




数据准备
MySQL作为Flink计算的数据源
MySQL作为Flink计算的结果存储
TiDB在Flink SQL中的使用
CDC在Flink SQL中的使用
总结
01 数据准备
本篇的数据依旧沿用第二篇中创建好的数据,对于jdbc connector的实战,继续计算点击流写到MySQL和TiDB;对于mysql-cdc connector,则需要临时创建table 和以及增删改数据,具体流程放在讲述cdc小节里面。
02 MySQL作为Flink计算的数据源
在Flink SQL实战的第二篇文章介绍过MySQL 作为维度表进行temporal table join的应用,这里不再赘述;本小节主要介绍在MySQL作为source的时候,对scan.* 参数的使用进行探索,这四个参数如下所示:
'scan.partition.column''scan.partition.num''scan.partition.lower-bound''scan.partition.upper-bound'
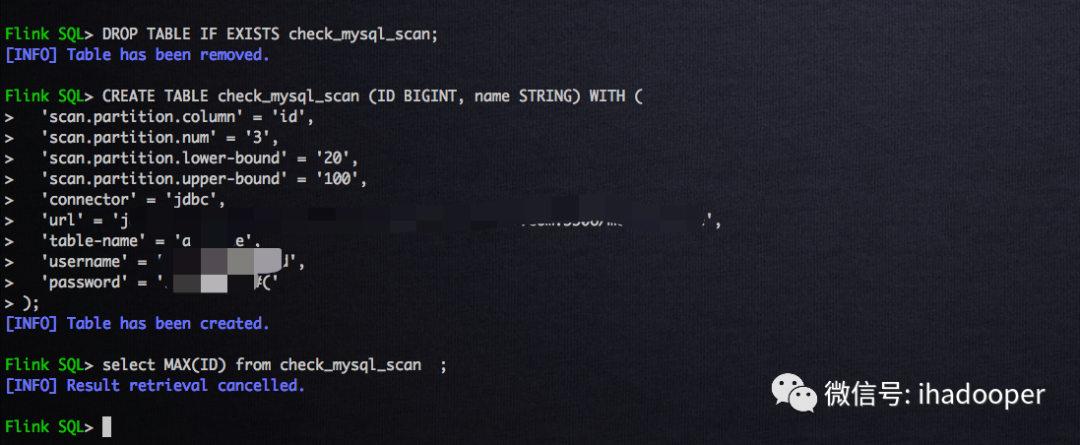
我们根据Flink SQL实战第二篇的广告位, 创建未配置scan相关参数的Flink MySQL table ,详细语句如下所示:
# 创建 Flink MySQl 表, 未配置scan相关的参数CREATE TABLE check_mysql_scan (ID BIGINT,name STRING) WITH ('connector' = 'jdbc','url' = 'url','table-name' = 'adspace','username' = 'username','password' = 'password');# 提交查询, 通过jobGraph,来验证数据select MAX(ID) from check_mysql_scan;
我们根据Flink SQL实战第二篇的广告位, 创建配置scan相关参数的Flink MySQL table ,详细语句如下所示:
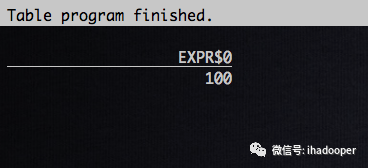
# 创建 Flink MySQl 表, 配置scan相关的参数CREATE TABLE check_mysql_scan (ID BIGINT, name STRING) WITH ('scan.partition.column' = 'id','scan.partition.num' = '3','scan.partition.lower-bound' = '20','scan.partition.upper-bound' = '100','connector' = 'jdbc','url' = 'url','table-name' = 'adspace','username' = 'username','password' = 'password');# 提交查询, 通过jobGraph,来验证数据select MAX(ID) from check_mysql_scan ;
关于Flink SQL JDBC connector的partition相关参数的相关结论如下所示:
'scan.partition.column' = 'id','scan.partition.num' = '3','scan.partition.lower-bound' = '20','scan.partition.upper-bound' = '100',
上述4个参数是MySQL表作为source表的选填参数,当MySQL表数据量很小的时候,可以不用配置;当数据量大的时候,可以同时配置这四个参数来提高读取效率(必须同时填写这4个 参数)
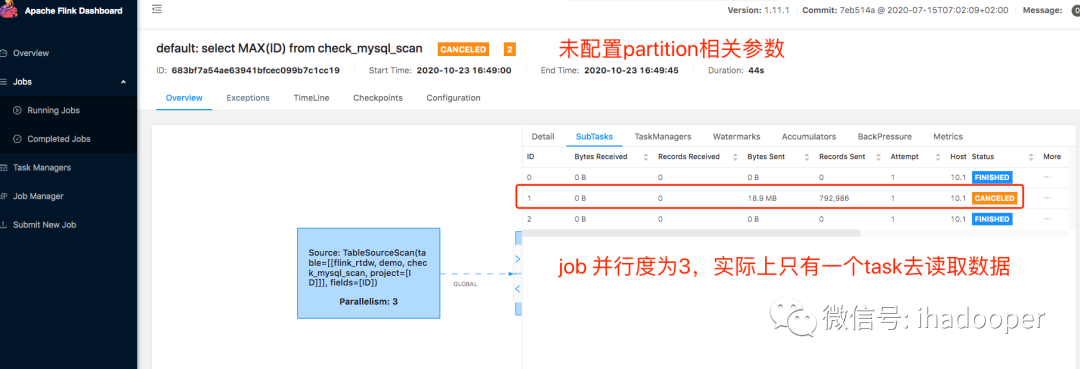
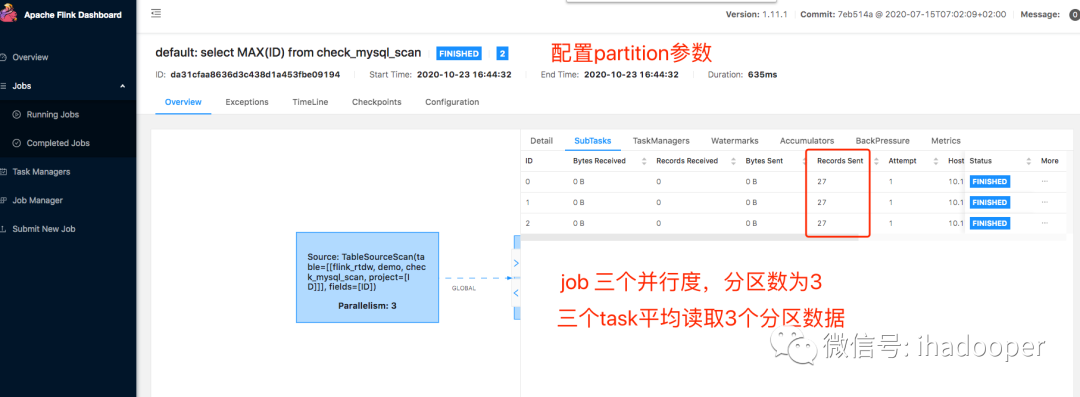
填写这四个参数相当于做了优化方案, 将一个slot上跑的task执行查询任务(就算查询SQL job的并行度大于1,对于sourc算子来说,只有一个slot有用,也就说单个slot上的task扫描全表,当数据量大的时候,task很容易失败,重启也解决不了这个问题)基于上下界和分区个数,形成 多个并行查询,大大提高了效率。对于上述参数,实际上拆成三个查询如下所示:
select * from check_mysql_scan where id between 20 and 46;select * from check_mysql_scan where id between 47 and 73;select * from check_mysql_scan where id between 74 and 100;
如何配置这个4个参数:
scan.partition.column:作为分区的字段名,建议使用在MySQL中定义为索引的字段作为分区
scan.partition.num:分区个数,几个分区对应着几个子查询,一般来说这参数大于1的,那么后续使用该source表的SQL job的并行度最好和这个分区数相等
scan.partition.lower-bound:查询数据范围的下限
scan.partition.upper-bound:查询数据的上限
对于Flink SQL 读取MySQL的说明:
没有添加上述4个分区相关的字段的场景,只有一个slot上的source task去读取MySQL中的数据,不管Job 的并行度是多少,只有一个task去消费,也就是说类比Flink 的soure task 去消费并行度大于分区数的kafka topic,存在task空转的情况, 浪费计算资源
没有添加上述4个分区相关的字段的场景,query SQL就算有where条件,依旧是全表扫描
添加上述4个分区相关的字段的场景,Flink 自身才会基于scan.partition.column的lower-bound和upper-bound生产where条件,从而形成谓词下推,避免全表扫描
03 MySQL作为Flink计算的结果存储
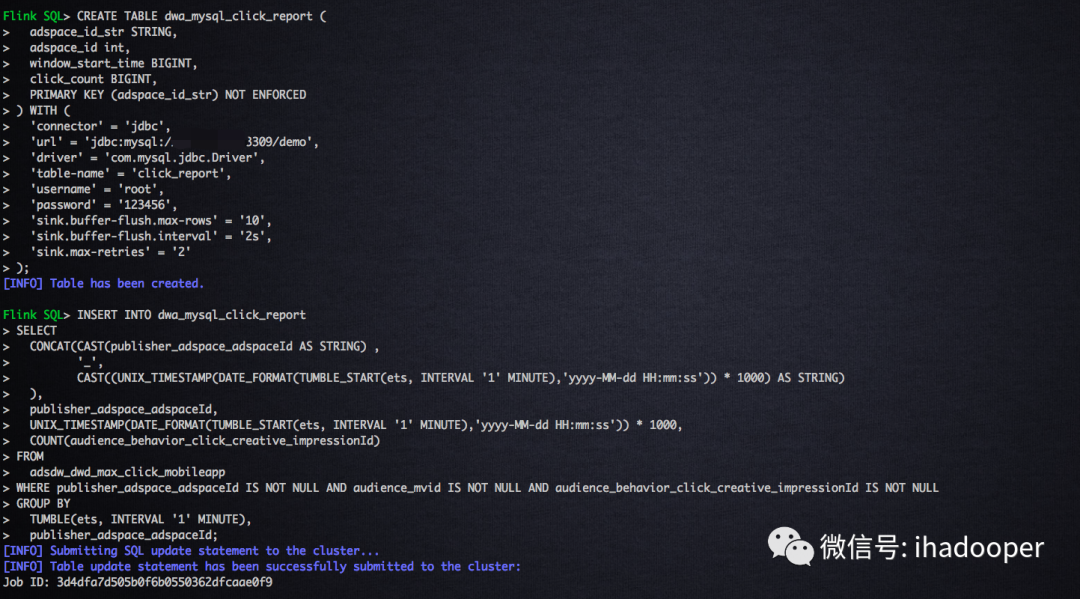
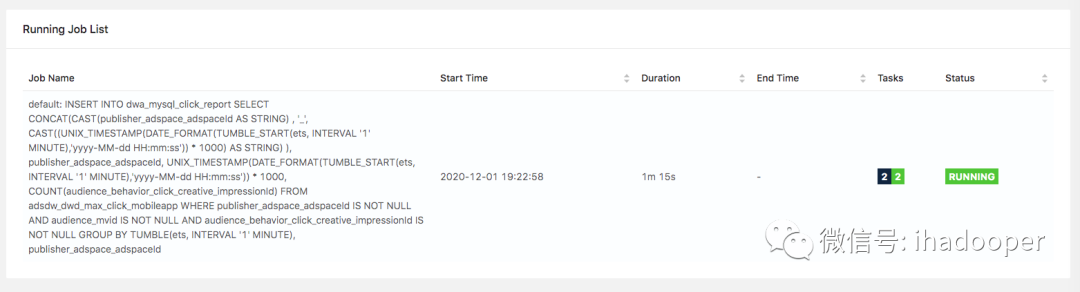
首先,需要在MySQL中创建物理表,作为数据真正存储的地方;然后,需要创建Flink MySQL table,通过Flink SQL提供的JDBC connector连接起来;最后,对点击流做个1分钟的翻转窗口计算分广告位的点击数编写SQL job 逻辑;具体的SQL语句如下所示:
# 创建mysql 物理表CREATE TABLE `click_report` (adspace_id_str varchar(32),adspace_id int,window_start_time BIGINT,click_count bigint(20) DEFAULT NULL,PRIMARY KEY (`adspace_id_str`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;# 注册 Flink MySQL tableCREATE TABLE dwa_mysql_click_report (adspace_id_str STRING,adspace_id int,window_start_time BIGINT,click_count BIGINT,PRIMARY KEY (adspace_id_str) NOT ENFORCED) WITH ('connector' = 'jdbc','url' = 'url','driver' = 'com.mysql.jdbc.Driver','table-name' = 'click_report','username' = 'root','password' = '123456','sink.buffer-flush.max-rows' = '10','sink.buffer-flush.interval' = '2s','sink.max-retries' = '2');# 窗口计算逻辑,写入MySQLINSERT INTO dwa_mysql_click_reportSELECTCONCAT(CAST(publisher_adspace_adspaceId AS STRING) ,'_',CAST((UNIX_TIMESTAMP(DATE_FORMAT(TUMBLE_START(ets, INTERVAL '1' MINUTE),'yyyy-MM-dd HH:mm:ss')) * 1000) AS STRING)),publisher_adspace_adspaceId,UNIX_TIMESTAMP(DATE_FORMAT(TUMBLE_START(ets, INTERVAL '1' MINUTE),'yyyy-MM-dd HH:mm:ss')) * 1000,COUNT(audience_behavior_click_creative_impressionId)FROMadsdw_dwd_max_click_mobileappWHERE publisher_adspace_adspaceId IS NOT NULL AND audience_mvid IS NOT NULL AND audience_behavior_click_creative_impressionId IS NOT NULLGROUP BYTUMBLE(ets, INTERVAL '1' MINUTE),publisher_adspace_adspaceId;
在MySQL中创建物理表以及数据查询验证,在Flink SQL client中创建 Flink MySQL table 以及提交SQL job,以及提交Flink Cluster上的job状态如下所示:
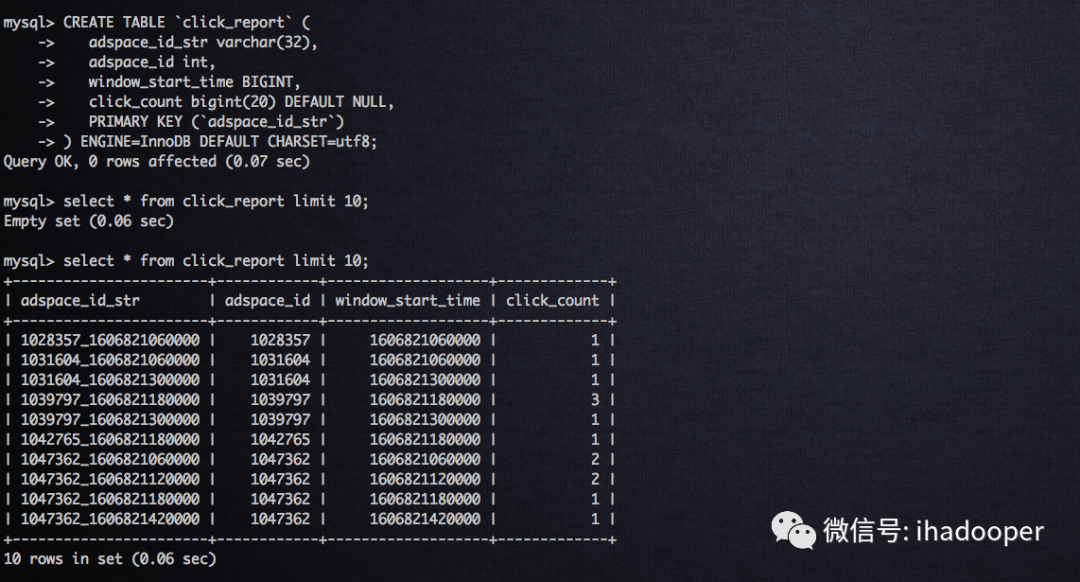
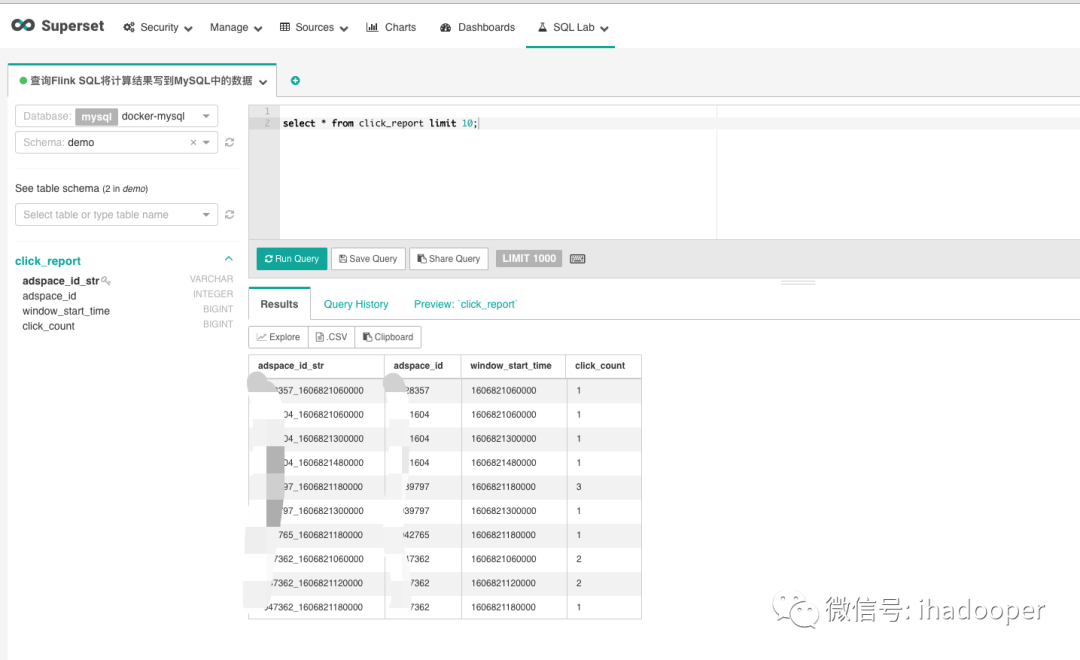
Flink SQL 将计算结果写到MySQL中,后续需要查询或者绘制实时大盘。Airbnb 开源的Superset是优秀的可视化工具代表之一,在我们的生产中Superset已经可视化了MySQL/Hive(Presto + Alluxio来query数据)/druid中的数据,我们可以Superset 的SQL lab查询MySQL中的数据,如下所示:
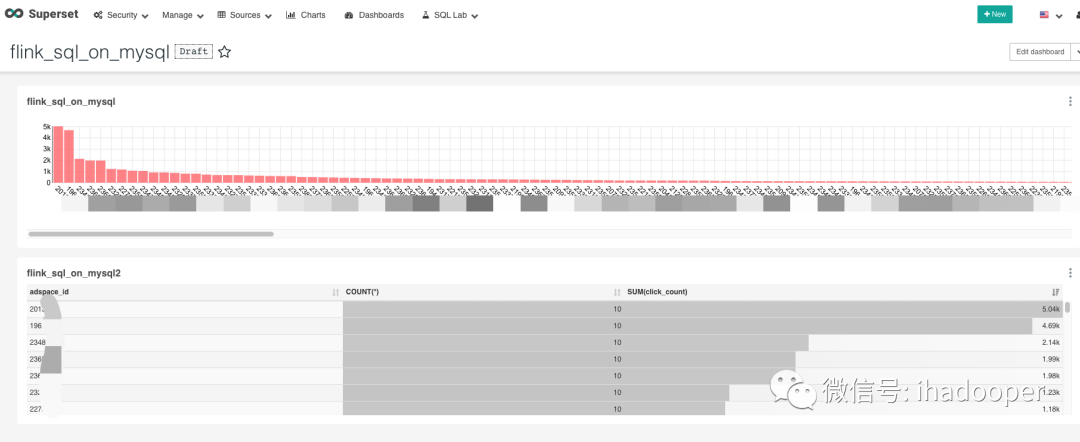
04 TiDB在Flink SQL中的使用
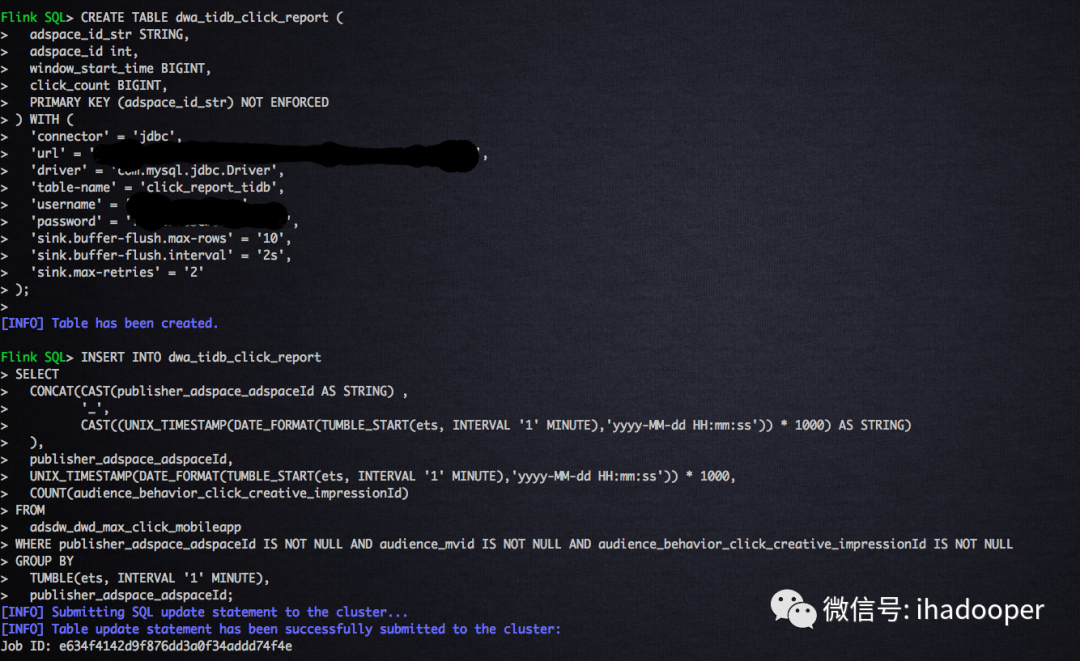
首先,需要在TiDB中创建物理表,作为数据真正存储的地方;然后,需要创建Flink TiDB table,通过Flink SQL提供的JDBC connector连接起来,只有这里JDBC的连接信息与MySQL不一样;最后,对点击流做个1分钟的翻转窗口计算分广告位的点击数编写SQL job 逻辑;具体的SQL语句如下所示:
# 创建TiDB 物理表CREATE TABLE `click_report_tidb` (adspace_id_str varchar(32),adspace_id int,window_start_time BIGINT,click_count bigint(20) DEFAULT NULL,PRIMARY KEY (`adspace_id_str`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;# 注册 Flink TiDB tableCREATE TABLE dwa_tidb_click_report (adspace_id_str STRING,adspace_id int,window_start_time BIGINT,click_count BIGINT,PRIMARY KEY (adspace_id_str) NOT ENFORCED) WITH ('connector' = 'jdbc','url' = 'url','driver' = 'com.mysql.jdbc.Driver','table-name' = 'click_report_tidb','username' = 'username','password' = 'password','sink.buffer-flush.max-rows' = '10','sink.buffer-flush.interval' = '2s','sink.max-retries' = '2');# 窗口计算逻辑,写入TiDBINSERT INTO dwa_tidb_click_reportSELECTCONCAT(CAST(publisher_adspace_adspaceId AS STRING) ,'_',CAST((UNIX_TIMESTAMP(DATE_FORMAT(TUMBLE_START(ets, INTERVAL '1' MINUTE),'yyyy-MM-dd HH:mm:ss')) * 1000) AS STRING)),publisher_adspace_adspaceId,UNIX_TIMESTAMP(DATE_FORMAT(TUMBLE_START(ets, INTERVAL '1' MINUTE),'yyyy-MM-dd HH:mm:ss')) * 1000,COUNT(audience_behavior_click_creative_impressionId)FROMadsdw_dwd_max_click_mobileappWHERE publisher_adspace_adspaceId IS NOT NULL AND audience_mvid IS NOT NULL AND audience_behavior_click_creative_impressionId IS NOT NULLGROUP BYTUMBLE(ets, INTERVAL '1' MINUTE),publisher_adspace_adspaceId;
在TiDB中创建物理表以及数据查询验证,在Flink SQL client中创建 Flink MySQL table 以及提交SQL job,以及提交Flink cluster上的job状态如下所示:
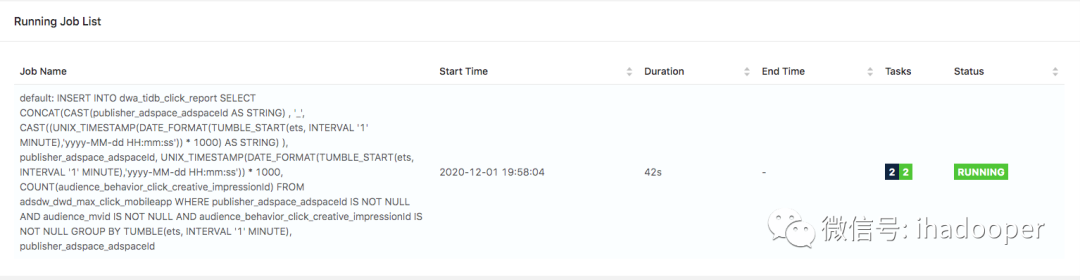
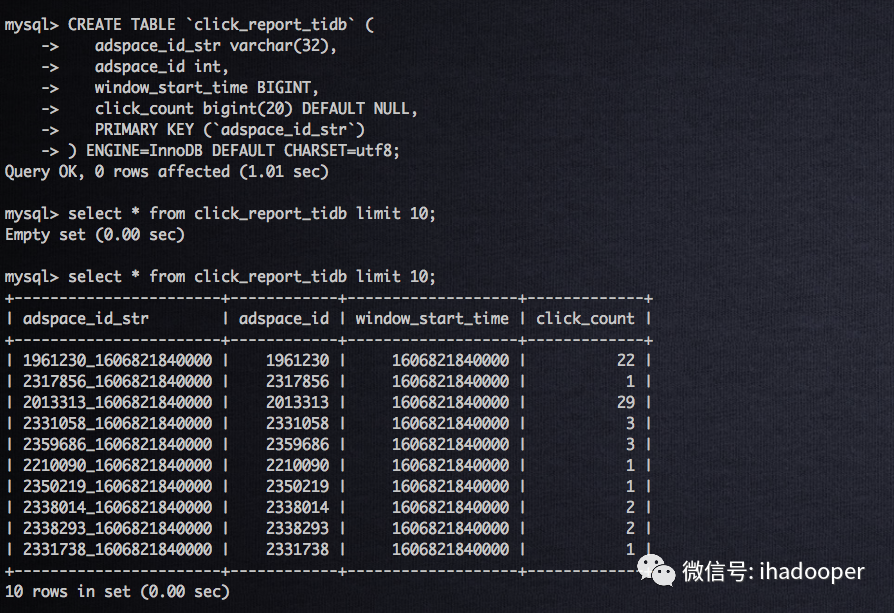
数据可视化同上,依旧使用Superset 查询和dashboard展示,具体效果如下所示:
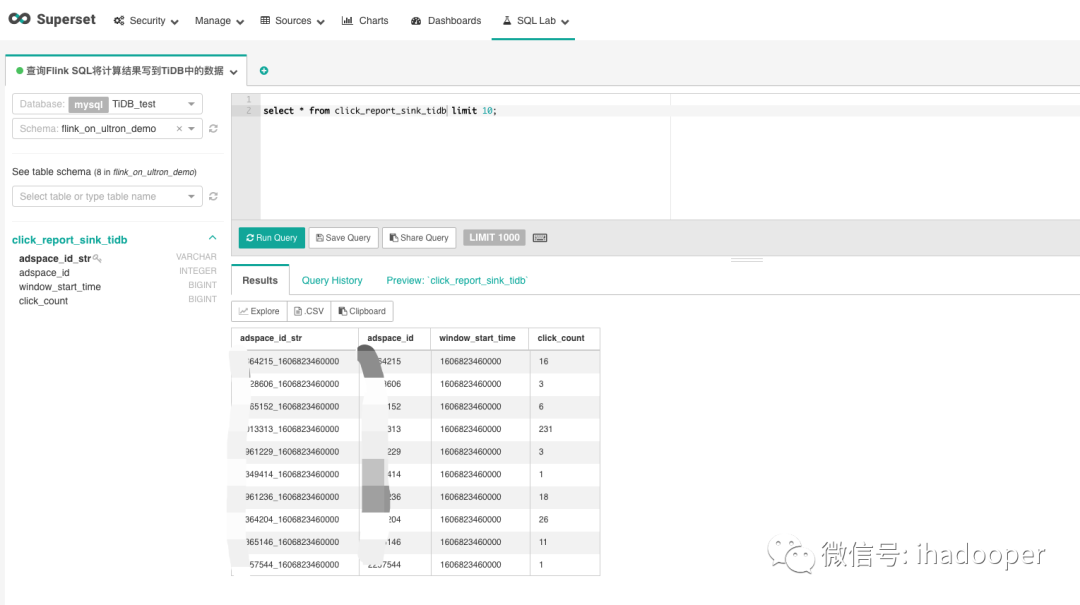
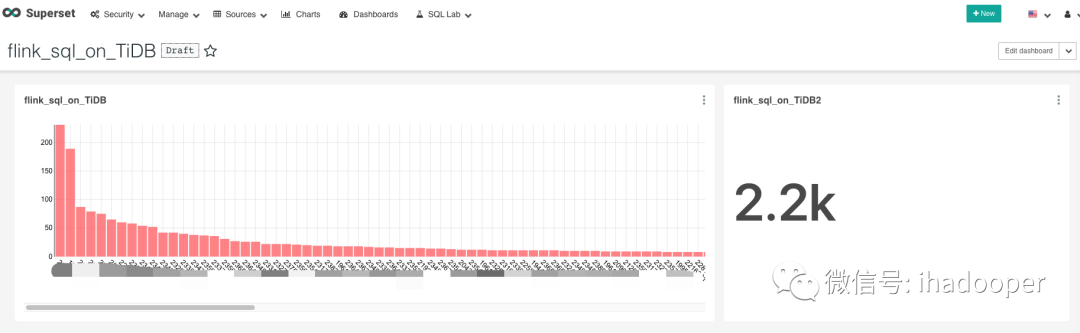
05 CDC在Flink SQL中的使用
首先,我们先建一个MySQL 表,以及注册Flink MySQL table,对MySQL表进行增删改操作,并且在sql-client 实时print 结果;
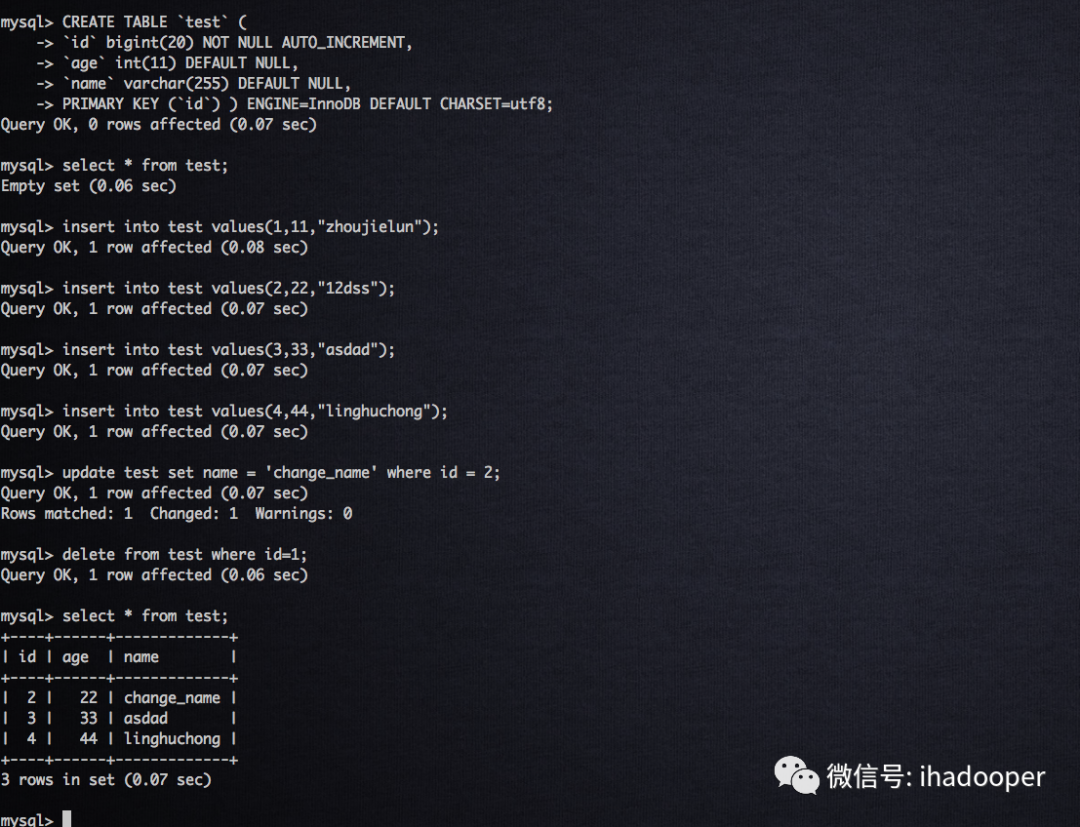
# 创建MySQL tablecreate database demo;use demo;show tables;CREATE TABLE `test` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`age` int(11) DEFAULT NULL,`name` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;select * from test;# 对MySQL表进行增删改操作insert into test values(1,11,"zhoujielun");insert into test values(2,22,"12dss");insert into test values(3,33,"asdad");insert into test values(4,44,"linghuchong");update test set name = 'change_name' where id = 2;delete from test where id=1;#注册Flink MySQL tableCREATE TABLE cdc(id BIGINT,age INT,name STRING) WITH ('connector' = 'mysql-cdc','hostname' = 'hostname','port' = '3309','username' = 'root','password' = '123456','database-name' = 'demo','table-name' = 'test');
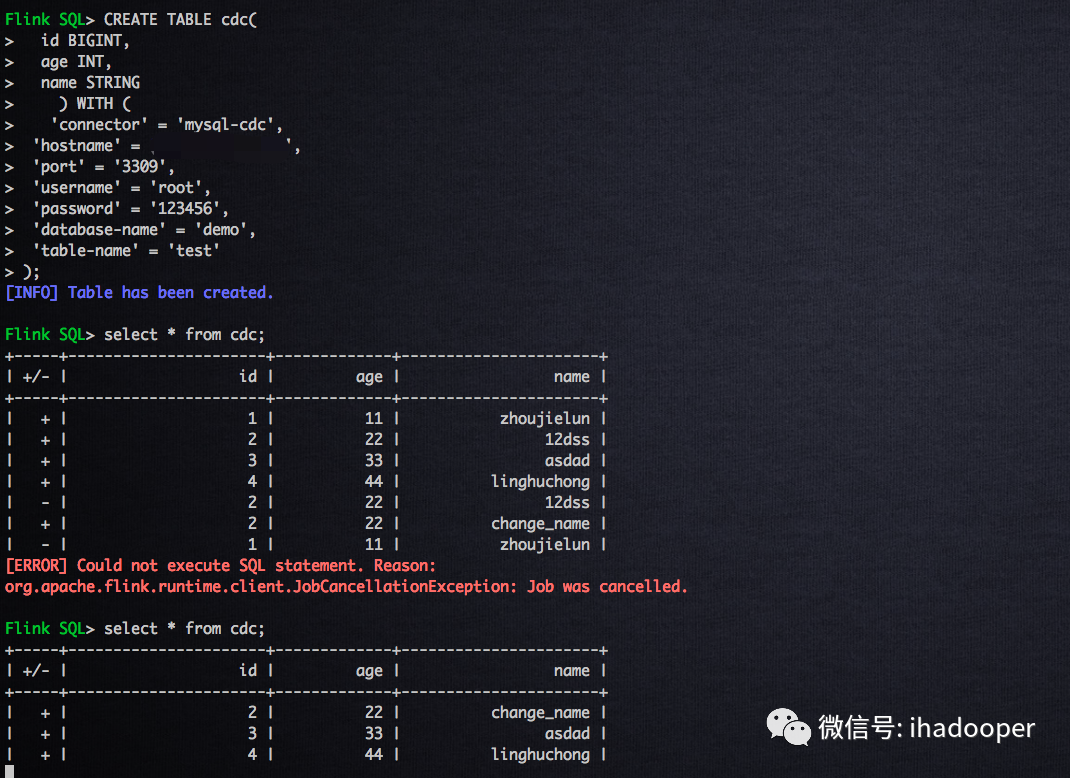
因此,我们只需要注册Flink Kafka table,使用changelog-json format即可,具体的建表语句如下所示:
# 注册Flinl Kafka tableCREATE TABLE flink_rtdw.demo.kafka_changelog_table (id BIGINT,age INT,name STRING) WITH ('connector' = 'kafka','topic' = 'changelog_json_format_topic','properties.bootstrap.servers' = 'broker1:9092,broker2:9092,3:9092','format' = 'changelog-json');# 将changelog 写到kafka中INSERT INTO kafka_changelog_tableselect id, age,namefrom cdc
在sql-client中创建Flink kafka table,以及提交insert job 如下所示:


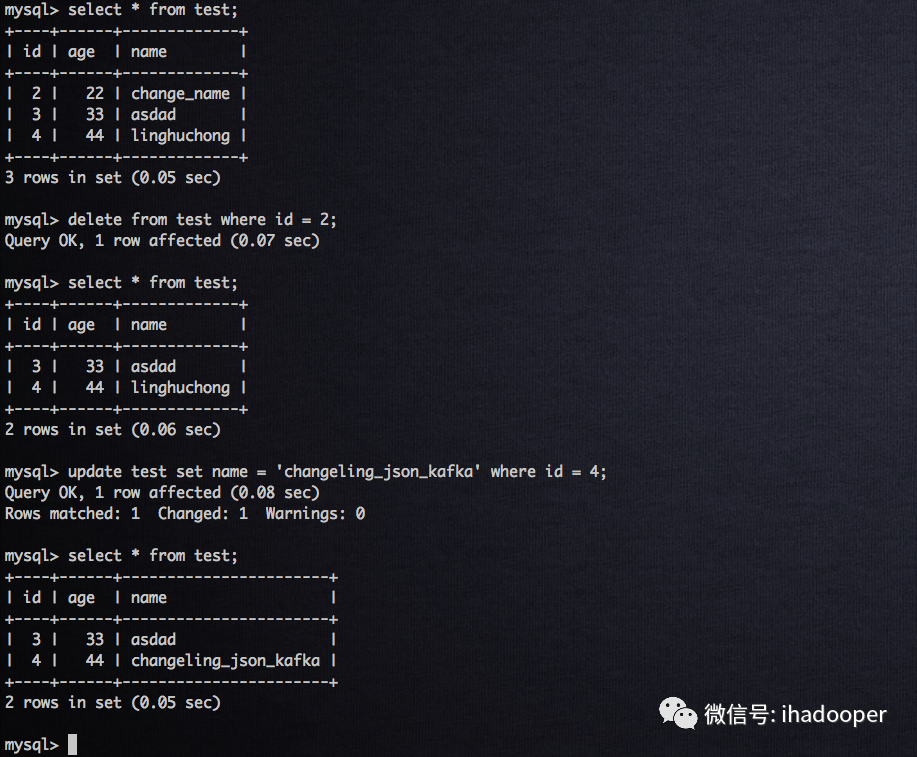
# 在MySQL中执行如下操作delete from test where id = 2;update test set name = 'changeling_json_kafka' where id = 4;
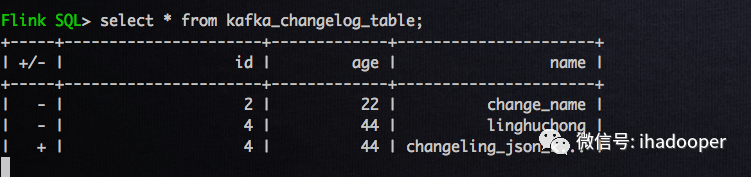
06 总结
参考:
云邪-Flink SQL 1.11 新功能与最佳实践:https://mp.weixin.qq.com/s/v9_epRDUVkhMGlDadkX9OQ
雪尽-Flink JDBC Connector:Flink 与数据库集成最佳实践:https://mp.weixin.qq.com/s/guHl9hnNgD22sBseiGDZ2g
https://github.com/ververica/flink-cdc-connectors/wiki
https://github.com/ververica/flink-cdc-connectors/wiki/Changelog-JSON-Format
云邪-基于 Flink SQL CDC 的实时数据同步方案:https://mp.weixin.qq.com/s/ohasQLwtx4rE79mFgV9fKQ
代晓磊-360 x TiDB|性能提升 10 倍,360 如何轻松抗住双十一流量:https://mp.weixin.qq.com/s/khdRw9IT8RszD2X77_XQIg
