




『或曰』本篇为金融数据挖掘系列笔记第64篇,完成于2023年1月8日,系本人对报表数据集成诸多感性认识的小结,希冀从量变到质变,形成对数据治理之道规律性的理性认识,并据此指导新的实践,盘点数据要素,将之改造转化为能为使用者真正带来经济价值的数据资产。

近二十年来,为响应日益增长的分析需求,各类监管数据,无论是以1104报表、EAST数据、新版客户风险统计为代表的银保监会监管数据,还是人民银行金融统计报表、金数工程、反洗钱报表,或者报数机构自身经营所需的各类财务报表与信息披露资料,其报表种类、数据项采集数量与监管指标计算复杂度,都在持续快速上升。
但受数据治理思维与关系型数据库性能制约,各类报表数据集成与加总效率始终未见显著改善,统计分析与风险监测常态化依靠诸多临时报表、快速调查与人员加班加点来完成,这一局面明显不适应智能监管与数字化转型客观要求,改进原有技术与方法势在必行。
一、图思维与深层计算
当前,各类监管信息,尤其是结构化数据,普遍使用二维表与关系型数据库存储,而且往往是“所见即所得”,即业务需要展示为何种纵横交错的表格,数据库的实体表就被设计成什么样,存在大量数据冗余。同时,因关系型数据库只适合面向元数据的聚合、筛选等操作(浅层计算),导致涉及多表关联、K相邻计算等需要对(分门别类的)元数据开展复杂查询(深层计算)时,其运行效率会随查询深度增加而指数级降低,使得数据生产者常面对“数据确实有,短时间就是找不到”的尴尬局面,这是临时报表频发的核心因素。
有学者认为,如果用数学语言来描述人类的思考模式,那么人本质上是在用图的方式来思考。即将一个个知识点存储于大脑(记忆)中,并从一个(或多个)知识点出发,沿着彼此间的关联去遍历、过滤、搜索,抽丝剥茧得到具体路径或相互交织的网络。这些实体(点)与关系(边)所组成的网络被称之为图(Graph)。当点(边)带有属性,很有助于信息的筛选、聚合或传导计算,这种图被称为属性图(Property Graph)。带有属性的图可用来表达一切事物,无论它们是关联的还是离散的。(如知识图谱与思维导图)
当事物(点)彼此关联(边)就会形成网络,当它们离散开来,就如同罗列的一列数据表,或关系型数据库实体表中的一行行数据。图的展示方式往往高于二维,它可以向下兼容并表述低维空间的信息,反之则极其困难,如同关系型数据库以多表关联实现复杂查询的计算过程产生的天量笛卡尔集合。
二、监管数据的降维与升维变换
目前基于“所见即所得”的逻辑,用于存储数据的关系型数据库实体表与业务报表结构大同小异;分析需求常常变化,业务报表因之而变(如每年一变的银保监1104报表、人行金融统计),数据库实体表随之变化,导致技术底层的数据结构始终不稳定,因此关系型数据库无法通过分区、索引等技术来优化浅层计算效率。同时,对涉及多版本、多时点、多指标的数据集成(如2015年至今1104报表《S67房地产融资监测表》的五个版本数百个指标的增删改并),开展特定指标的时间序列趋势分析必须采用深层计算,费事费力,极易出错。为此,本人基于实践经验,探索出以下方法:
(一)降维变换,提升实体表存储效率
各业务报表皆可被视为由“横行标目”(Y轴)与“纵栏标目”(X轴)构成的二维表,每一业务指标皆可被视为该平面直角坐标系的一个点(x,y)。如S67表(221版)指标“1.房地产贷款合计-A期末余额情况-本期”,可被表述为指标1(1,A)。则该表110行(1-108)19列(A-S)共110*19=2090项指标,数据库实体表存储结构可变换为2090*1=2090项指标。通过数据库实体表存储结构与业务报表具体结构的分离,将千差万别的二维业务报表通通降维变换为一堆离散的点(图思维),形似一张一维表,而报数机构、数据时点、报表编号(S67)、版本号(221版)、横行标目、纵栏标目皆是每个点的属性。无论业务报表如何增删改并、数据库实体表始终不变,从而将深层计算皆转换为浅层计算,极大提升了数据存储效率。
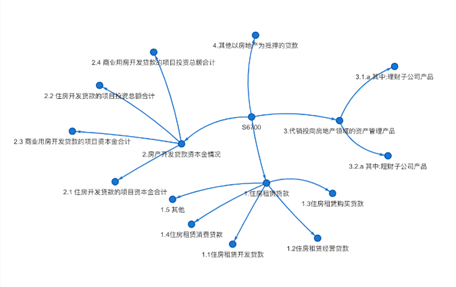
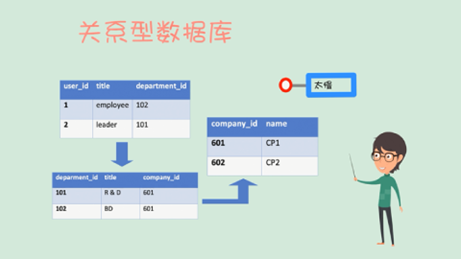
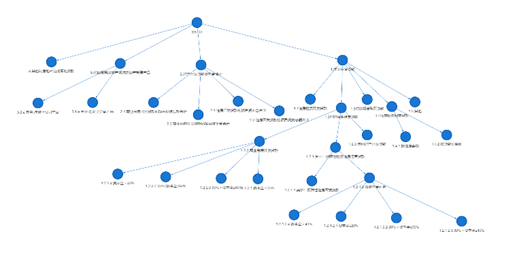
(二)升维变换,提升业务数据集成效率
在同一报表编号、多个版本的业务指标基础上再次抽象,增加一维(可称为“锚点”指标),以最新一版业务报表为蓝本,建立每个版本每项指标与“锚点”指标的N对1映射规则,既可将之展示为点(多项业务指标)+边(映射关系)的网络(图),利于数据生产者(报送、审核、加总人员)便捷梳理数据血缘,实施治理,管控质量;又可将之存储在二维表中(可称为“维度表”),数据消费者(各层次/条线的业务分析人员)仅需调用维度表锚点指标,即可快速集成不同时期/版本的全量业务数据开展日常分析,极大提升数据集成效率。出现新版本报表,仅需报数机构总部(或外部监管者)更新“锚点”指标版本,即可保证全系统(全行业)的业务指标体系变更。在此基础上形成分析图表,开展历史数据趋势分析,既敏捷灵活,又相对稳定,省时省力。
(三)算法优化,提升数据校验效率
基于降维变换的数据库实体表,同一时点多张业务报表的全部指标皆被存储为包含各类业务属性(报数机构、数据时点、报表编号、横行标目、纵栏标目)的N个离散点(或简化理解为1张N行1列的一维表);多张业务报表纷繁复杂的表内、表间校验公式(M条规则),皆可被撰写为标准化代码(M*N次计算)由计算机跑批进行,一次变换、全国通用,将数据生成者从繁重、枯燥的数据校验与复核劳动中解放出来,投入更多精力盘点数据资产,实现数据价值。
本方法下,将每一监管报表的数据业务逻辑与技术存储逻辑分离为两类,通过降维变换实现了无论业务报表如何变更,基础数据存储“内核”结构稳定,为优化各业务系统数据通过ETL集成到数仓、数集的工作效率奠定了良好基础。又通过升维变换,将同一编号、不同版本业务报表的诸多指标,有效集成为相对稳定的“锚点”指标体系,供各类数据消费者使用。在这一流程下,数据供给、参与、消费各司其职,高效协作,实现了数据生产的“标准化+多样化”,可以充分满足各类数据消费者“个性化需求”。
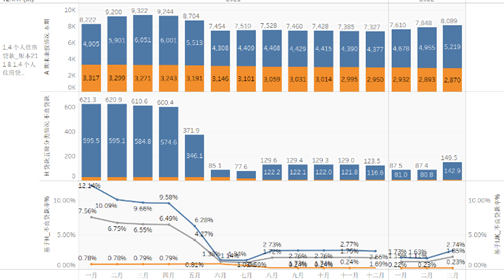
笔者已在日常实践中初步实现1104报表中G01、G11、S67、S71等表多版本、多时点上千项监管指标的高效集成,结合可视化分析软件,现已可准确、快捷、多维分析多机构、多时点、多指标的敏捷可视化分析。该方法如能固化为BI软件等数字科技产品,必能泽被各方,善莫大焉。
回首一望,2022年忙着数据挖掘实践与考DAMA的CDGP证书,居然一整年未形成一篇挖掘札记,惭愧惭愧!学如逆水行舟,不进则退,数据生产要素已成为新时代重要资源,向数字科技要生产力,切实推动数字化转型,提升智能风控与合规科技能力已是时代潮流,道虽远行则将至,事虽难做则必成,大家协作,共同进化吧!
