




导读:今天和大家分享一下腾讯统一大数据调度平台-US,主要包括以下四大部分内容:
系统简介
系统设计
运营情况
未来规划
扫码可下载本文PPT

分享嘉宾|马朋勃 腾讯大数据 高级工程师
编辑整理|曹红姣 平安人寿保险
出品社区|DataFun
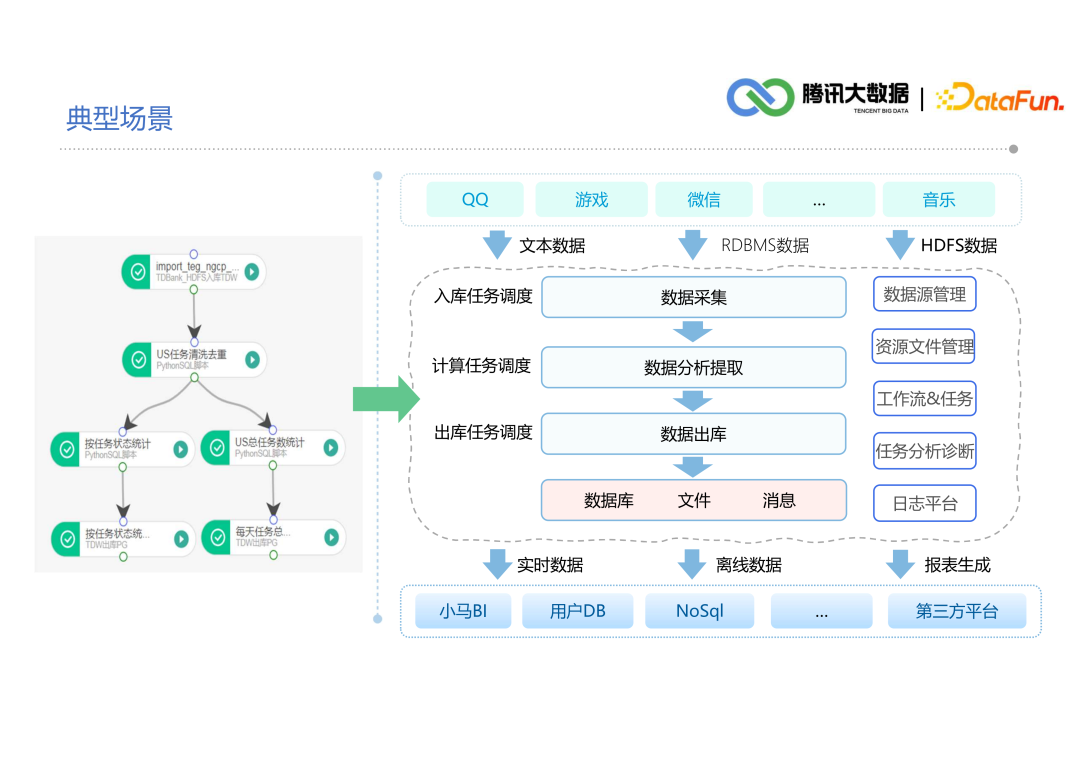
02
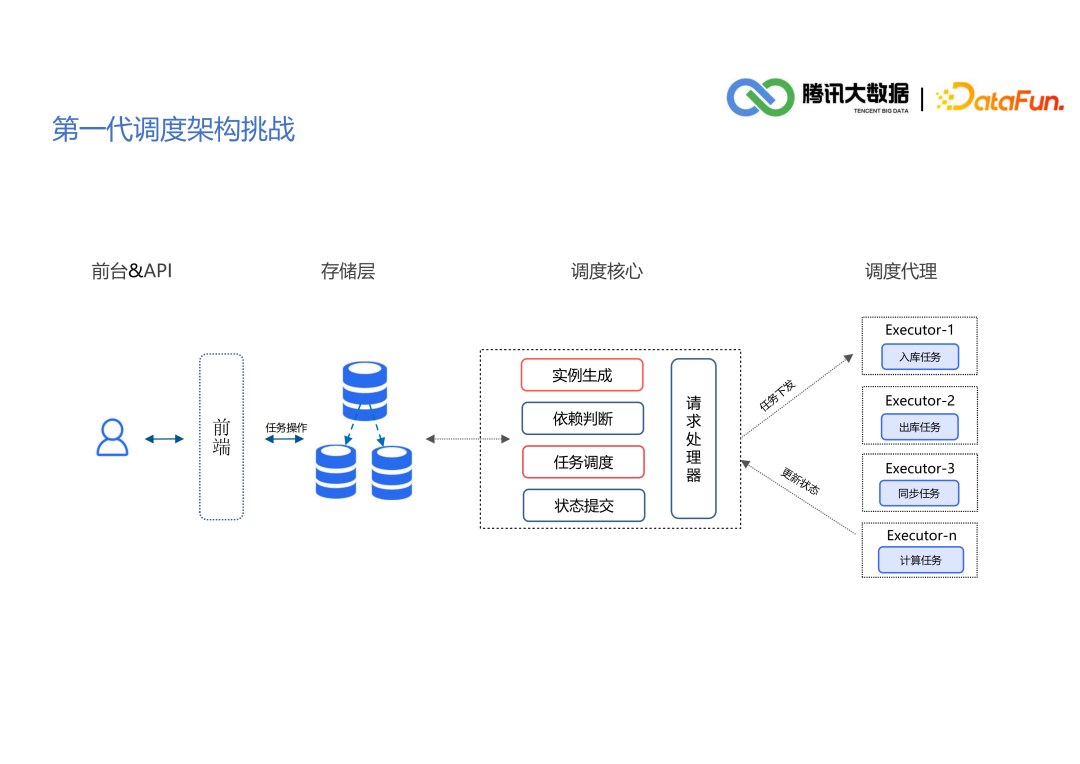
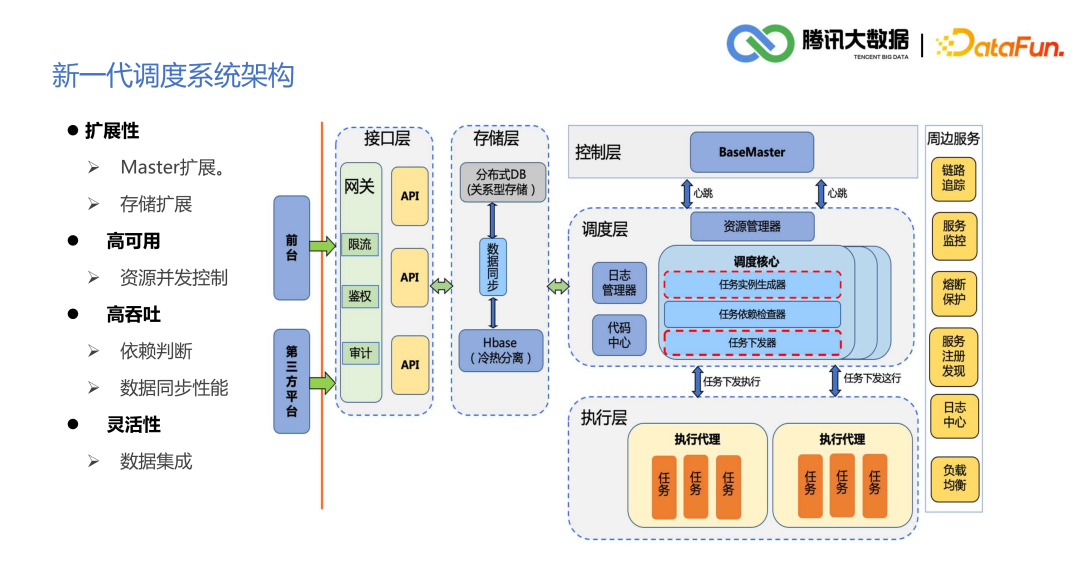
3. 新一代调度系统架构
4. 实例化
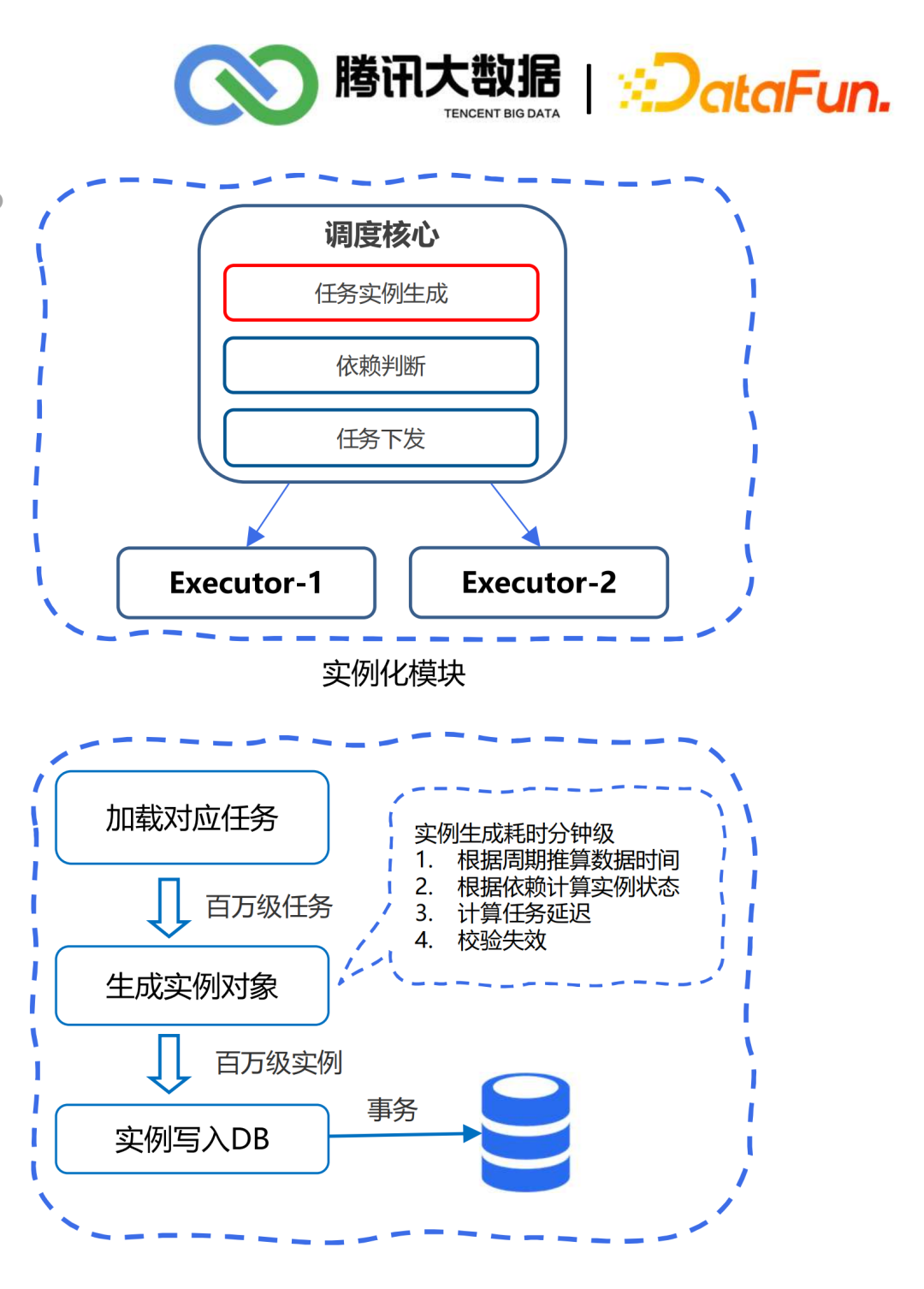
体量大,即每天调度百万级任务,生成千万级实例,并且单库达到3亿+历史实例; 用户对实效要求高,短周期任务多,时间敏感度高; 波峰效应,高峰期瞬时实例剧增,对系统吞吐性能要求高。
应用负载高:调度内核负载高且水平扩展困难,百万任务单机调度; 存储负载高:数据库单机已达到瓶颈,虽然做了读写分离,但是单节点还是需要保存所有数据; 程序性能差:由于生成和写入数据库是串行操作,导致大数据事务,而且回滚又会造成大批量任务的延时。
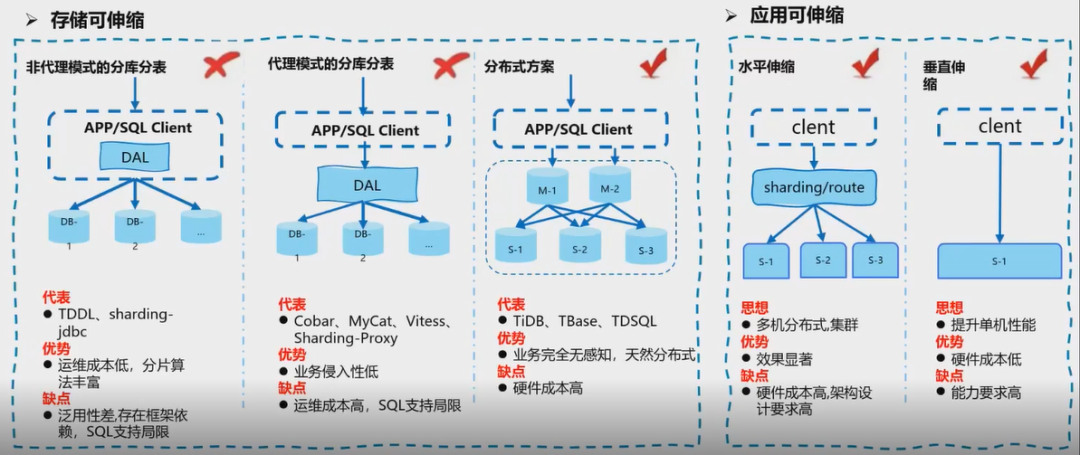
非代理模式的分库分表:应用和数据是放在同一个进程,它的优点是分片算法非常丰富,业务可以自定义分片逻辑;由于没有多余的服务进程,它的运维成本比较低,但是分片逻辑和业务耦合度高,导致泛用性较差。 代理模式的分库分表:DAL(数据接入层)作为单独的一个进程存在,对业务的侵入低,但是需要维护 DAL 服务,运维成本相对而言高一些。 分布式方案:对业务完全无感知,由 DB 层维护分布式事务和分片相应的逻辑,对硬件成本要求比较高。
水平伸缩:通过增加机器的方式来分担系统的压力,对架构设计要求相对较高。 垂直伸缩:通过提高单机的性能,包括对软件的优化及硬件的升级,由于主要从软件层面,因此对开发人员的要求比较高。
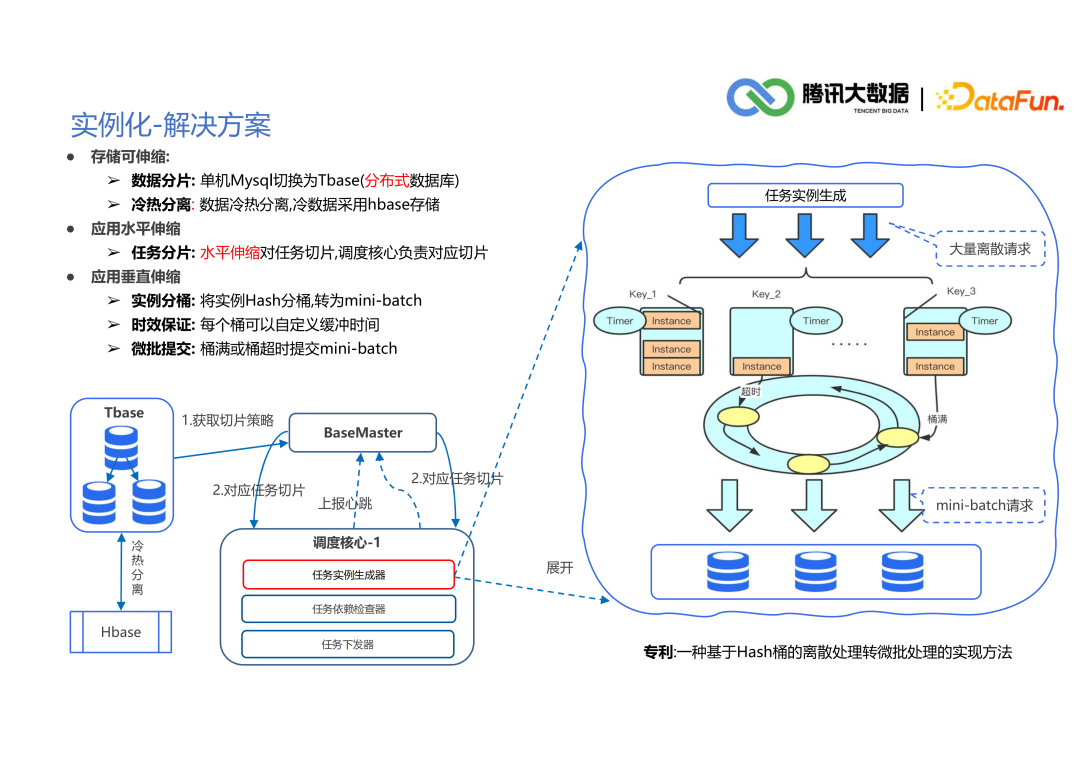
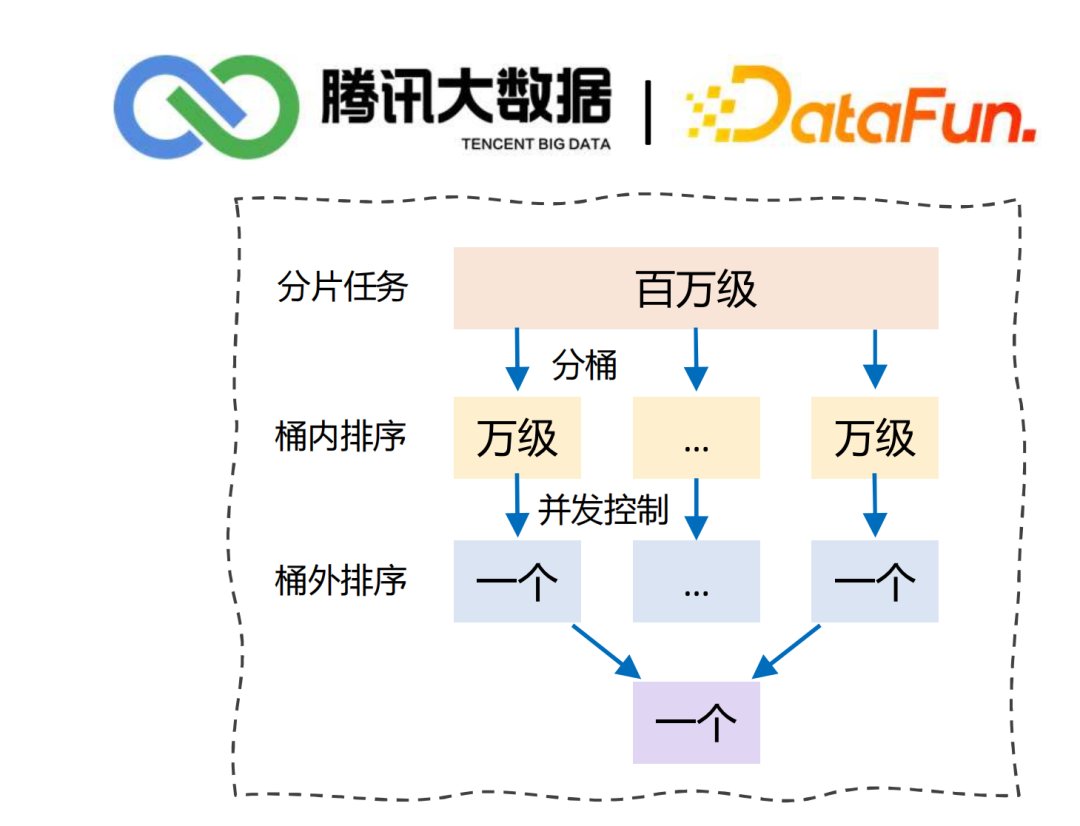
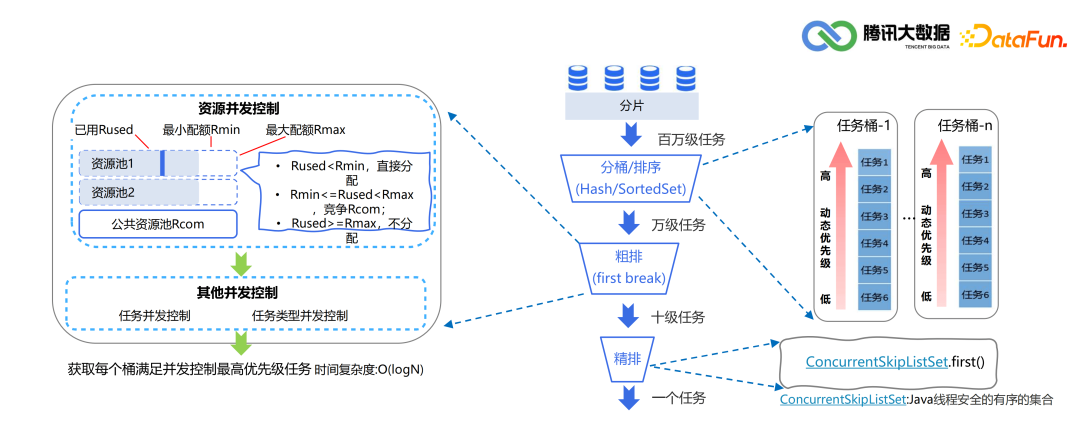
5. 任务下发
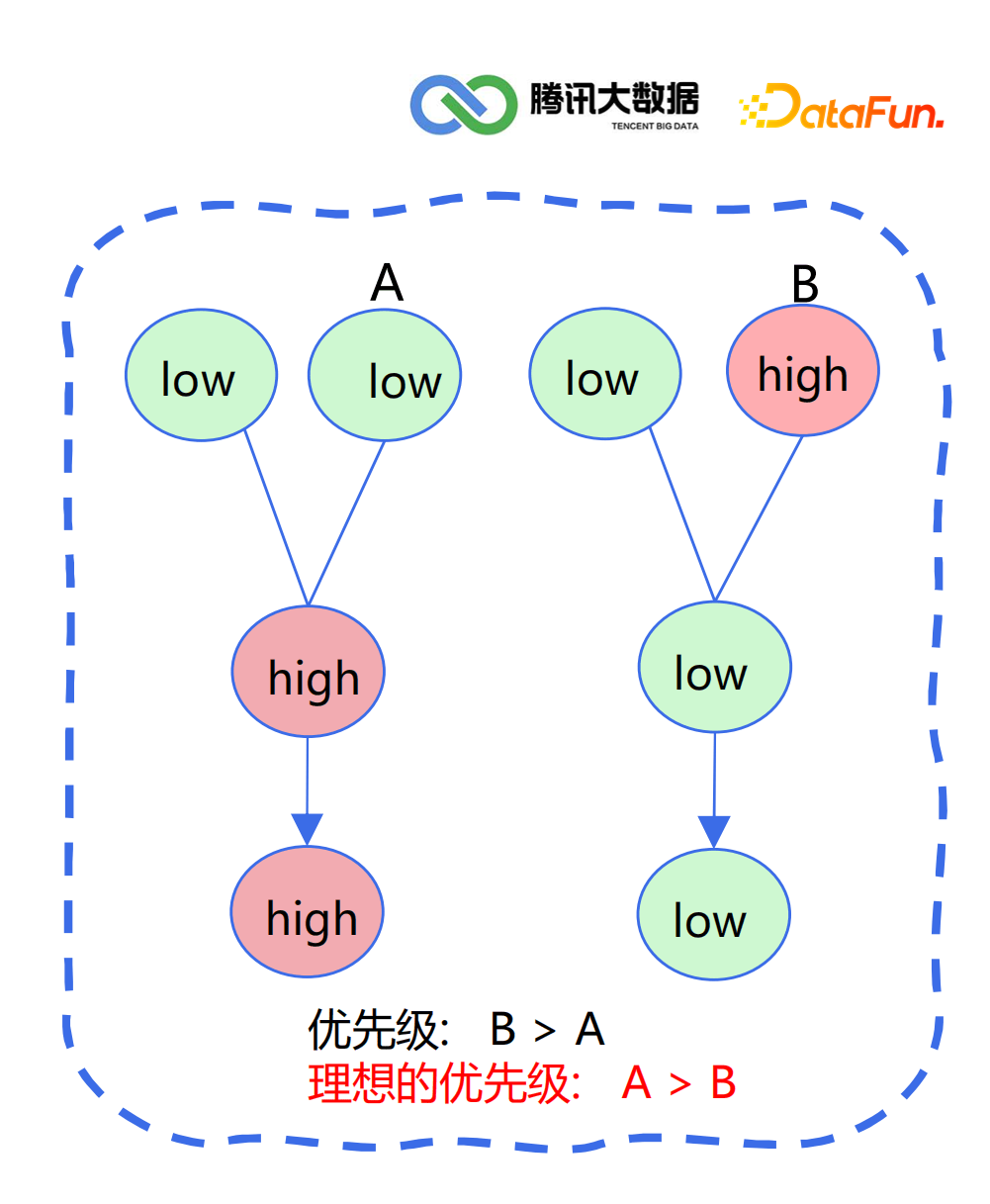
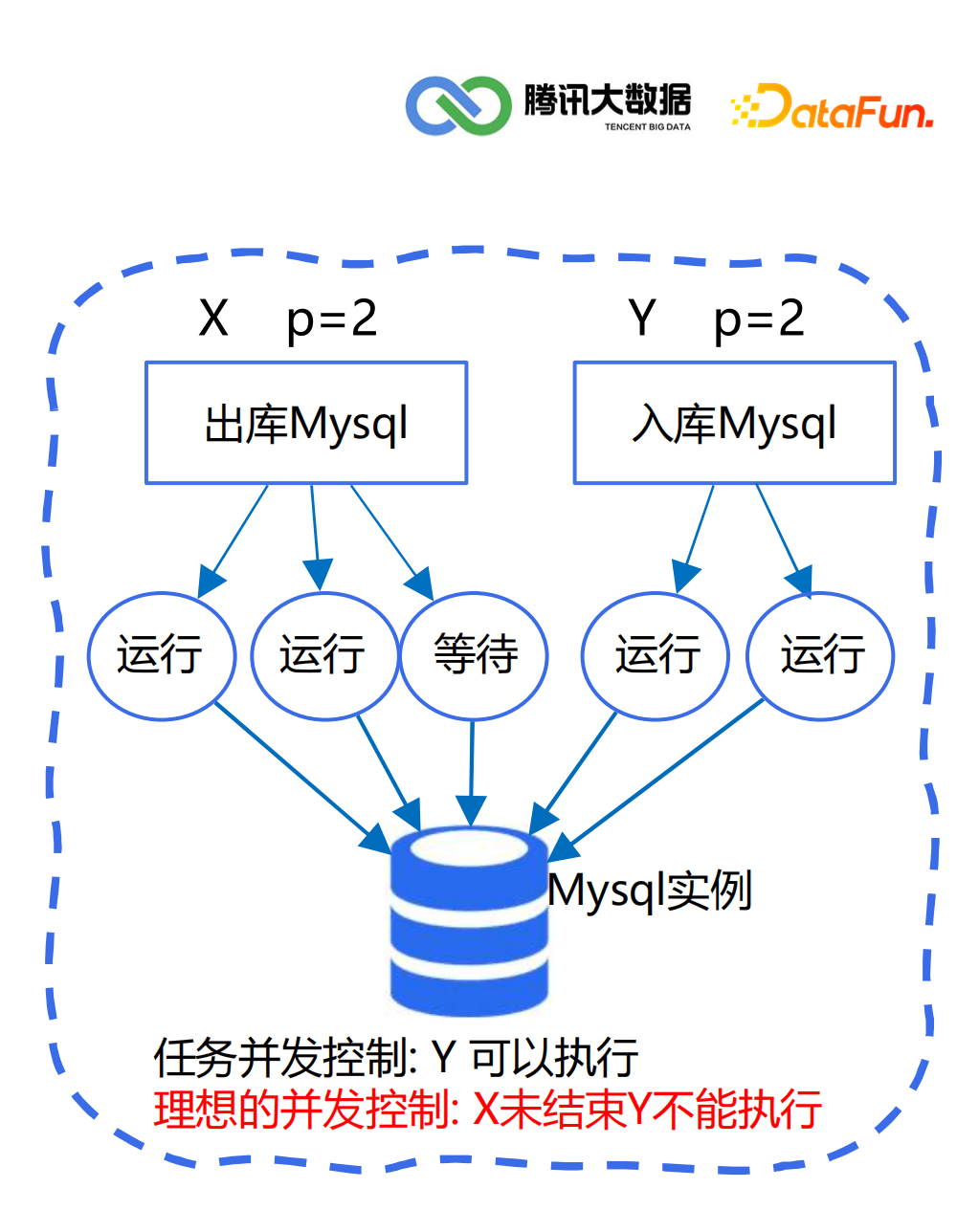
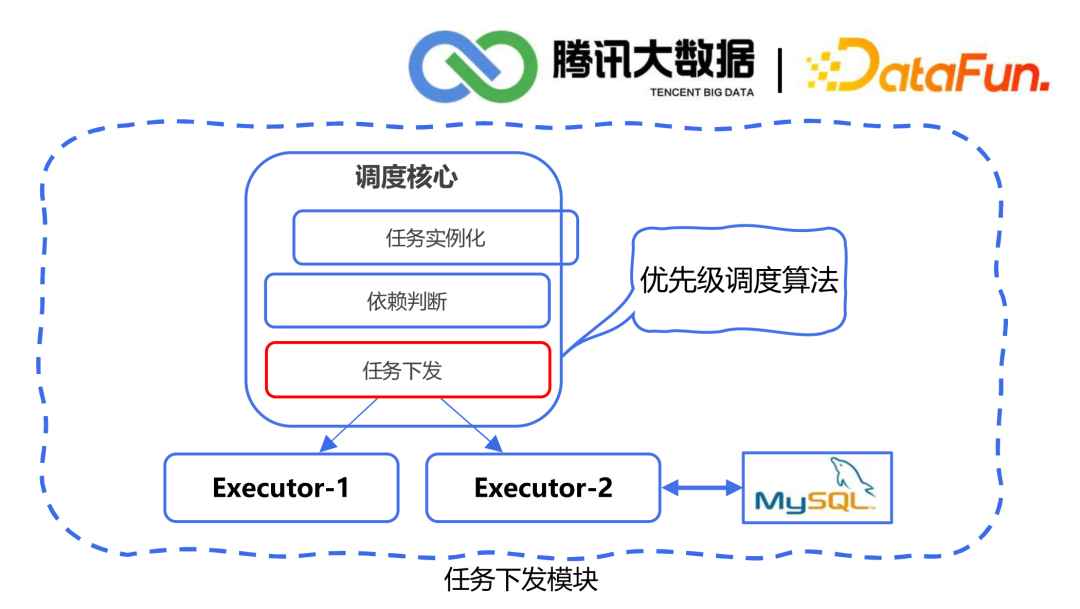
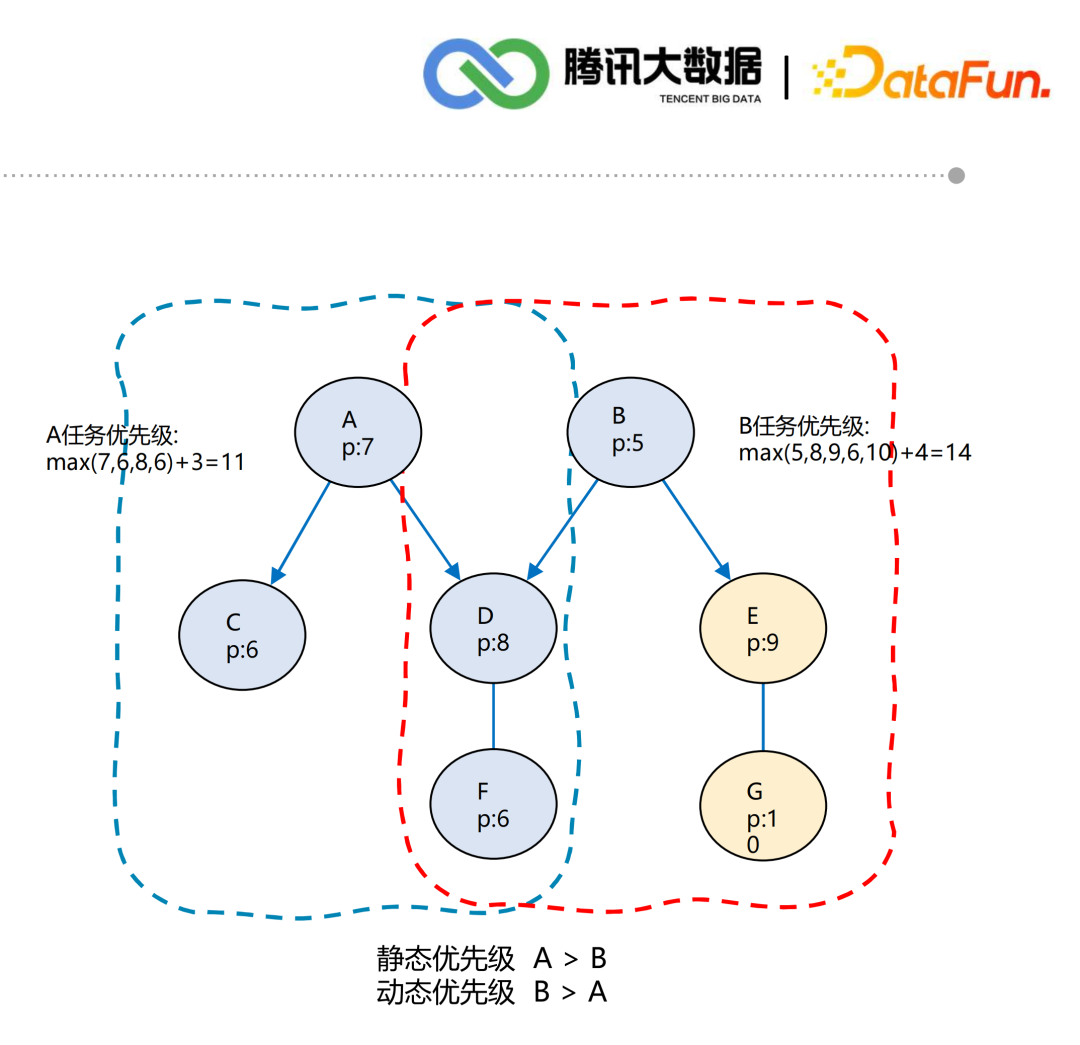
延迟时间(紧迫性):延迟越久,优先级越高 静态优先级(关键性):业务关键任务 周期(频繁性):分钟>小时>天>周>月 任务类型(快捷性):check(检查)>sync(同步)>calculating(计算) 链路(传递性):下游任务链路深度
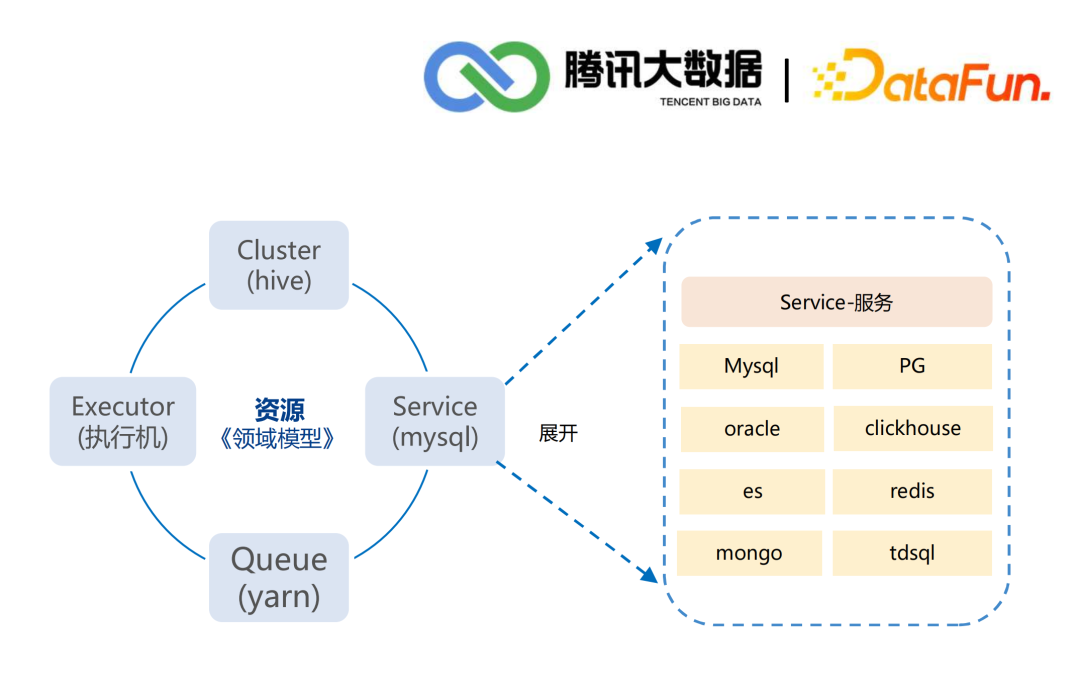
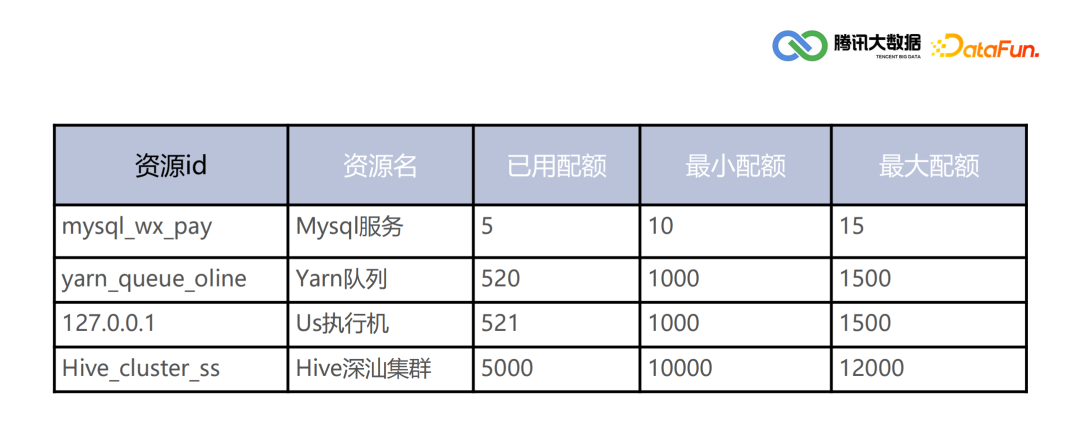
运营情况
1. 实例化落地效果
4. 赋能公有云
今天的分享就到这里,谢谢大家。

|分享嘉宾|

马朋勃
腾讯大数据 高级工程师
参加工作近十年,有丰富大数据处理经验,先后就职于芒果网,阿里,腾讯。目前在腾讯负责千万级大数据离线任务调度平台的研发。
🧐 分享、点赞、在看,给个3连击呗!👇
文章转载自志明与数据,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
