




墨尘
华为云数仓技术专家
读完需要
速读仅需 10 分钟
监控系统是智能化管理和自动化运维的基石,可以为资源规划,故障排查,性能优化提供至关重要的数据支持。GaussDB(DWS)作为企业级数仓,为用户提供了一整套覆盖实例级、用户级、作业级的资源监控能力,其中,作业级监控(下文统称为TopSQL)主要是对运行作业的监控,包括了实时运行作业的相关信息,历史运行作业的相关信息等。它收集的数据来源于数据库内部,为用户提供了实时监控数据库的能力。
目前TopSQL功能被用户广泛使用,是性能定位、劣化分析、审计回溯等重要的基石,为用户提供覆盖内存、耗时、IO、网络、空间等多方面的监控能力。
本文以数仓813版本作为基线,对TopSQL进行介绍。

对于用户而言,数据库是个黑盒,输入SQL语句,输出预期结果。在此过程中,用户关心两点:
输出结果是否符合预期;
语句要多久跑完。
关于第一个问题,用户需要关注下SQL语句写的是否合理。而对于第二个问题,普通用户可以通过explain等手段分析作业的执行计划,然而企业用户的SQL作业耗时久,影响较大,重跑代价较高,无法额外通过explain performance等手段进行分析,此时TopSQL可以帮助用户打开数据库黑盒,查看作业执行的实时情况和历史情况,便于用户分析数据库的情况。
TopSQL功能主要通过视图进行承载,如下表所示,本文以query级别的视图为例进行说明。
| 级别 | 类别 | 查询数据范围 | 视图名称 |
|---|---|---|---|
| query/perf级别 | 实时 | 单CN | GS_WLM_SESSION_STATISTICS |
| 所有CN | PGXC_WLM_SESSION_STATISTICS | ||
| 历史 | 单CN | GS_WLM_SESSION_ INFO | |
| 所有CN | PGXC_WLM_SESSION_ INFO |
ENABLE_RESOURCE_TRACK (ON)
是否开启监控功能,实时TopSQL的总开关,关闭之后实时TopSQL将不再进行记录,更不会在历史TopSQL中出现。
RESOURCE_TRACK_COST(0)
在设置对当前会话的语句进行资源监控的最小执行代价。
RESOURCE_TRACK_LEVEL(QUERY)
设置当前会话的资源监控的等级,默认为query级别。
RESOURCE_TRACK_DURATION(60S)
设置实时TopSQL中记录的语句执行结束后进行历史信息转存的最小执行时间,该时间记录值的判断是包含了排队时间和运行时间,当排队时间+运行时间 > RESOURCE_TRACK_DURATION时,TopSQL历史视图会记录作业信息。当执行完成的作业,其执行时间不小于此参数值时,作业信息会从实时视图(以STATISTICS为后缀的视图)转存到相应的历史视图。
ENABLE_RESOURCE_RECORD(ON)
设置是否开启资源监控记录归档功能。开启时,对于执行结束的记录,会分别被归档到相应的INFO视图,CN和DN都需要设置上。
TOPSQL_RETENTION_TIME(30)
设置历史TopSQL中GS_WLM_SESSION_INFO和GS_WLM_OPERATOR_INFO表中数据的保存时间,单位为天。
参数正确设置后,TopSQL会记录用户的SQL语句执行过程中的相关信息,用户可以使用TopSQL的视图筛选出执行时间较长的作业,专注于慢SQL的分析。
TopSQL功能分为实时TopSQL和历史TopSQL,以query级别为例,当需要查看正在运行的作业时,用户可查看实时TopSQL视图GS_WLM_SESSION_STATISTICS和PGXC_WLM_SESSION_STATISTICS,若需要对已经执行完成的作业进行分析,可查询历史TopSQL视图GS_WLM_SESSION_ HISTORY和PGXC_WLM_SESSION_ HISTORY。其中GS_开头的可以查询当前CN节点上正在执行的作业信息,PGXC_开头的可查询所有CN节点上正在执行的作业信息。
实时TopSQL视图为用户记录了作业运行时的相关信息,比如作业下发来源、阻塞时间、执行时长、开始时间、内存消耗、作业下盘量、作业IO、网络、语句类型、语句的执行计划等信息。用户可先通过resource_pool、nodename、username、query等信息定位到自己需要分析的语句,再通过作业运行信息定位问题。又或者用户可通过对查询进行筛选,筛选出当前占用资源较多的作业。
历史TopSQL视图记录了作业运行结束时的资源使用情况(包括内存、下盘、CPU时间等)和运行状态信息(包括报错、终止、异常等)以及性能告警信息。用户可通过对历史语句运行数据的分析,筛选出执行时长较大的语句,看语句执行计划是否有优化的空间,是否需要对表做一些analyze或者vacuum之类的操作。又比如对于内存报错的情况,可分析内存占用高的语句是否合理,从执行计划上分析是否有优化空间。
文末附TopSQL实践:常见问题现象及对应原因。

2.1 TopSQL原理简介:
TopSQL的数据来源于数据库内核,当语句执行时,TopSQL会实时记录语句执行的相关信息。实时TopSQL数据会保存在内存的临时表中,当语句执行结束后,数据会转存到对应实体表GS_WLM_SESSION_INFO中,在实际使用中,由于下发作业繁多,历史TopSQL记录的作业数也不断增长,这样会导致INFO表中的数据量逐渐庞大,为了确保数仓整体性能不受影响,支持通过TOPSQL_RETENTION_TIME来设置INFO表中数据的保存时间(单位为天)。当数据存留时长超过这个时限,会对实体表GS_WLM_SESSION_INFO进行数据老化删除处理。

▲图1 TopSQL数据流通图
如图1所示,各项GUC参数决定了TopSQL生成的记录信息,具体的参数说明详见第2节使用TopSQL前的检验。
2.2 性能分析:
对于企业用户而言,性能问题是Top级问题,对于TopSQL功能,我们进行了性能压测,在4TB的场景下,进行TPCC基准性能测试,进行了2000的并发压测,TPMC下降了约有2%,属于可接受的范围。
2.3 相关指标
语句属性列说明:
| 类型 | 描述 |
|---|---|
username | 下发作业的用户 |
query_band | 用于标示作业类型,可通过GUC参数query_band进行设置,默认为空字符串,可通过该函数标识作业 |
queryid | 语句执行时标识语句的ID |
query | 正在执行的语句 |
resource_pool | 用户使用的资源池 |
enqueue | 作业负载管理状态 |
control_group | 作业所使用的cgroup |
query_plan | 作业的执行计划 |
warning | 作业的告警信息及SQL自诊断调优相关告警 |
stmt_type | 作业的类型,如INERT、UPDATE、DELETE等 |
语句的执行信息属性列,斜体代表可更换前缀/后缀式的指标,类似前缀后缀有:
min_,max_,total_,average_,_skew_percent
| 指标 | 具体列名 | 描述 |
|---|---|---|
语句执行时间 | block_time/start_time | 作业阻塞时长/作业开始运行时间 |
estimate_total_time/duration | 作业执行预估总时间/作业已经执行的时间 | |
DN执行时长 | max_dn_time | 作业在所有DN上的执行时间(最小、最大、平均、倾斜率) |
max_cpu_time | 作业在所有DN上的运行占用CPU的时间(最小、最大、总和、倾斜率) | |
作业占用内存 | estimate_memory | 作业执行预估内存 |
max_peak_memory | 作业在所有DN上占用内存值峰值指标(最小、最大、平均、倾斜率) | |
下盘量 | spill_info | 作业在DN上的下盘信息.[a:b]:数量为b个DN中有a个DN下盘 |
max_spill_size | 作业在所有DN上的下盘数据量(最小、最大、平均、倾斜率) | |
读写IO | max_peak_iops | 作业在所有DN上的每秒IO峰值(最小、最大、平均、倾斜率) |
max_read_speed/max_write_speed | 作业在所有DN上的IO读速率/写速率(最小、最大、平均) | |
网络通信 | recv_pkg/send_pkg/recv_bytes/send_bytes | 各个DN上的网络收发包数量,收发数据量 |
2.4 特殊情况说明:
TopSQL由于自身限制,存在一些记录异常的情况,此处对8.1.3版本的TopSQL语句记录情况进行说明:
不记录特殊数据定义语句,如:SET、RESET、SHOW、ALTER SESSION SET、SET CONSTRAINTS语句;
记录数据定义语句,例如:执行CREATE、ALTER、DROP、GRANT、REVOKE和VACUUM语句;
记录数据操作语句,例如:
执行SELECT、INSERT、UPDATE和DELETE语句。
执行explain analyze和explain performance场景。
执行查询query级别/perf级别视图
ODBC下发作业,由于多语句原因,会记录事务的BEGIN和end语句;
JDBC下发作业,随机性多记录一条JDBC的内部语句
解析错误和语法报错的异常不记录
用户手动CANCEL作业,显示的监控数据可能为0;
当子语句开关打开后,只会记录下发到DN上执行的子语句;
游标语句,当游标并非从缓存中读取数据,而确实触发语句下发到DN上执行的条件下,该游标语句会被记录,并且会进行语句、执行计划增强,但当游标从缓存中读取数据时,不进行记录;当游标语句在匿名块或者函数中使用时,当游标从DN上读取较多数据但不完全使用时,无法记录该游标在DN上的监控信息。
JDBC执行的带占位符语句,通常会补齐参数内容,但如果参数和原语句合起来长度超过64KB,则不记录参数,或者如果是轻量化语句,直接下发到DN上执行,不记录参数
2.5 TopSQL漏记问题
TopSQL在813版本中有一些语句不会被记录,大体分为几种情况,特此说明:
用户提交的dbms_job.submit提交后定时运行的作业,TopSQL不会记录。
当系统开启GTM-Free模式时,即查询该GUC参数,结果为true时。如果下发作业的用户所属的资源池快车车道并发不进行管控,则topsql信息不记录。
show enable_gtm_free
比如查询:
select * from pg_resource_pool;
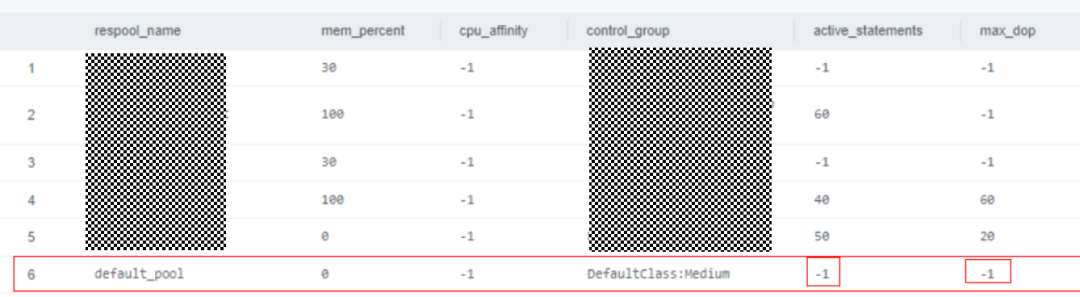
▲图2
从图2可以看到default_pool资源池的active_statements和max_dop都为-1,都不进行管控,此时通过该资源池绑定的用户下发作业,TopSQL不记录作业信息。

TopSQL功能是GaussDB(DWS)支持性能问题定位、语句劣化分析、审计回溯等重要功能的基石。在此基础上,内核也拓展出了异常规则等一些高阶用法,在日常使用中,用户也对TopSQL提出了更高的要求,比如记录子语句、记录语句类型、提升算子级别语句监控准确性等诸多建议。为此,GaussDB(DWS)团队会在此基础上继续演进,更好的服务用户,提升用户满意度。

| 字段名称 | 字段描述 | 分析可能出现的问题 |
|---|---|---|
block_time | 语句执行前的阻塞时间,包含:语句解析、语句优化时间,以及作业排队时间。 | A1: block_time较大,而duration值并无明显变化,说明用户作业受其它作业影响,在真正开始执行前进行了较长时间的排队,下一步需要接着查看当前数据表,统计起始时间小于start_time、结束时间大于finish_time的作业数量。 A2: block_time较小,而duration值较大,说明用户作业执行时间增加较大原因是自己导致,需要继续分析数据量的变化情况、各DN的执行时间变化。 |
start_time | 语句开始执行时间。 | |
finish_time | 语句执行结束时间。 | |
duration | 语句执行时长。 | |
status | 语句执行的结束状态,正常为finished,异常为aborted。 | 可以查看作业是否正常结束,如果异常,还会有异常原因。 |
abort_info | 语句执行结束状态为aborted时显示异常信息。 |
想要了解更多TopSQL实践?点击文末阅读原文一键获取~
总结一下:
因数据量变化,导致作业执行时间增加,可以分析A2/B1/D1/G1,进而确认作业查询的数据表是否有明显的数据量增加;
因其它并发作业抢占,导致作业排队,从而导致作业执行时间增加,可以分析A1/B1/D1,进而查看作业执行的同时期是否有大量并发作业在执行;
因其它作业而产生的CPU抢占,导致作业执行时间增加,可以分析A2/D1/E1,进而查看作业执行的同时期是否有大量并发作业在执行;
因其它作业而产生的IO抢占,导致作业执行时间增加,可以分析A2/F1,进而查看作业执行的同时期是否有大量并发作业在执行;
I1中有结果情况,可通过提示的信息进行分析,或者进行SQL自适应诊断相关告警处理,SQL自适应诊断处理方法见:https://support.huaweicloud.com/performance-dws/dws_10_0013.html
对于enqueue异常排队的情况H1,用户可参考:《GaussDB(DWS)资源管理排队原理与问题定位》进行问题排查分析。
在华为云官网(huaweicloud.com)搜索文章名即可阅读。
值得注意的是,发生资源争抢时,可能会出现并发症,即CPU、IO抢占,作业排队现象都会发生,针对并发症问题,可以逐步分析解决,比如:
第一步,调整作业执行顺序,减少并发作业数量,减少阻塞时间;
第二步,定位出同时段执行的典型计算密集型、存储密集型作业,先移动到其它时间段执行,减少对本作业的影响;
第三步,在无其他作业明显干预的情况下,做进一步分析。


 戳“阅读原文”,了解更多TopSQL实践
戳“阅读原文”,了解更多TopSQL实践
