




交替最小二乘(Alternating Least Squares,ALS),是基于矩阵分解的协同过滤算法中的一种,协同过滤算法分为三类:基于相似性的协同过滤包括基于用户和基于产品的协同过滤;基于矩阵分解的协同过滤;基于图的协同过滤。其中ALS算法是基于矩阵分解的协同过滤算法中的一种典型算法,是目前协同过滤推荐的核心算法之一,也是基于spark计算引擎的协同过滤推荐的核心算法。
协同过滤推荐,是在信息过滤和信息系统中一项很受欢迎的技术。与传统的基于内容过滤直接分析内容进行推荐不同,协同过滤分析用户兴趣,在用户群中找到指定用户的相似(兴趣)用户,综合这些相似用户对某一信息的评价,形成系统对该指定用户对此信息的喜好程度预测。
以美国亚马逊(AMAZON)网上书店为例,亚马逊是个性化推荐系统先驱 (基于协同过滤)。亚马逊书店提供先进的个性化推荐功能,能为不同兴趣偏好的用户自动推荐尽量符合其兴趣需要的书籍。亚马逊使用推荐算法对读者曾经购买过的书以及该读者对其他书的评价进行分析后,将向读者推荐他可能喜欢的新书,只要鼠标点一下,就可以买到该书;亚马逊对顾客购买过的东西进行自动分析,然后因人而异的提出合适的建议。读者的搜索信息将被再次保存,这样顾客下次来时就能更容易的买到想要的书。
1.1.1.1 算法介绍
对于R(m×n)的矩阵,ALS旨在找到两个低维矩阵X(m×k)和矩阵Y(n×k),来近似逼近R(m×n),即: ,其中R(m×n)代表用户对商品的评分矩阵,X(m×k)代表用户对隐含特征的偏好矩阵,Y(n×k)表示商品所包含隐含特征的矩阵,T表示矩阵Y的转置。实际中,一般取k<<min(m, n), 也就是相当于降维了。这里的低维矩阵,有的地方也叫低秩矩阵。
,其中R(m×n)代表用户对商品的评分矩阵,X(m×k)代表用户对隐含特征的偏好矩阵,Y(n×k)表示商品所包含隐含特征的矩阵,T表示矩阵Y的转置。实际中,一般取k<<min(m, n), 也就是相当于降维了。这里的低维矩阵,有的地方也叫低秩矩阵。
为了找到使低秩矩阵X和Y尽可能地逼近R,需要最小化下面的平方误差损失函数,得到公式(1):
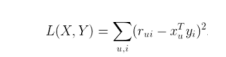
其中xu(1×k)表示示用户u的偏好的隐含特征向量,yi(1×k)表示商品i包含的隐含特征向量, rui表示用户u对商品i的评分, 向量xu和yi的内积xuTyi是用户u对商品i评分的近似。
损失函数一般需要加入正则化项来避免过拟合等问题,我们使用L2正则化,所以上面的公式改造为公式(2):
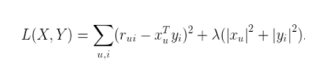
其中λ是正则化项的系数。
到这里,协同过滤就成功转化成了一个优化问题。由于变量xu和yi耦合到一起,这个问题并不好求解,所以我们引入了ALS,也就是说我们可以先固定Y(例如随机初始化X),然后利用公式(2)先求解X,然后固定X,再求解Y,如此交替往复直至收敛,即所谓的交替最小二乘法算法。
演示用例
UP以电影推荐为例。根据用户看过的电影,以及对电影的评分,来为用例推荐其可能感兴趣的没有看过的电影。数据存储在表中,表结构如下:
gbase> desc spark_ml.als_train; +---------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+---------+------+-----+---------+-------+ | user | int(11) | YES | | NULL | | | product | int(11) | YES | | NULL | | | rating | double | YES | | NULL | | +---------+---------+------+-----+---------+-------+ |
数据如下所示:
| 87 | 199 | 5 | | 95 | 31 | 4 | | 437 | 737 | 1 | | 387 | 61 | 3 | | 207 | 179 | 4 | | 42 | 582 | 3 | | 200 | 169 | 5 | | 379 | 701 | 4 | | 61 | 258 | 4 | | 456 | 460 | 3 | +------+---------+--------+ |
用户电影推荐示例如下:
# 创建模型 call upextdb.create_model( 'kmeans_cust_model', 'kmeansForCust', 'spark_ml.t_cust_train_data', 'spark_ml.t_cust_enva_data'); # 设置参数 call upextdb.add_train_setting('als_model','rank','5' ); call upextdb.add_train_setting('als_model','iterator','15' ); call upextdb.add_train_setting('als_model','lambda','0.16' ); # 训练 call upextdb.train_model('als_model'); #评估 call upextdb.evaluate_model('als_model'); # 预测 call upextdb.predict('als_model', 'spark_ml.t_predict', 'spark_ml.t_result'); |
用户要推荐的电影如下:
gbase> select * from t_predict; +------+---------+--------+ | user | product | rating | +------+---------+--------+ | 1 | 1 | 0 | | 1 | 2 | 0 | | 1 | 3 | 0 | | 1 | 4 | 0 | | 1 | 5 | 0 | | 1 | 6 | 0 | | 1 | 7 | 0 | | 1 | 8 | 0 | | 1 | 9 | 0 | | 1 | 10 | 0 | +------+---------+--------+ |
通过机器学习预测后,对其进行评分,选出排名靠前的电影,并剔除用户已经看过的电影,将剩下的推荐给用户,如下图所示:
gbase> select r.user, m.title, r.prediction from t_result r,movie m,user u where r.user = u.userId and r.product = m.movieId order by prediction desc limit 5; +------+-------------------------+------------+ | user | title | prediction | +------+-------------------------+------------+ | 1 | Dead Man Walking (1995) | 4.2432 | | 1 | Twelve Monkeys (1995) | 4.16889 | | 1 | Babe (1995) | 4.13157 | | 1 | Toy Story (1995) | 4.00003 | | 1 | Four Rooms (1995) | 3.6665 | +------+-------------------------+------------+ |
