




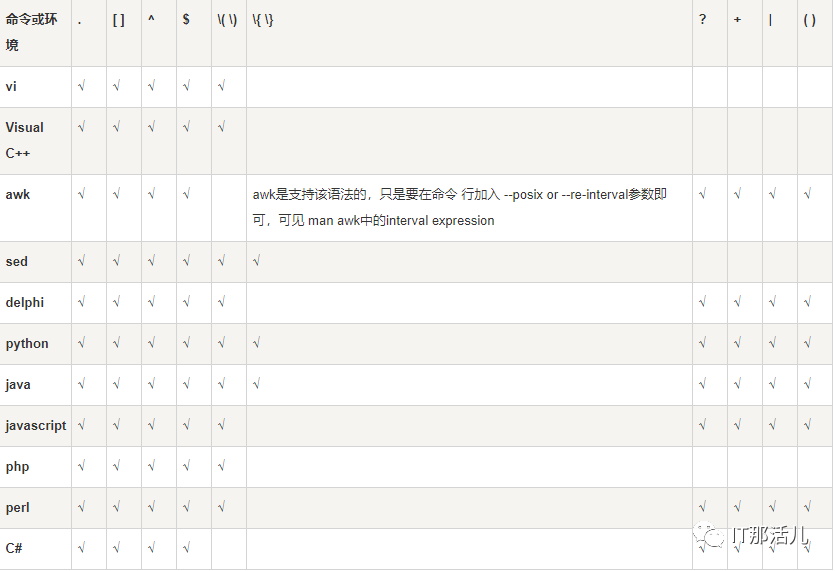
1. 常用的元字符
. 匹配除换行符以外的任意一个字符 ^ 匹配字符串的开始位置$ 匹配字符串的结束位置\w 匹配字母和数字以及下划线其中的一个字符,相当于[_a-zA-Z0-9]\W 匹配不是字母、数字、下划线的字符,即\w的补集\d 匹配任意一个数字,相当于[0-9]\D 匹配任意非数字的字符,\d的补集\b 匹配单词的开头或结尾位置,用于精确匹配 \bevening\b Good evening leveningll 仅匹配是evening的完整单词\B 匹配不是单词开头或结束的位置\Bveni\B Good evening veni 仅匹配单词内部含veni的字符串\s 匹配空格符号 \S 匹配非空格符号
2. 常用量词
常用量词主要是对前面的字符的匹配次数
* 代表连续匹配前边的内容任意次(换行符除外) + 和*类似,不同的是*可以匹配0次,而+则是匹配至少1次? 匹配0次或1次{n} 匹配前面的字符n次 {n,} 匹配前面的字符至少n次{n,m} 匹配前面的字符n次到m次
3. 字符集合
[xyz] 匹配x或y或z[a-zA-Z0-9] 匹配a-z或A-Z或0-9中任意一个字符[^a-z] 匹配非a-z的任意字符,达到了取反的效果
4. 其他的特殊字符
() 以组的形式将多个字符作为一个整体。
如(abc){2,} 表示至少是abcabc。在一个表达式中使用多个()定义组,则使用\1,\2的形式来调用的定义的组。
5. 贪婪匹配和惰性匹配
6. 断言匹配
7. PCRE规范与Linux中工具使用规范的不同
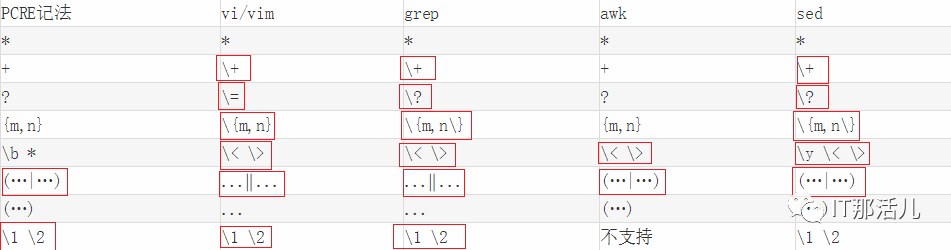
vi/vim,grep,sed等工具遵循的是POSIX的基本语法规范,awk和egrep遵循的是POSIX扩展语法规范。因此,这是有的对{}进行转义,有的不需要转义的原因。
PCRE中常用\b来表示“单词的起始或结束位置”,但Linux/Unix的工具中,通常用\<来匹配“单词的起始位置”,用\>来匹配“单词的结束位置”,sed中的\y可以同时匹配这两个位置。
不同规范中分枝匹配也有一定差别,有的用...|...,而有的用(...|...)。
使用()可以定义作用范围,当在一个规则中使用多个括号时,可以使用\1 \2来调用前面括号的内容。
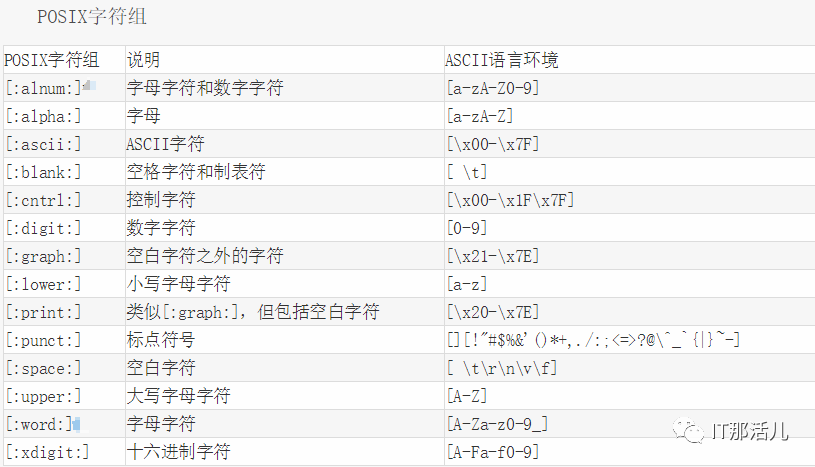
8. POSIX字符组
9. 正则表达式举例
((ht|f)tps?) 匹配http,https,ftp三种格式(www\.)? ?代表可以匹配0次或者1次www.\w.* 表示可以输入任意内容(换行符除外)(\.(com|cn|io|html|htm|))$ 可以匹配com、cn、io、html等结尾的网址
因此以下形式的网址均可以被匹配:
在编译安装nginx前,需要安装PCRE依赖包,nginx中的正则是遵循PCRE规范。
1. 正则匹配在location模块中的使用
2. 正则匹配在中if模块中的应用
▼▼▼if ($http_user_agent ~* (mobile|nokia|iphone|ipad|android|samsung|htc|blackberry)) { return 403; }----------------------------------------------、
3. 正则匹配基于域名的应用
▼▼▼server{ listen 80; server_name ~ ^(www\.)?(.+)$; index index.php index.html; root data/wwwsite/$2; }
#此处需要说明的一点是在nginx中$2是对前面括号内容的的引用,引用的是(.+),使用该正则可以用一个规则表达式区分不同域名对应的家目录。

更多精彩干货分享
点击下方名片关注
IT那活儿

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
