




点击上方蓝字,关注我哦:)
这是在滴滴云第十期技术沙龙上的分享的部分内容,同步一份到公众号,以备查阅,也是与各位同仁共同探讨,碰撞思维火花:)
运维的使命
在讨论能力之前,先聊聊运维的使命,也就是公司成立一个运维团队的初衷,对运维团队的一个期许。一切都将围绕这点展开。
当然,其实也是老生常谈了,业界对运维的使命有九字真言:安全、稳定、高效、低成本,有些公司会成立单独的安全部门,运维团队配合安全同事即可,滴滴就是这样的,这里,我们主要关注后面三个方面:稳定、高效、低成本。
这三方面,最重点要关注的是稳定,这里的稳定是指线上生产环境的服务稳定性,运维团队,通常是服务稳定性的第一责任人,线上出现问题,第一个冲上去的人,所以运维团队对线上环境,非常熟悉,是线上环境的直接管理人,于是,运维应具备的能力,就呼之欲出了...
运维能力模型
从上文可以看出,运维团队要能管理线上生产环境,要能建设稳定性、成本体系,过程中要能建立平台提升人效,所以总结起来,是如下五点:
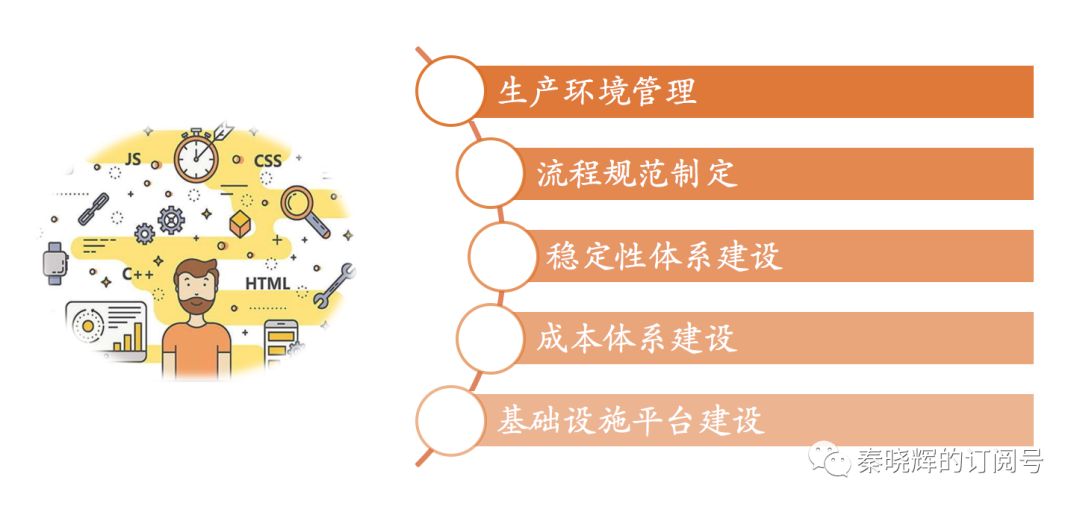
生产环境管理
运维人员作为对生产环境最熟悉的人,具有管理维护的职责,生产环境相关的所有事情都需要运维知悉。
源于此,导致运维成了技术体系的粘合剂,经常与各方沟通,比如我们除了与研发人员沟通,还要经常与基础网络、系统硬件的同事沟通,与安全工程师沟通,与内核同事沟通,与资产管理员沟通。要能沟通,你就得对相关技术领域有了解,所以运维人员常自嘲,我们是半个研发、半个网络、半个系统、半个安全...
源于此,让运维去推进一些横向工作也显得理所当然,比如机房迁移、服务上云、整站交付等... 由运维代表业务来协调各方,整体推进,起到了一个类似项目管理的角色,当然,这个事情也可以由专门的PMO来做,运维从技术上把关整个流程即可。
流程规范制定
要能管理生产环境,那就得为生产环境制定一些标准规范,对生产环境的任何变更,都得遵从一定的流程,要不就乱了...
比如生产环境的操作系统规范、软件安装规范、进程启停规范、日志规范等,服务交由运维来管理维护的准入规范,线上变更操作的灰度制度、通告制度、军规红线等。
运维可谓是最关心稳定性的人,需要主导建立故障发生之后的响应协同机制、止损原则和流程、故障复盘机制、定级定责标准。
另外就是监控、预案、备份、巡检的规范制度和指导原则,如果没有这么一套方法论,新业务接手运维的时候也是无从下手。
最后是设备全生命周期管理的流程,这个一般是应用运维、系统运维、资产管理员共同来搞,简单但很重要,梳理不好,遗留在犄角旮旯的设备就会越来越多,浪费大量成本。
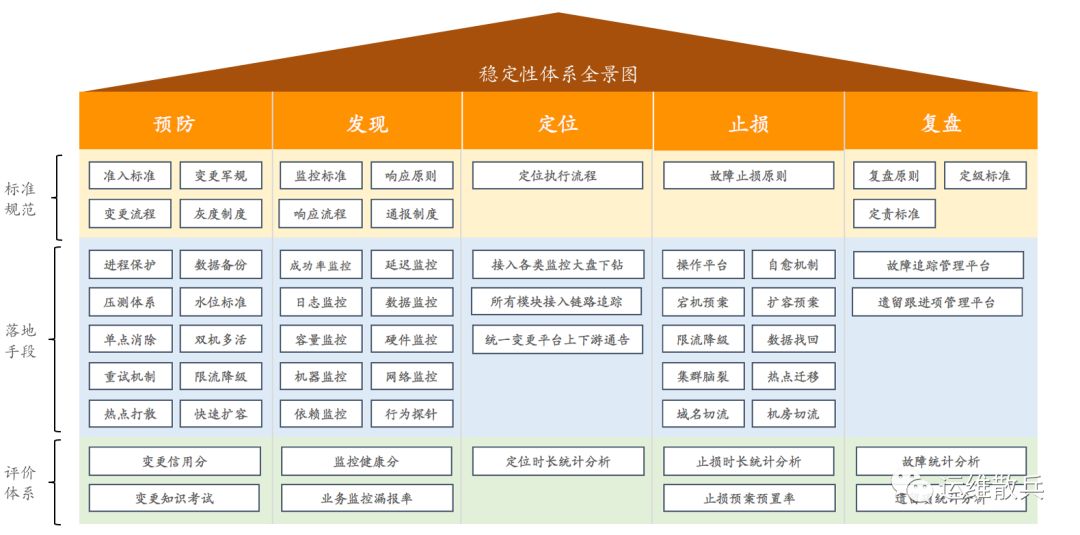
稳定性体系建设
从故障全生命周期预防、发现、定位、止损、复盘五个环节着手,优化每个环节;减少故障,降低止损时间,也就意味着提升稳定性。
从达成目标的通用做事方法上来说,要建好稳定性体系,需要先制定好稳定性体系的标准规范,梳理落地手段,最后建立评价体系,来量化稳定性建设的成果。
另外最重要的,稳定性是个横向工作,需要各方支持,所以需要运维的老板去搞定各方向决策链上的人,让大家都支持配合你。
下面是散兵总结的一个稳定性体系的全景图,供参考,转载请注明出处:)
成本体系建设
成本体系主要分五个方面:设备成本、带宽成本、机柜成本、人力成本、电力成本,电力成本这个主要跟IDC建设相关,非运维人员关注的重点,其实机柜这个也是主要由系统部操心,业务运维会关注少一些,直接放一张之前总结的PPT:

基础设施平台建设
基础设施平台,很多公司会成立基础架构部,与运维部的职责会有部分小重叠,如何分工呢,一般运维部会负责涉及稳定性的平台,比如:风险量化系统、监控告警系统、故障定位平台、预案管理平台、故障管理平台等;还有就是涉及生产环境管理的平台,比如:机器初始化平台、服务发布变更平台、配置管理平台、数据分发变更平台、接入层平台;对于其他平台,比如容器管理平台、日志中心,架构部干也可以,运维部干也可以,看人力吧,两个老板商量着来~
好了,总结到这里,干运维的,如果只是帮业务上线、配置一下nginx、安装个xx软件,那就没意思了,散兵整理的这5个方向是个人的一个理解,欢迎探讨:)

