




PolarDB for PostgreSQL(简称 PolarDB-PG)是一款阿里云自主研发的云原生关系型数据库产品,100% 兼容 PostgreSQL,高度兼容Oracle语法;采用基于 Shared-Storage 的存储计算分离架构,具有极致弹性、毫秒级延迟、HTAP 的能力和高可靠、高可用、弹性扩展等企业级数据库特性。同时,PolarDB 具有大规模并行计算能力,可以应对OLTP与OLAP混合负载。
在 PolarDB 存储计算分离的架构基础上我们研发了基于共享存储的MPP架构步具备了 HTAP 的能力,对一套 TP的数据支持两套执行引擎:
- 单机执行引擎用于处理高并发的 OLTP
- MPP跨机分布式执行引擎用于复杂的 OLAP 查询,发挥集群多个 RO 节点的算力和IO吞吐能力
PolarDB 性能表现
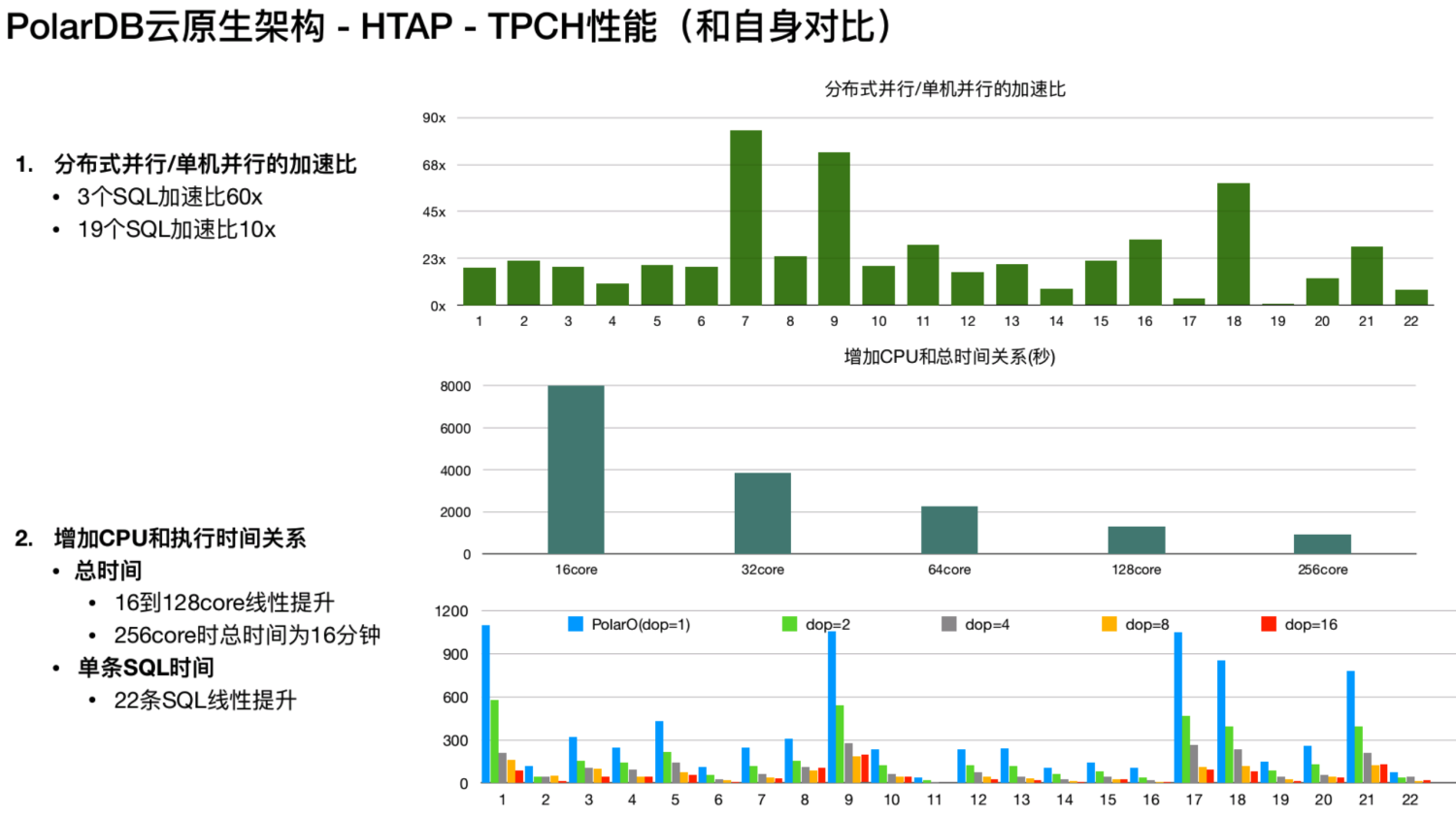
上图为 Polar DB 分布式并行性能和单机并行的性能的对比,第一张图显示了 TPCH 22条 SQL 加速比,其中有三条 SQL 的加速比是超过60倍的,大部分 SQL 都是超过十倍以上的提升。第二个测试将共享存储上 1TB 的TPCH的数据,16个计算节点,通过增加 CPU 看性能表现如何。在第二张测试图中,从16 core到 256 core,基本上是线性提升的表现,但是到 256core 就到达瓶颈。这是因为受限于存储带宽,如果增加带宽,整体的性能还会提升。最下方的图里面显示了22 条 SQL 在16core 到 256core 的性能的表现,可以看到在 16core 到 128core 时是线性提升的。
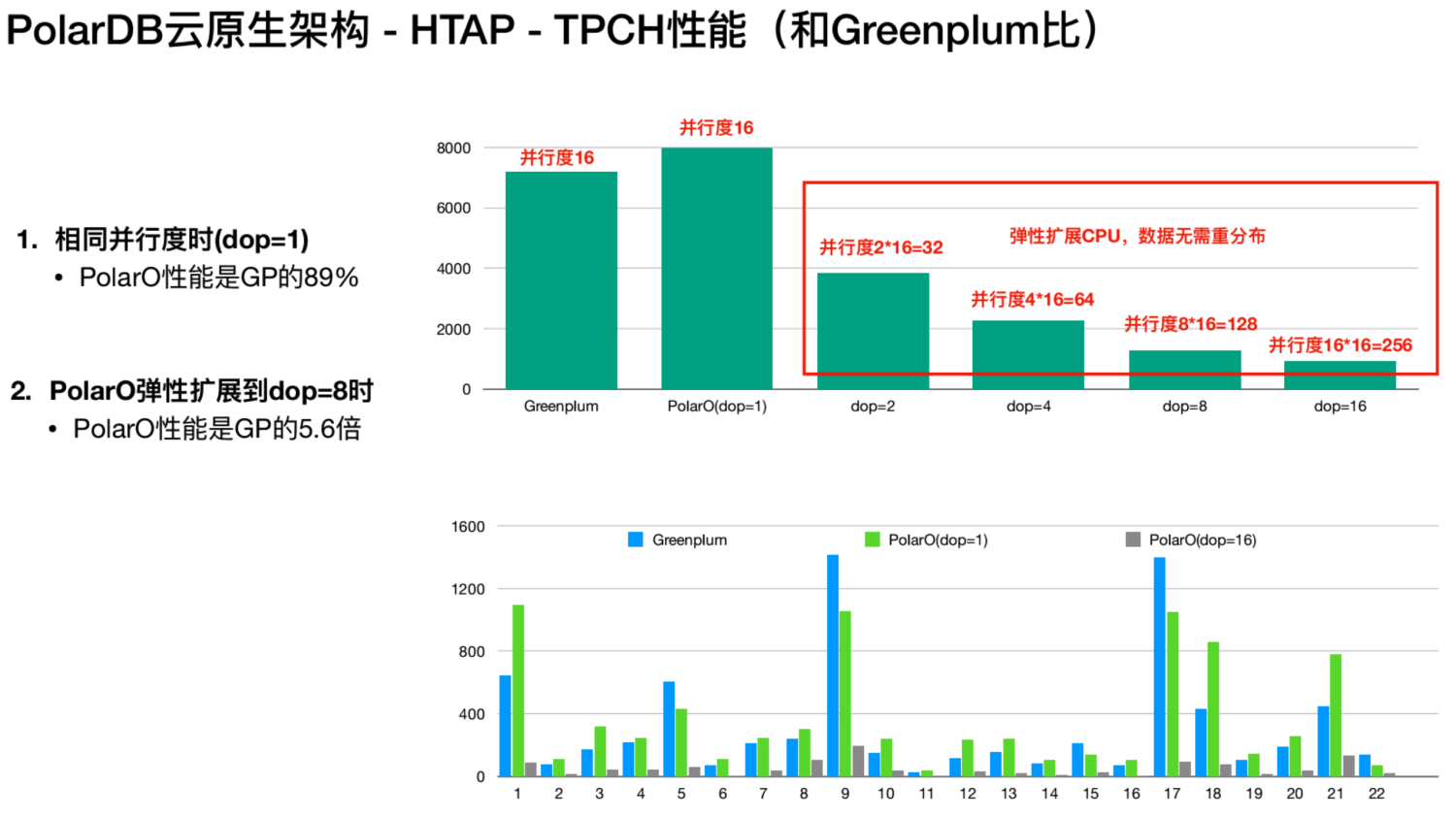
还有一组是 PolarDB 和 Greenplum 的对比。测试环境为相同的硬件,16个计算节点,1TB TPCH 。从上图中可以看到 Greenplum 有 16core和 16个 CPU 在做 SQL 处理。在采用相同并行度时,PolarO 的性能是 Greenplum 的89%。为什么在单核时 Polar 会达不到 Greenplum 的性能表现?这是因为数据在共享存储上是没有数据特征的, Greenplum 在建表的时候,数据默认做哈希分区,在两个表 join 时 join Key 和分布 Key 是一样的,不需要做数据的 Shuffle。而 Polar 只有一张表,这张表没有数据特征,是一个随机分布的数据格式。此时任何两个表去 join 的时候,都需要做一个shuffle,由于网络因素,Polar 单核性能表现只能达到 Greenplum 的89%。针对这个问题,我们将通过 PG 的分区表的方式进行优化。
虽然 Polar DB 底层的数据是共享的,但仍然可以以哈希的方式建一个分区表。这个时候可以将Polar DB的HTAP MPB的方式和Greenplum的方式对齐一致,这个功能实现之后,Polar 的单核性能和Greenplum就是一样的。图中红框部分我们又进行了四组测试,Polar DB 支持计算能力弹性扩展,此时数据是不需要重新分布的。这是数据随机分布的好处,在做分布式执行引擎的时候,第一优先级考虑的不是极致的性能,而是是系统的扩展性,即当你的计算能力不足的时候,可以快速增加节点来加速计算。
像 Greenplum 这类传统的 MPP 数据库,它的节点是固定,而Polar是无状态的,可以随时去做调整计算CPU数的。这组测试里面只需要调整一个GUC参数就能将Polar从16core变成256core,算力线性扩展。
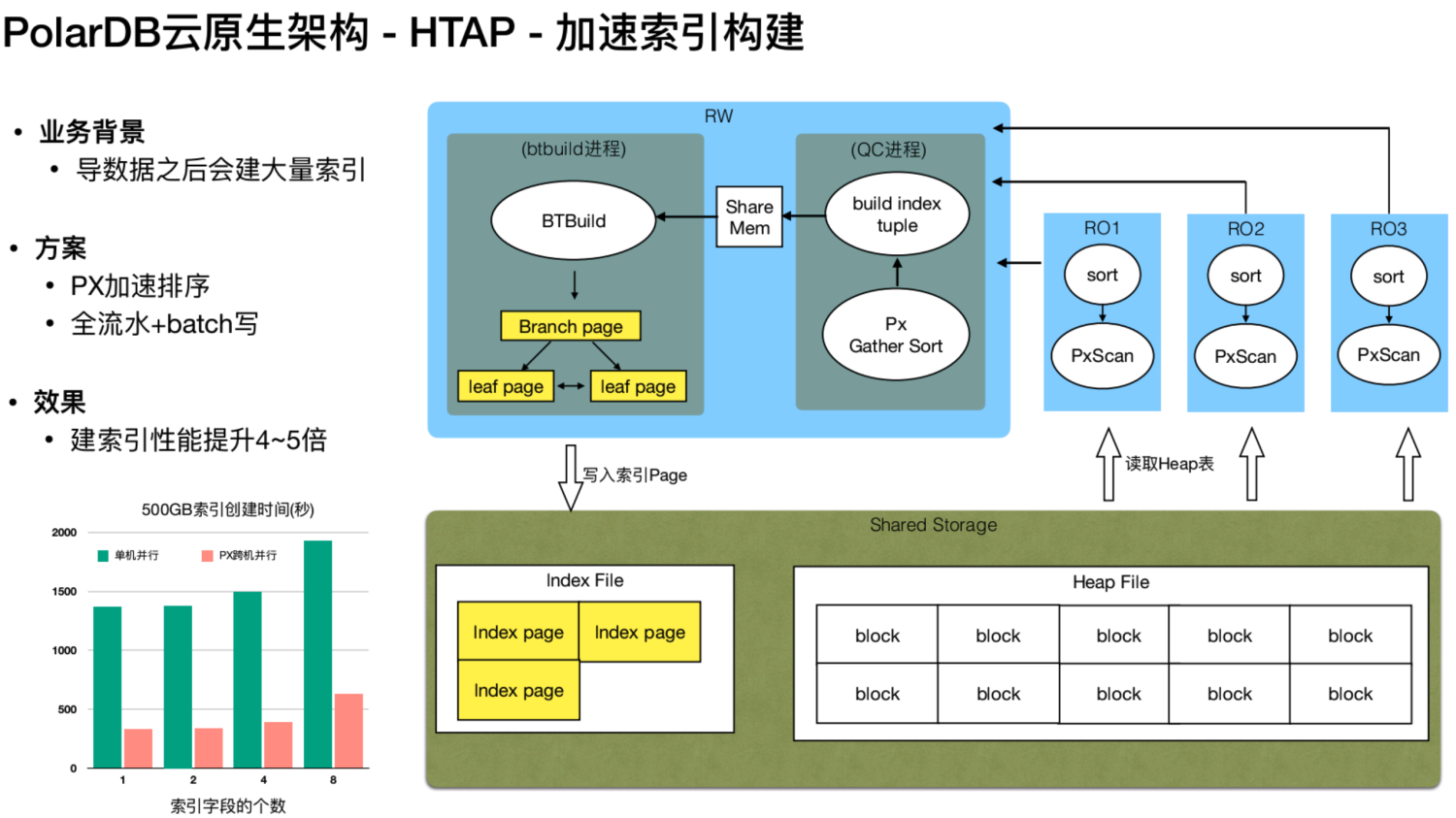
当 Polar DB 支持了MPP之后,还能做哪些事情?新上线的业务导入了大量的数据之后,需要做一些索引。其原理是先将数据进行排序,之后在内存里组织成一个索引页面,然后将这些页面直接写到盘上。如果Polar DB 支持并行之后,玩法就不一样了,从上图中可以看到,通过节点 RO1、RO2 和 RO3,可以并行地到共享存储上去扫描数据,然后并行地在本地进行排序。排完序之后,将数据通过网络传给RW节点。RW节点经过归并排序,将排序的数据,在内存里面组织成一个索引页,交给btbuild进程。在内存里面,通过索引页,去更新索引页之间的指向关系,来构建索引树的指令关系,然后开始写盘。
这个方案借助了多个节点的计算能力以及 RO 能力,在排序的阶段进行了加速。同时通过网络传给MPP 的一个QC节点,即中心节点。这个节点再通过共享内存,发给 btbuild 进程。经测试使用500G的数据来建索引,性能可以提升到五倍左右。
加速时空数据库
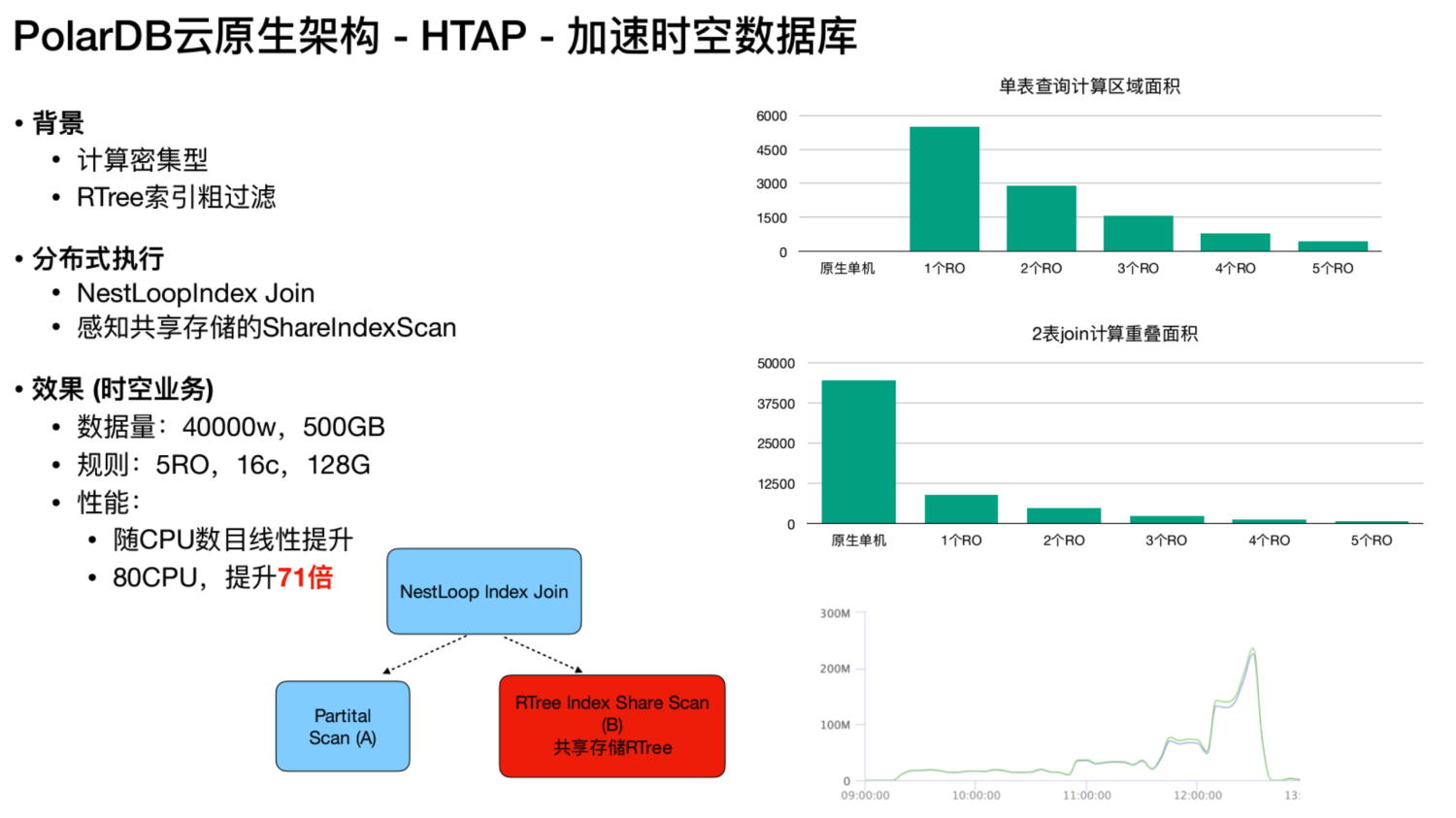
时空数据库是一个计算密集型的、用 RTree 索引的粗过滤。先通过RTree,然后通过空间踩点定位到一个区域,在这个区域里面,再进一步精确的过滤。共享存储的 index scan 的过程,RTree 扫描,只能用NestLoopIndex Join,因为是没有办法做哈希join的,这是因为 RTree 的二维空间没有办法做完整的切分。对于时空的业务都是通过 NestLoopIndex Join,从一个表里面拿到一个数据,然后到另外一个表里面的 RTree上扫描,这在 Greenplum上是无法做到的,因为它的索引树是被拆分的。但是在 PolarDB 里面,RTree的索引树是共享状态,那么无论 worker 是在节点1,还是在节点2上,在共享里存储理念里索引树都是完整的。这个时候两个worker就可以直接用外表做协调的切分。由于它是计算密集型的,那么它的加速效果会更加的好。经过测试,在80 CPU 的环境下,整体的提升能达到71倍。
以上就是关于 HTAP 架构的介绍,后续将会有更多实现上的细节分享,比如优化器、执行器、分布式一致性等,敬请期待。
