




转自本文知乎文章:https://zhuanlan.zhihu.com/p/631115188
本文将陆续完成对【PolarDB Serverless: A Cloud Native Database for Disaggregated Data Centers】这篇论文的学习
polarDB基于mysql
术语表
- PAT:page address table,记录每个也地址(slab node id and physical memory address)与引用的hash table
- PIB:page invalidation bitmap,一个记录PAT中每个page的page invalidation的bitmap,0表示页面没有修改,1表示页面在本地缓存有修改但没有同步到共享内存
- PRD:page reference directory,一个映射表,记录PAT中每个页面被RO节点引用的RO节点列表
- PLT:page latch table,PAT中每一个条目对应一个page latch, PLT管理这些page latch(PL), PL是全局物理锁,保护不同数据库节点对page的读写与同步,特别是对b+树一致性保护。
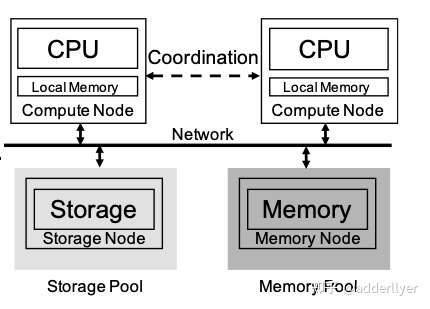
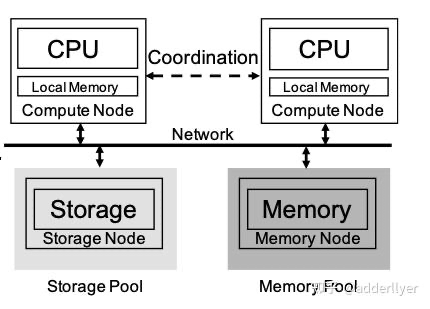
CPU/Memory/Storage解耦架构
log is data(page materialization offloading)
这个实现与华为的Taurus非常类似,Taurus中page chunk副本间采用的是quarum协议,而polarDB应该是采用了raft协议
论文中说是采用了microsoft的socrates,但与Taurus是实现基本一致,没有看过socrates,后续学习一下,也许Taurus也是借鉴了socrates
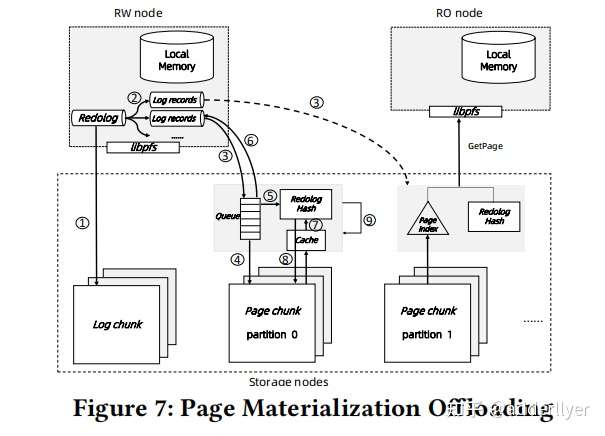
log落盘,buffer cache包括local buffer/remote buffer中的页面不落盘。因此remote buffer的page,包括脏页都是可以被淘汰的。
remote memory pool不与storage pool直接接交互,也就是说,memory pool不从storage pool读页面数据,页不向storage pool写页面数据
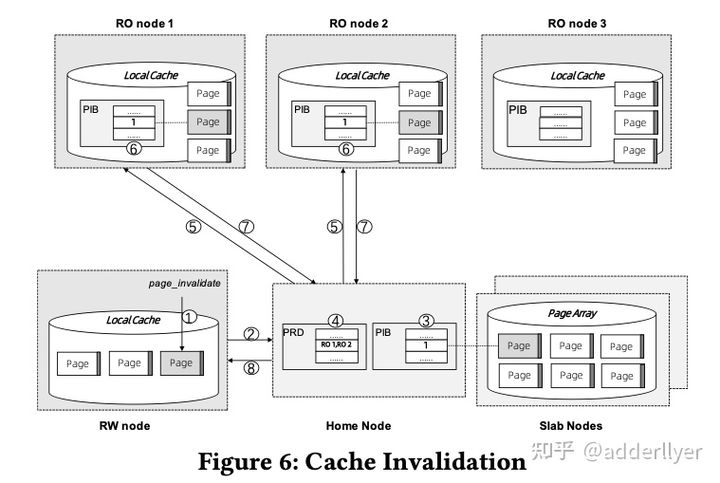
cache invalidation流程如下图:
MTR修改的Dirty page在MTR事务提交前,需要完成page invalidation操作。
- 调用page_invalidate接口设置Home Node上PIB(page invalidation bit)位。
- 通过PRD获取引用该page的RO节点
- 修改RO节点本地PIB
- 等待步骤3中所有节点完成(同步操作)
- 返回成功,
- 如果有RO节点超时,集群会将RO节点提出集群,确保page_invalidation成功
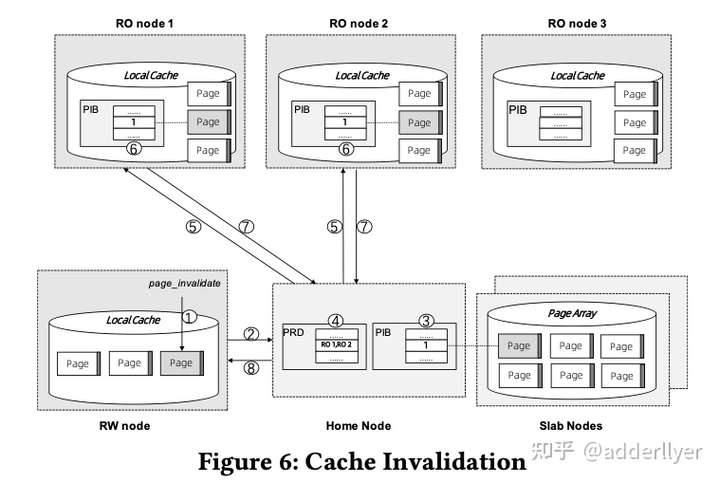
问题:page在RW几点修改后,MRT提交,page在remote memory pool中失效,那么,什么时候会把修改后的页面传到remote memory pool中呢?
B+Tree’s Structural Consistency
RO节点会对涉及到的页面加S锁
RW几点insert/delete,PL + 两步法:
- 乐观遍历树,也就是认为该次操作不会涉及到SMO(structure modification operation)
- 如果涉及到SMO,那么从root节点开始,将SMO中涉及到的页面加X锁
SI(snapshot Isolation)
RW节点维护一个CTS(centralized timestamp)
一个读写事务需要获取两个时间戳:
- 事务开始cts_read
- 事务提交cts_commit, 它和被事务修改的records一起被记录,所有的records与undo records保留一列来存储cts_commit值。
每个版本的record会存储trx_id
一个事务内的read操作返回满足如下条件的最新版本records,它们的cts_commit<当前事务的cts_read
问题:大事务会修改大量的records,cts_commit不能被立即更新到所有行,并且这些records是随机分布的,因此事务提交会触发大量的随机写操作,对这个问题,polarDB serverless是如何解决的呢?
主要有采用两个技术:
- 一个CTS Log的数据结构:RW节点上的一个环形数组
- one-side RDMA,不增加CPU负荷降低网络时延
CTS Log记录了固定数量的最新已提交的事务的cts_commit时间戳,事务未提交,其修改的records和undo records对应的cts_commit时间戳为null。当任何一个database node读到records和undo records其cts_commit值为null时,去RW节点的CTS Log数据结构中查找是否该事务已提交,从而判读其对当前事务的可见性。
这里CTS Log这个环形数组大小的设置需要一些技巧,太小可能出现已提交事务相关records和undo records还没有被更新,而该cts_commit时间戳已被覆盖,或者环形数组太大导致数据查找效率与内存浪费。
自动扩缩容
性能优化
Optimistic Locking
Index-Awared Prefetching
BKP(Batch Key Prepare):
论文中没有详细介绍BKP是怎么实现的,只是简单的一句话带过:BKP是在存储引擎中实现,通过一个带keys集合的接口想SQL引擎开放,调用接口时,存储引擎会其一个后台任务完成这些key相关的page的预取。
PolarDB serverless采用的log is Data,SQL引擎只写log日志,存储引擎中的page页面是通过日志回放生成的。因此在读取页面时,可能要该页面还没有最新版本,还需要通过一系列的回放动作才能生成需要的页面,这个效率是很低的,因此,对需要读取大量页面的操作,比如全表扫描等是非常慢的,甚至慢到不可接受。论文中只没有详细介绍这个后台任务是怎么做预取的,因此无法知道真正的效果如何?
可靠性与失败恢复
polarDB的解耦架构,可以做到每层独立恢复本文将陆续完成对【PolarDB Serverless: A Cloud Native Database for Disaggregated Data Centers】这篇论文的学习
polarDB基于mysql
术语表
- PAT:page address table,记录每个也地址(slab node id and physical memory address)与引用的hash table
- PIB:page invalidation bitmap,一个记录PAT中每个page的page invalidation的bitmap,0表示页面没有修改,1表示页面在本地缓存有修改但没有同步到共享内存
- PRD:page reference directory,一个映射表,记录PAT中每个页面被RO节点引用的RO节点列表
- PLT:page latch table,PAT中每一个条目对应一个page latch, PLT管理这些page latch(PL), PL是全局物理锁,保护不同数据库节点对page的读写与同步,特别是对b+树一致性保护。
CPU/Memory/Storage解耦架构
log is data(page materialization offloading)
这个实现与华为的Taurus非常类似,Taurus中page chunk副本间采用的是quarum协议,而polarDB应该是采用了raft协议
论文中说是采用了microsoft的socrates,但与Taurus是实现基本一致,没有看过socrates,后续学习一下,也许Taurus也是借鉴了socrates
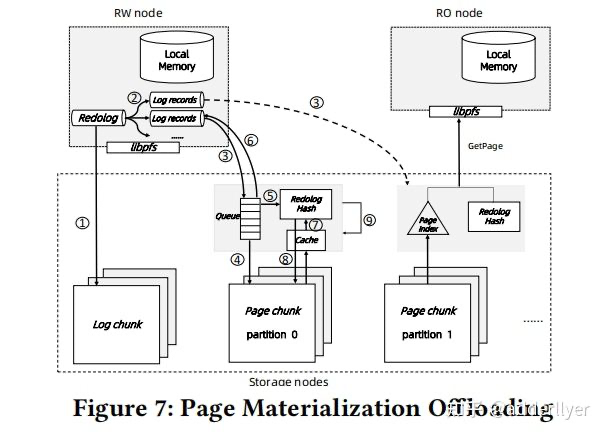
log落盘,buffer cache包括local buffer/remote buffer中的页面不落盘。因此remote buffer的page,包括脏页都是可以被淘汰的。
remote memory pool不与storage pool直接接交互,也就是说,memory pool不从storage pool读页面数据,页不向storage pool写页面数据
cache invalidation流程如下图:
MTR修改的Dirty page在MTR事务提交前,需要完成page invalidation操作。
- 调用page_invalidate接口设置Home Node上PIB(page invalidation bit)位。
- 通过PRD获取引用该page的RO节点
- 修改RO节点本地PIB
- 等待步骤3中所有节点完成(同步操作)
- 返回成功,
- 如果有RO节点超时,集群会将RO节点提出集群,确保page_invalidation成功
问题:page在RW几点修改后,MRT提交,page在remote memory pool中失效,那么,什么时候会把修改后的页面传到remote memory pool中呢?
B+Tree’s Structural Consistency
RO节点会对涉及到的页面加S锁
RW几点insert/delete,PL + 两步法:
- 乐观遍历树,也就是认为该次操作不会涉及到SMO(structure modification operation)
- 如果涉及到SMO,那么从root节点开始,将SMO中涉及到的页面加X锁
SI(snapshot Isolation)
RW节点维护一个CTS(centralized timestamp)
一个读写事务需要获取两个时间戳:
- 事务开始cts_read
- 事务提交cts_commit, 它和被事务修改的records一起被记录,所有的records与undo records保留一列来存储cts_commit值。
每个版本的record会存储trx_id
一个事务内的read操作返回满足如下条件的最新版本records,它们的cts_commit<当前事务的cts_read
问题:大事务会修改大量的records,cts_commit不能被立即更新到所有行,并且这些records是随机分布的,因此事务提交会触发大量的随机写操作,对这个问题,polarDB serverless是如何解决的呢?
主要有采用两个技术:
- 一个CTS Log的数据结构:RW节点上的一个环形数组
- one-side RDMA,不增加CPU负荷降低网络时延
CTS Log记录了固定数量的最新已提交的事务的cts_commit时间戳,事务未提交,其修改的records和undo records对应的cts_commit时间戳为null。当任何一个database node读到records和undo records其cts_commit值为null时,去RW节点的CTS Log数据结构中查找是否该事务已提交,从而判读其对当前事务的可见性。
这里CTS Log这个环形数组大小的设置需要一些技巧,太小可能出现已提交事务相关records和undo records还没有被更新,而该cts_commit时间戳已被覆盖,或者环形数组太大导致数据查找效率与内存浪费。
自动扩缩容
性能优化
Optimistic Locking
Index-Awared Prefetching
BKP(Batch Key Prepare):
论文中没有详细介绍BKP是怎么实现的,只是简单的一句话带过:BKP是在存储引擎中实现,通过一个带keys集合的接口想SQL引擎开放,调用接口时,存储引擎会其一个后台任务完成这些key相关的page的预取。
PolarDB serverless采用的log is Data,SQL引擎只写log日志,存储引擎中的page页面是通过日志回放生成的。因此在读取页面时,可能要该页面还没有最新版本,还需要通过一系列的回放动作才能生成需要的页面,这个效率是很低的,因此,对需要读取大量页面的操作,比如全表扫描等是非常慢的,甚至慢到不可接受。论文中只没有详细介绍这个后台任务是怎么做预取的,因此无法知道真正的效果如何?
可靠性与失败恢复
polarDB的解耦架构,可以做到每层独立恢复
