




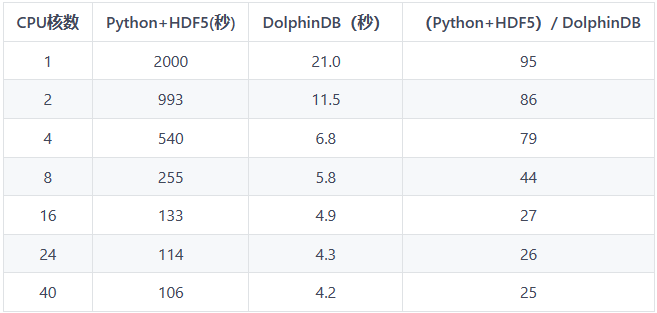
在单核的前提下,DolphinDB 库内计算比 Python + HDF5 计算快接近100倍。随着可用 CPU 核数逐渐增加,DolphinDB 与 Python + HDF5 计算耗时比逐渐趋近 1:25 左右。
因子计算是非常常见的投研需求,以L2高频行情为例,目前国内全市场十年的 L2 历史数据约为 20 ~ 50T,每日新增的数据量约为 10 ~ 20G。常见的方案是使用 Python 进行投研开发,并配合 HDF5 存储行情数据,组合进行量化金融计算。
在高频数据的存储上,虽然 HDF5 的支持强于 MS SQL Server、MySQL 等传统的关系型数据库,但仍然存在以下问题:
数据权限管理困难
不同数据关联不便
检索和查询不便
需要通过数据冗余来提高性能
与 Python 之间的数据交互耗费时间
……
完整的测试脚本和教程已发布在官方知乎,可点击文末阅读原文查看。
可以看到,在两种方案计算结果完全一致的前提下,单核 DolphinDB 库内计算比 Python + HDF5计算快接近100倍,随着可用 CPU 核数逐渐增加,DolphinDB 与 Python + HDF5 耗时比逐渐趋近 1:25 左右。
01
存储引擎与分区机制保证高效数据读取
相比之下,DolphinDB 的数据管理、查询、使用更为简单便捷。得益于 DolphinDB 的不同存储引擎及分区机制,用户可以以普通数据库的方式轻松管理和使用 PB 级及以上数量级别的数据。
02
移动窗口计算优化提供更高性能
03
原生分布式自动并行调度
综合而言,在生产环境中,使用 DolphinDB 进行因子计算和存储远比使用 Python + HDF5 计算方式更加高效:
代码实现方面,DolphinDB 的库内计算更易于实现因子计算调用及并行调用。 计算速度方面,DolphinDB 的库内计算比 Python + HDF5 的计算方式快 25 倍以上。 并行计算方面,DolphinDB 可以自动使用当前可用的 CPU 资源,而Python 脚本需要通过并行调度代码实现。
Explore More




文章转载自DolphinDB智臾科技,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
