







在指定的文档中查找一个模式有很多种办法,例如可以用grep命令搜索一个正则表达式。理论上,对数据库中的文本字段也可以用类似grep的方式来检索模式,GaussDB(DWS)中就可以通过关键字“LIKE”或操作符“~”来匹配字符串。但这样做有很多问题。首先对每段文本都要扫描,效率比较低,难以衡量“匹配度”或“相关度”。而且只能机械地匹配字符串,缺少对语法语义的分析能力,例如对英语中的名词复数,动词的时态变换等难以自动地识别和匹配,对于由自然语言构成的文本无法获得令人满意的检索结果。
GaussDB(DWS)采用类似搜索引擎的方式来进行全文检索。首先对给定的文本和模式做预处理,包括从一段文本中提取出单词或词组,去掉对检索无用的停用词(stop word),对变形后的单词做标准化等等,使之变为适合检索的形式再作匹配。
GaussDB(DWS)中,原始的文档和搜索条件都用文本(text)表示,或者说,用字符串表示。经过预处理后的文档变为tsvector类型,通过函数to_tsvector来实现这一转换。例如:

观察上面输出的tsvector类型,可以看到to_tsvector的效果:
首先各个单词被摘取出来,其位置用整数标识出来,例如“fat”位于原始句子中的第2和第5个词的位置。
此外,“a”这个词太常见了,几乎每个文档里都会出现,对于检索到有用的信息几乎没有帮助。套用香农理论,一个词出现的概率越大,其包含的信息量越小。像“a”,“the”这种单词几乎不携带任何信息,所以被当做停用词(stop word)去掉了。注意这并没有影响其他词的位置编号,“fat”的位置仍然是2和5,而不是1和4。
另外,复数形式的“rats”被换成了单数形式“rat”。这个操作被称为标准化(Normalize),主要是针对西文中单词在不同语境中会发生的变形,去掉后缀保留词根的一种操作。其意义在于简化自然语言的检索,例如检索“rat”时可以将包含“rat”和“rats”的文档都检索出来。被标准化后得到的单词称为词位(lexeme),比如“rat”。而原始的单词被称为语言符号(token)。

从上面的例子可以看到:
跟to_tsvector类似,to_tsquery也会对输入文本做去掉停用词、标准化等操作,例如去掉了“a”,把“cats”变成“cat”等。
输入的检索条件本身必须用与(&)、或(|)、非(!)操作符连接,例如下面的语句会报错。

但plainto_tsquery没有这个限制。plainto_tsquery会把输入的单词变成“与”条件:
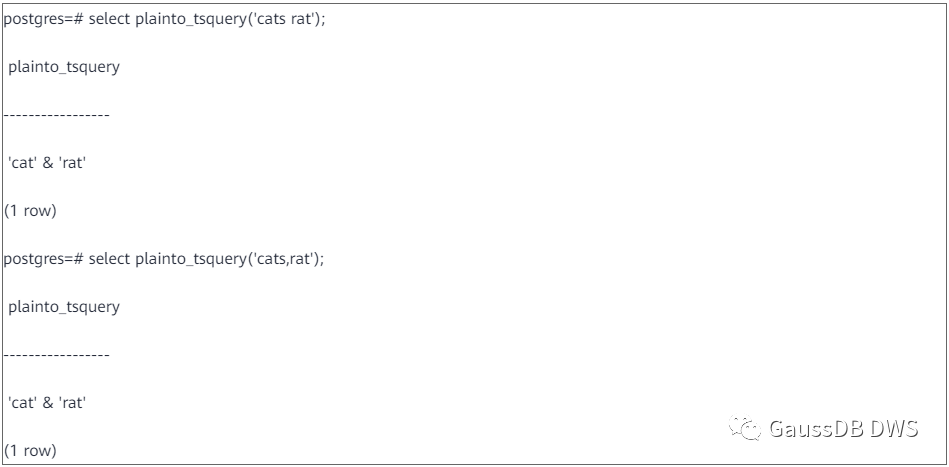
除了用函数之外,还可以用强制类型转换的方式将一个字符串转换成tsvector或tsquery类型,例如:
把输入文档和检索条件转换成tsvector和tsquery之后,就可以进行模式匹配了。GaussDB(DWS)中使用“@@”操作符来进行模式匹配,成功返回True,失败返回false。
例如创建如下表格:

然后想检索body中含有“physics”或“math”的帖子标题,可以用如下的语句来查询:

也可以将多个字段组合起来查询:

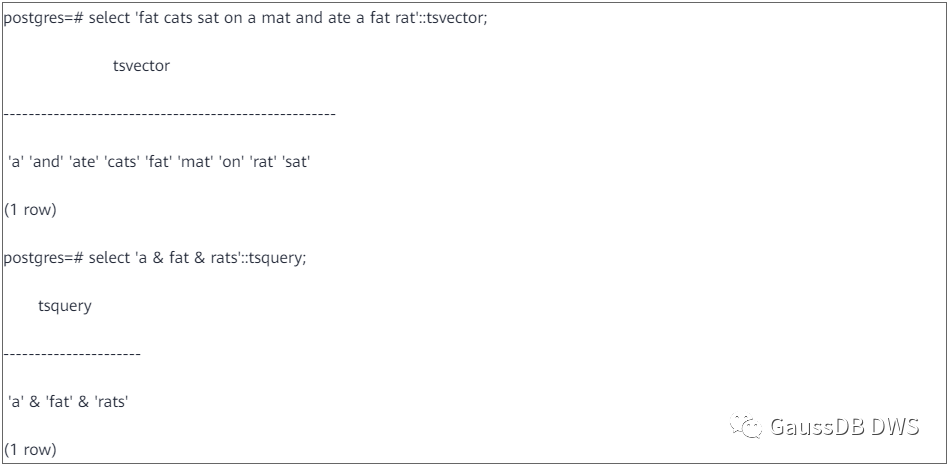
注意不同的查询方式可能产生不同的结果。例如下面的匹配不成功,因为::tsquery没对检索条件做标准化,前面的tsvector里找不到“cats”这个词:

而同样的文档和检索条件,下面的匹配能成功,因为to_tsquery会把“cats”变成“cat”:

类似地,下面的匹配不成功,因为to_tsvector会把停用词a去掉:

而下面的能成功,因为::tsvector保留了所有词:

所以应根据需要选择合适的检索方式。
此外,@@操作符可以对输入的text做隐式类型转换,例如:
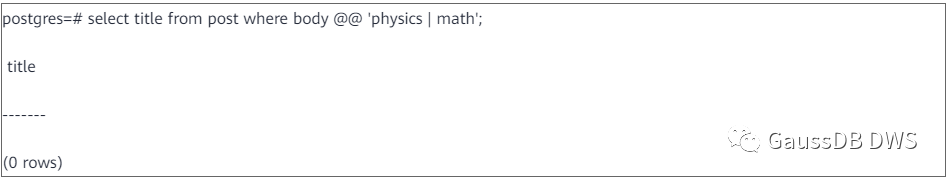
准确来讲,text@@text相当于to_tsvector(text) @@ plainto_tsquery(text),因此上面的匹配不成功,因为plainto_tsquery会把或条件'physics | math'变成与条件'physic' & 'math'。使用时要格外小心。
前文提到,逐个扫描表中的文本字段缓慢低效,而索引查找能够提高检索的速度和效率。GaussDB(DWS)支持用通用倒排索引GIN(Generalized Inverted Index)进行全文检索。GIN是搜索引擎中常用的一种索引,其主要原理是通过关键字反过来查找所在的文档,从而提高查询效率。可通过以下语句在text类型的字段上创建GIN索引:

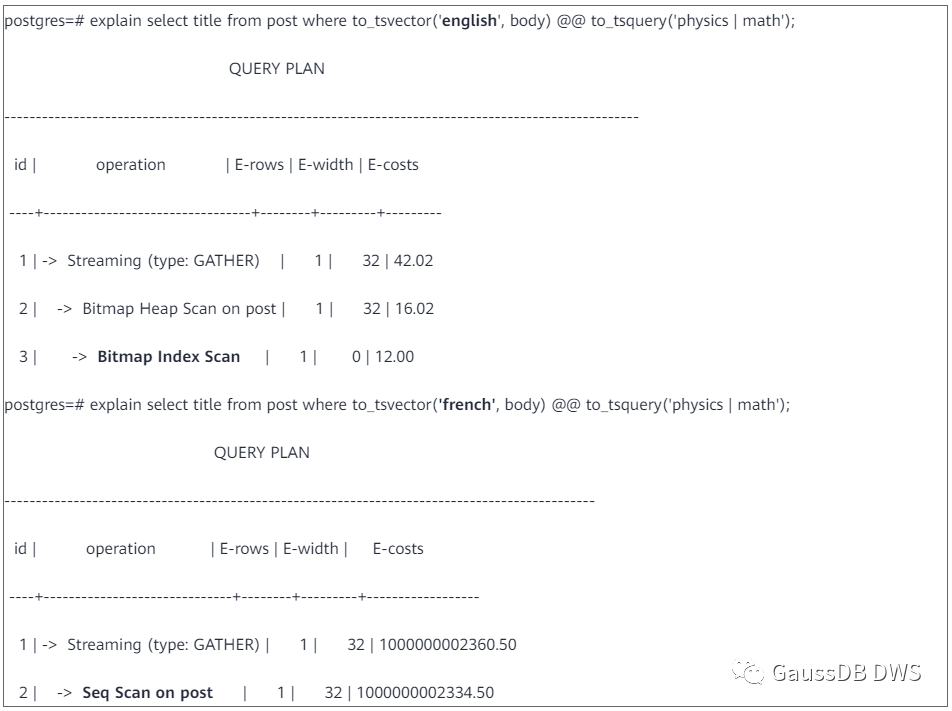
注意这里必须使用to_tsvector函数生成tsvector,不能使用强制或隐式类型转换。而且这里用到的to_tsvector函数比前一节多了一个参数’english’,这个参数是用来指定文本搜索配置(Text search Configuration)的。关于文本搜索配置将在下一节介绍。不同的配置计算出来的tsvector不同,生成的索引自然也不同,所以这里必须明确指定,而且在查询的时候只有配置和字段都与索引定义一致才能通过索引查找。例如下面的查询中,前一个可以通过post_body_idx_1来检索,后一个找不到对应的索引,只能通过全表扫描检索。
第一步,将文本中的单词或词组一个一个提取出来。这项工作由解析器(Parser)或称分词(Segmentation)器来进行。完成后文档变成一系列token。 第二步,对上一步得到的token做标准化,包括依据指定的规则去掉前后缀,转换同义词,去掉停用词等等,从而得到一个个词位(lexeme)。这一步操作依据词典(Dictionary)来进行,也就是说,词典定义了标准化的规则。 最后,记录各个词位的位置(和权重),从而得到tsvector。
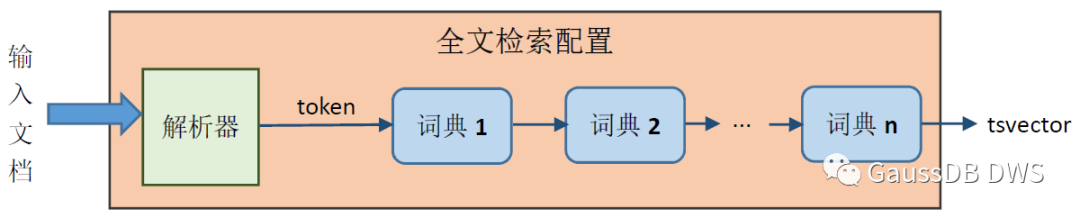
图1 文档预处理过程

词典则通过ALTER TEXT SEARCH CONFIGURATION命令来指定,例如:

指定了mytsconf使用english_stem和simple这两种词典来对“asciiword”类型的token做标准化。
上面语句中的“asciiword”是一种token类型。解析器会对分解出的token做分类,不同的解析器分类方式不同,可通过ts_token_type函数查看。例如,‘default’解析器将token分为如下23种类型:



修改后需要重启进程。



