





“ 无所不能便一无所精”是经常在演讲中出现的措辞。这句话背后的意思是,如果您想在所有方面都变得出色,那么您通常会在很多事情上表现平平,没有擅长的事物。软件,技术以及图数据库也不例外。
数据库满足所有不同类型的功能:批处理和事务性工作负载,内存访问和磁盘访问,SQL和XML访问以及图形和文档数据存储。
在构建数据库管理系统(DBMS)时,开发团队必须尽早决定要针对哪些情况进行优化,这将决定DBMS处理其处理任务的能力如何(即,DBMS的出色之处,可以解决的问题以及可能做不到的事情)。因此,在图数据库的世界里,既有设计为 "图为先(graph first) "的技术,即所谓的原生图技术,也有图是事后才想到的数据库,被归为非原生图技术。在图存储和处理的原生架构上,都有相当大的区别。不足为奇的是,原生技术往往执行查询的速度更快,规模更大(随着数据集规模的增长,保留其标志性的查询速度),运行效率更高,对硬件的要求更低。非原生图则不然。
了解这些差异非常重要-特别是如果您要考虑购买新的数据库许可证。


本文中我们将讨论区分原生图数据库技术的关键特性--以及为什么它们对数据库性能很重要。
原生图技术的区别主要有两个要素:存储和处理图形存储通常指的是包含图形数据的数据库底层结构。
如果专门为存储类图数据而构建,则称为原生图存储。采用原生图存储的图数据库在各方面都针对图进行了优化,通过将节点和关系写得很近,保证了数据的高效存储。当图形存储来自外部源(例如关系型,宽列型或其他NoSQL数据库)时,则将其分类为非原生存储。这些数据库存储的是关于节点和关系的数据,这些数据在实际存储中可能最终相距甚远。这种非原生的方法可能存在一些隐患,因为它们的存储层没有针对图进行优化。
原生图处理是图技术的另一个关键要素,指的是图数据库如何处理数据库操作,包括存储和查询。无索引邻接是原生图处理的关键区别。在写入时,无索引邻接通过确保直接存储每个节点来加快处理速度与其相邻的节点和关系。然后,在查询处理期间(即读取时间),无索引的邻接关系可确保在不严重依赖索引的情况下实现闪电般的快速检索。非原生图处理通常使用大量索引来完成读或写事务,从而大大降低了操作速度。
另一个重要的考虑因素是ACID写入。连接数据对数据完整性的要求异常严格,超出了其他NoSQL模型的要求。为了存储两个事物之间的连接,我们不仅要写入关系记录,还要更新关系两端的节点。如果这三个写操作中的任何一个失败,都会导致图的损坏(字面意思是最坏的情况)。
确保图形不会随着时间的推移而损坏的唯一方法是以完全符合ACID标准的事务来进行写入。具有原生图处理的系统包括适当的内部防护轨,以确保数据质量不受网络突发事件、服务器故障、竞争性事务等影响。
让我们仔细看看为什么原生图存储和原生图处理如此重要。
图存储之所以具有独特的原生性,是因为图数据库架构从底层开始建立的。具有原生图存储的图数据库具有专门为图的存储和管理而设计的底层存储。它们的设计是为了在任意图算法期间最大限度地提高遍历速度。
例如,我们来看看Neo4j--一个原生图数据库--是对于原生图存储的结构方式。这个架构的每一层--从Cypher查询语言到磁盘上的文件--都是为存储图数据而优化的,没有任何一个部分是从其他非图技术中以弗兰肯斯坦式的方式(frankenstein-esque)栓上去的。 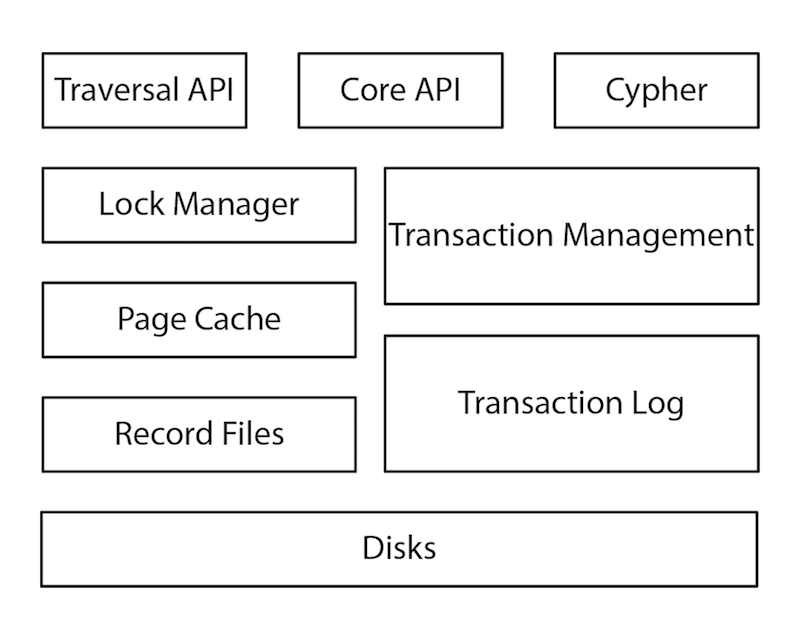
图数据保存在存储文件中,每个文件都包含图形特定部分的数据,例如节点,关系,标签和属性。以这种方式划分存储空间有助于实现高性能的图遍历(如上所述)。在原生图数据库中,节点记录的主要目的是简单地指向关系、标签和属性的列表,使其轻量级。
那么,非原生图存储与原生图数据库中的存储有什么不同呢?非原生图存储使用关系型数据库、列式数据库或其他一些通用数据存储,而不是专门为图数据的独特性而设计的。虽然典型的运营团队可能更熟悉非图后端(如MySQL或Cassandra),但图数据与非图存储之间的脱节导致了一些性能和可扩展性问题。非原生图数据库并未针对存储图进行优化,因此用于写入数据的算法可能会在各处存储节点和关系。这将导致在检索时出现性能问题,因为随后必须为每个单个查询重新组合所有这些节点和关系。在24×7的生产方案中,每分钟可能有数千个查询。另一方面,原生图存储是为了从根本上处理高度互联的数据集而构建的,因此在图数据的存储和检索方面是最高效的。
如果图数据库使用无索引邻接,则它具有原生处理功能。这意味着每个节点都直接引用其相邻节点,充当所有附近节点的微索引。与索引相同的任务相比,无索引邻接更便宜,更高效,因为查询时间与搜索的图的数量成正比,而不是随数据的整体大小而增加。
如果没有无索引的邻接性 一个大型的图数据集会在其自身的重量下被压垮 因为随着数据集的增长,查询的时间会越来越长。反过来说,无论你的数据大小如何,原生图查询的执行速度都是恒定的。
由于图数据库将关系数据存储为一级实体,因此通过原生图处理,关系在任何方向上都更容易遍历。通过专门为图数据集构建的处理,关系(而不是过度依赖索引)可用于最大化遍历效率。
请看下图一个基本的社交网络,在这个网络中,查询是在本机处理的关系数据上进行的(谁和谁有关系?),而不需要进一步的索引查找。
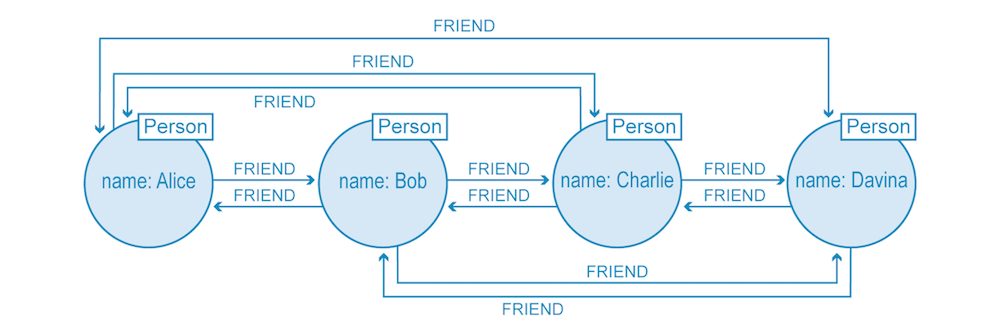
另一方面,非原生图数据库使用多种类型的索引将节点连接在一起。这种方法成本较高,因为索引在每次读写时又增加了一层,大大降低了处理速度。具有多个连接层的查询(即,你希望或需要从图数据库中进行的查询类型)进一步降低了非原生图处理的遍历性能。
下图说明了一个非原生图查询只查找一层连接的例子--想象一下,当你跨更多跳数查询时,处理时间会成倍增加。
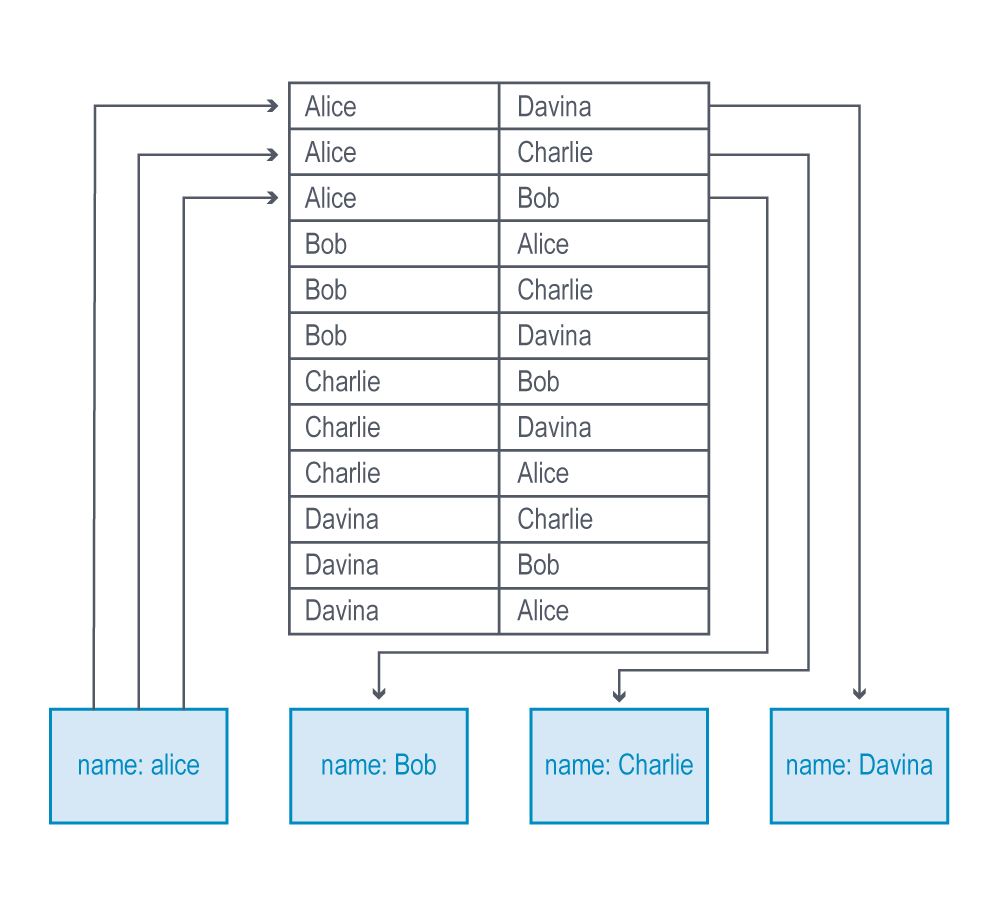
此外,在非原生图处理的情况下,逆转遍历的方向是非常困难的。要反转查询的方向,您必须为每次遍历创建一个代价高昂的反向查找索引,或者对原始索引执行蛮力搜索。这两种变通方法都会让你得到你要找的结果--最终--但它们破坏了使用图数据库的初衷:高效查询数据中的关系。
在确定原生图数据库和非原生图数据库之间时,了解使用每个图数据库的权衡点很重要。
非原生图技术很可能有一个你的开发团队已经熟悉的持久层(如Cassandra、MySQL或其他关系型数据库),当你的数据很小或连接性不强时,选择非原生图技术不太可能显著影响你的应用性能。
不过扪心自问,你的数据可能会随着时间的推移而一直保持小规模和少联系吗?可能不会。数据集往往会随着时间的推移而增长,而如今的数据集比以往任何时候都更加结构化、相互连接和相互关联。即使您的数据集一开始规模很小,但如果您的数据很可能与您的业务一起增长,那么为未来做规划就很重要。在这种情况下,从长远来看,原生图数据库为您提供更好的服务,因为在更大的数据集下,非原生图处理的性能会瘫痪。
转向原生图架构的最大驱动力之一就是它的扩展性。当您向数据库中添加更多数据时,当你向数据库中添加更多的数据时,许多在非原生图数据库中会随着大小而变慢的查询,在原生环境中仍然是轻快的。原生图缩放利用了存储和处理中的大量优化,产生了一种高效的方法,而非原生图则使用蛮力解决问题,需要更多的硬件(通常是硬件量的2-4倍或更多),导致延迟降低,尤其是对于较大的图。
然而并非所有的应用都需要低延迟或处理效率,在这些用例中,非原生图数据库可能就能完成任务。(不过说真的,那你为什么要用图数据库来完成这类任务呢?)但是,如果你的应用需要实时存储、查询和遍历大型互联数据集,以实现24×7、始终在线的任务关键型应用,那么你就需要一个专门为大规模处理图数据而设计的数据库架构。
最后,原生图技术与非原生图技术的重要性取决于你的应用的特殊需求,但对于希望利用数据中的连接的企业来说,原生图数据库技术对于成功至关重要。
en
欢迎关注湖大图谱研究

