





导语
vsonichashjoin目前存在的问题
Hash表仅存储位置信息
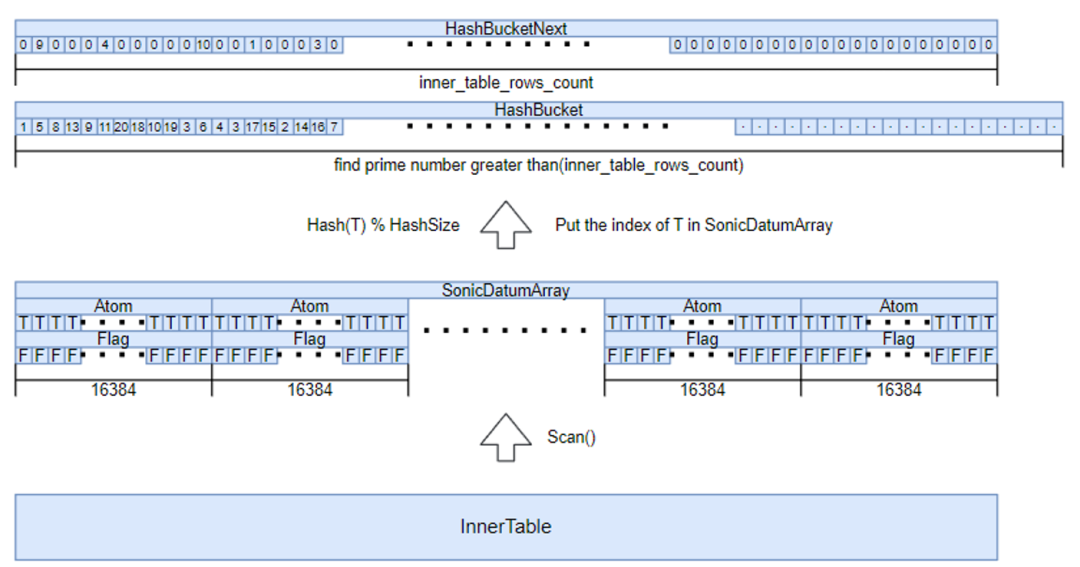
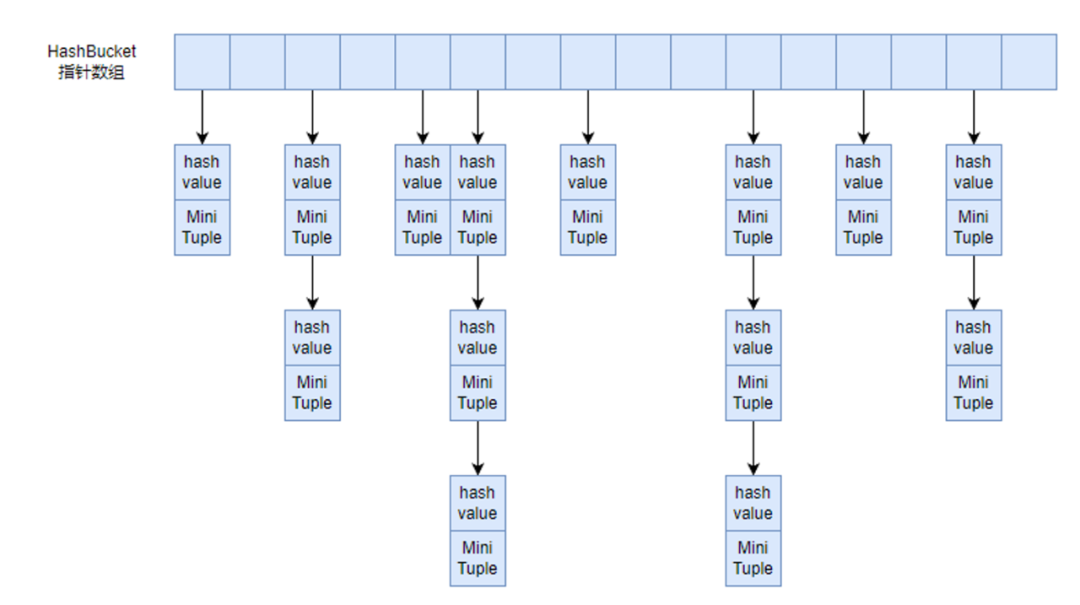
基于链表式的hash表无法更好的利用内存局部的原理,CPU会根据内存地址一次取一个cacheline(一般64字节)大小的内存放入CPU缓存中,而一个位置信息可能只占8字节,跳跃式的内存访问无法充分利用CPU缓存。
Hash表过大,CPU缓存装不下
hash表内存太大,无法放入L2cache,hash表会以cacheline为单位不断的在主存与缓存中间交换,交换的成本就是cachemiss所带来的CPU流水线的停顿。
由于join操作本身也需要一定的工作内存,并且join算子在Plan Tree上进行迭代,一旦投影到上层算子上的时候,整个内存布局就会发生改变,导致后续访问hash表时依然会cache miss。
优化方向1:在hash表中存储datavalue或者hashvalue来减少对底层datumarray的访问

优化方向2:在位置信息的高bit上加入提示信息,来指导下一次访问的方向,或者停止访问
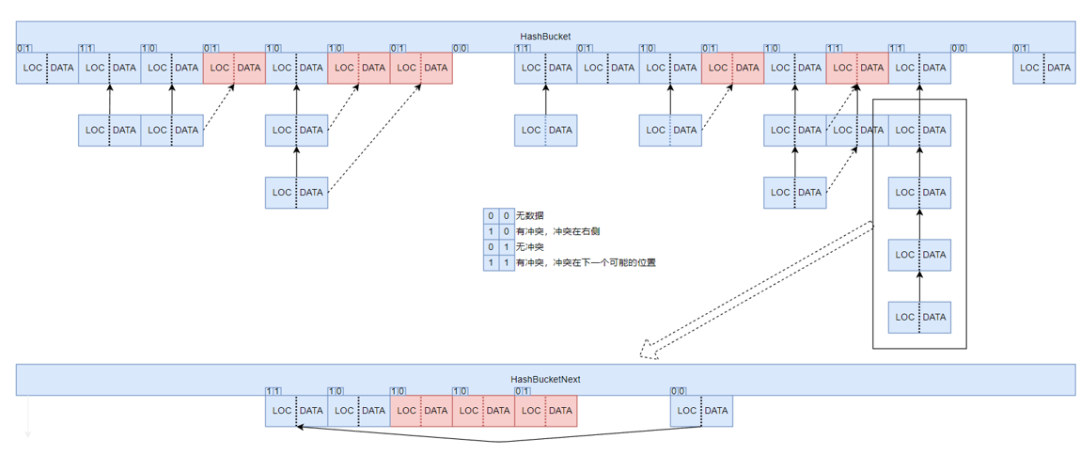
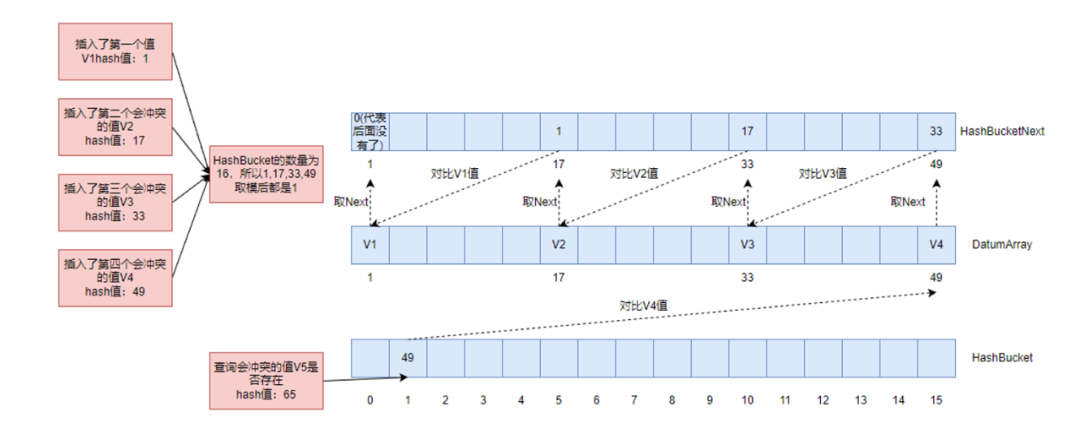
不难看出,表示位置的整型数据,高bit实际上大部分都是不使用的,一个int32bit,表示几百万数据可能只用了20多个bit而已,我们可以利用高bit的数据作为hint,来对冲突进行指示。
这里实际上是只用了2bit,4种组合来指示冲突的位置,这个做法实际上对解决冲突的内存访问性能得到了的提升。因为基于原来的实现,必须要访问next数组,检查值是否为0,才能判断出后面是否还有冲突,现在只要访问当前元素的位置信息的高bit,就可以检查出这个元素后面是否还有冲突,避免了无效的内存访问。
我们还可以组合链表方式与线性探测的方式,先使用链表方式解决冲突,然后探测冲突的链表是否可以在右侧展平。
优化方向3:改用线性探测的方式,但一个hashbucket不只存储一个元素,而是一组元素,并添加位图

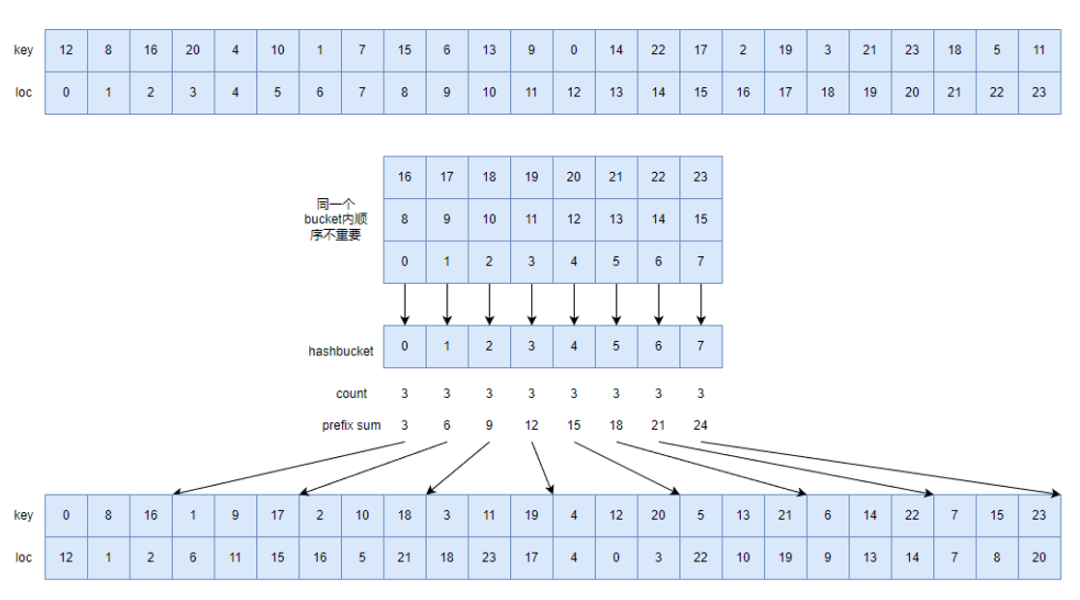
优化方向4:从根本上解决hash冲突,对原始数据进行重新排列
优化方向5:将大的hash表根据缓存大小切分成多个分区,每个分区独自完成join
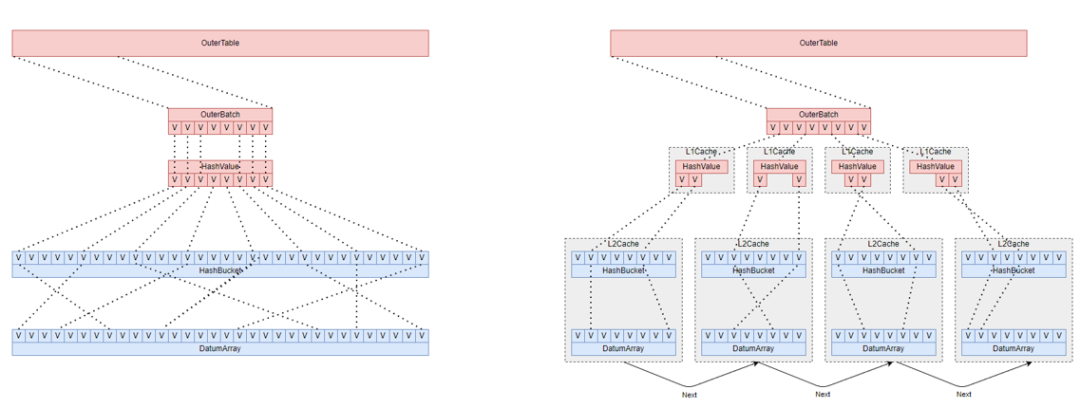
优化方向6:基于分区的hashjoin,可以自由决定完成每个小分区的join方式
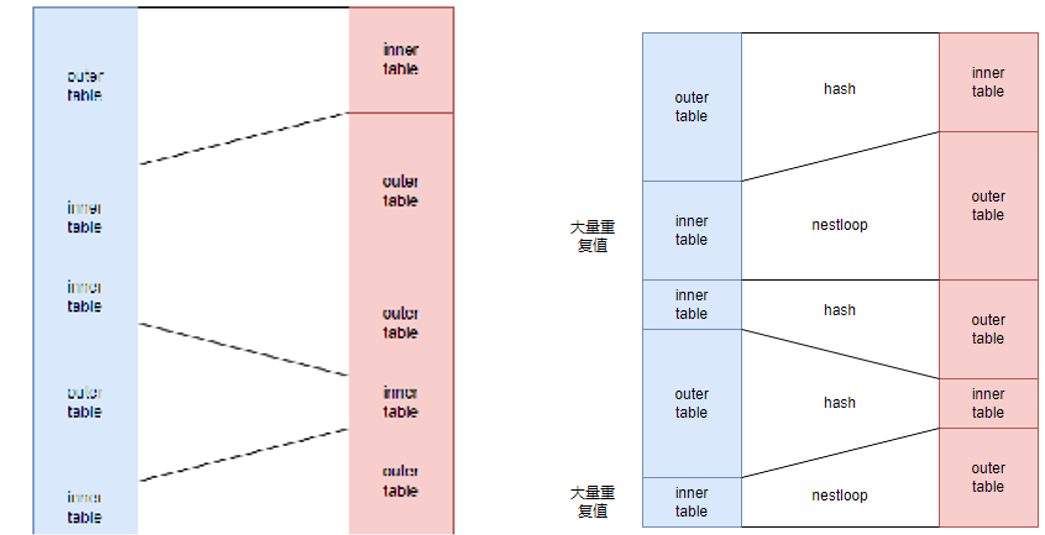
vsonichashjoin算子优化实现效果
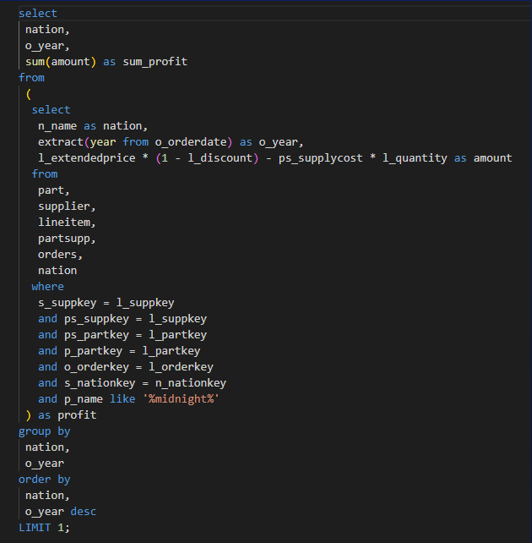
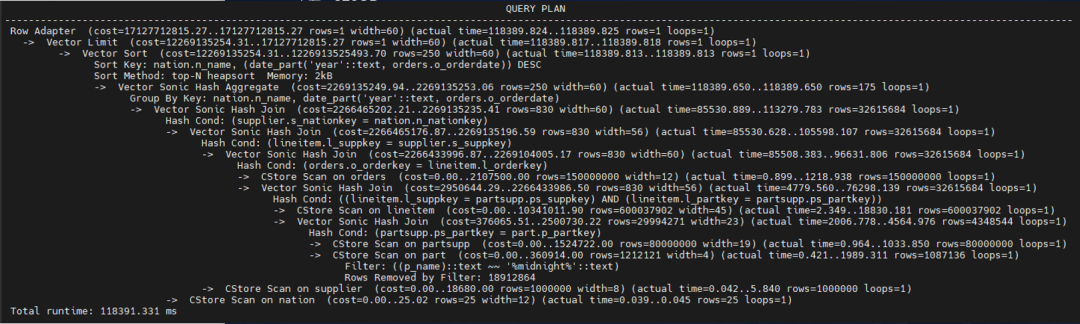
(优化前)
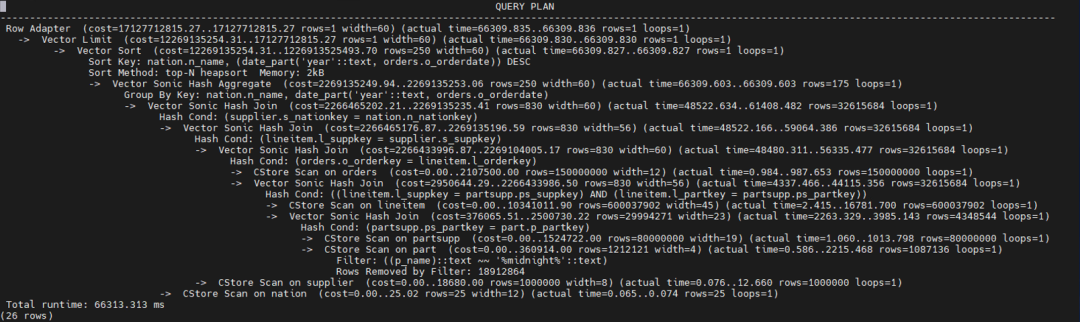
(优化后)
图文编辑|程筱淇
内容审核|市场营销部
关于海量数据
北京海量数据技术股份有限公司(股票代码:603138.SH)成立于2007年,是国内首家以数据库为主营业务的主板上市企业。公司十余年来秉承“专注做好数据库”的初心,始终致力于数据库产品的研发、销售和服务。核心产品海量数据库Vastbase系列、数据库一体机Vastcube系列,全栈国产化,应用满足度高,目前广泛应用于政务、制造、金融、通信、能源、交通等多个重点行业,已成为国产企业级数据库的首选之一。

