,很明显t2/t3都是可以消除掉的,但MariaDB竟然只能处理t3表的join消除。
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
SELECT count(*)FROM `shop_customer` `sc`LEFT JOIN `car` `ca` ON `sc`.`car_id` = `ca`.`id`LEFT JOIN `company` `co` ON `sc`.`company_id` = `co`.`id`;=>SELECT count(*) FROM `shop_customer` `sc`;
很明显最后可以变成单表的查询,在消除前,执行时间是7.5s,消除后是0.1s,提升了75倍。
1. MySQL的各个原有变换,加的都比较"随意",其自身和原有处理流程的耦合导致增加新变换很困难;
2. 变换执行时机不合理,不同变换之间是存在一定前后依赖关系的,这种关系并没有很好的被利用;
1. 解耦原有的resolve + transform交错的流程,把变换作为单独的步骤,以"规则"为单位,各自独立完成,这样变换就可以通过添加新规则而不断独立扩展;
2. 在基于规则的抽象后,引用枚举框架来枚举不同变换(规则)间的先后顺序,通过反复迭代也可使得相互依赖的规则都可以按照更优的顺序被执行;
云原生数据库PolarDB MySQL版开通免费试用啦!
阿里云推出“飞天免费试用计划”,面向国内1000万云上开发者,提供云产品免费试用。云原生数据库PolarDB MySQL版现推出3个月【免费试用】,快来领取吧!
点击文末「阅读原文」即刻开启云上实践之旅!





点击阅读原文免费试用 云原生数据库PolarDB
