什么是 Apache Paimon
ORC、Parquet、Avro文件格式,支持各大主流计算引擎,包括
Flink、Doris、Spark、Hive、Trino、Presto什么是 Apache Doris
Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。基于此,Apache Doris 能够较好的满足报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等使用场景,用户可以在此之上构建用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
目前限制:
目前只支持Hive服务作为Paimon的Catalog。
目前只支持简单字段类型
目前仅支持 Hive Metastore 类型的 Catalog。所以使用方式和 Hive Catalog 基本一致。后续版本将支持其他类型的 Catalog
环境准备
Hadoop 2.8.5,
Flink 1.14,
Hive 2.3.9,
Paimon 0.4-SNAPSHOT
Doris master 分支版本:https://jiafeng-beijing-1308700295.cos.ap-beijing.myqcloud.com/2.0.0/apache-doris-for-paimon.tar.gz
Flink 导入数据
1.1 在 $FLINK_HOME/lib 中放置需要依赖的 jar 包
paimon-flink-1.14-0.4-SNAPSHOT.jar
hive-exec-3.1.3.jar
hadoop-client-2.8.5.jar
flink-connector-hive_2.12-1.14.2.jar
1.2 配置 flink conf, 启动 flink
vim $FLINK_HOME/conf/flink-conf.yaml
# 修改 taskmanager.numberOfTaskSlots
taskmanager.numberOfTaskSlots: 2
sh $FLINK_HOME/bin/start-cluster.sh
sh $FLINK_HOME/bin/sql-client.sh
1.3 创建 catalog, table, 导入数据
CREATE CATALOG my_hive WITH (
'type' = 'paimon',
'metastore' = 'hive',
'uri' = 'thrift://172.16.65.16:7004',
'warehouse' = 'hdfs:///data/paimon1'
);
use catalog my_hive;
create database paimon;
use paimon;
CREATE TABLE test_table (
a int,
b string
);
INSERT INTO test_table VALUES (7, 'Hugo'), (8, 'Stop');
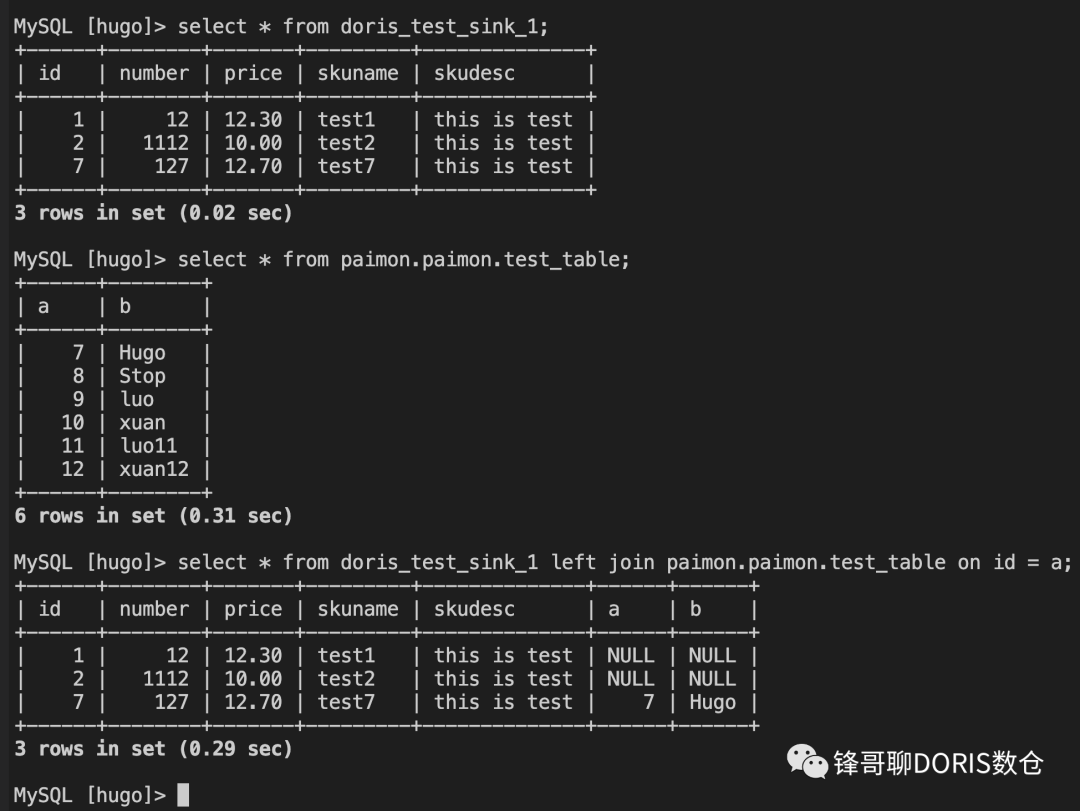
Doris 查询 Paimon
2.1 创建 paimon catalog
CREATE CATALOG `paimon` PROPERTIES (
"dfs.ha.namenodes.HDFS1006531" = "nn2,nn1",
"dfs.namenode.rpc-address.HDFS1006531.nn2" = "172.16.65.112:4007",
"dfs.namenode.rpc-address.HDFS1006531.nn1" = "172.16.65.16:4007",
"hive.metastore.uris" = "thrift://172.16.65.16:7004",
"type" = "paimon",
"dfs.nameservices" = "HDFS1006531",
"hadoop.username" = "hadoop",
"paimon.catalog.type" = "hms",
"warehouse" = "hdfs://HDFS1006531/data/paimon1",
"dfs.client.failover.proxy.provider.HDFS1006531" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
);
2.2 在 Doris 上查询 Paimon 数据