




引言
本文将围绕图数据库、图计算、图学习三大版块,为大家揭秘关于“图”的奥秘。
DataFun社区|出品
数据智能专家访谈 第21期|来源
01.
图库数据


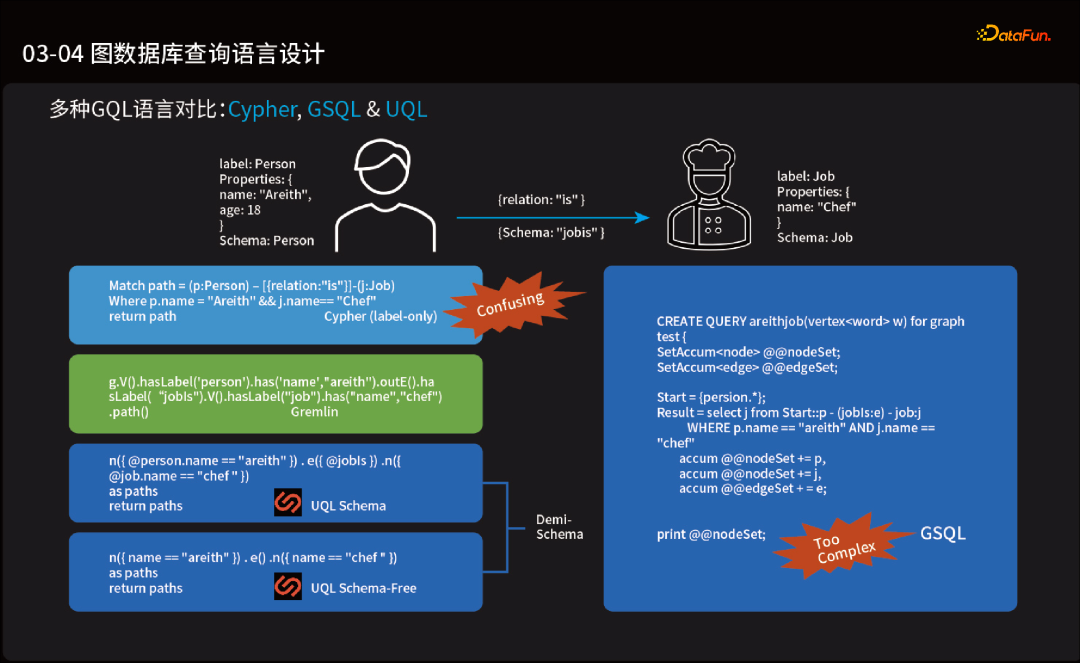
02.
图计算可以简单地等同于图处理框架、图计算引擎(graph computing engines),它的主要工作是对已有的数据进行计算和分析。图计算框架多数都出自学术界,这个和图论自20世纪60年代与计算机学科发生学科交叉并一直不断演化有关。 图计算框架在过去20年中,主要发展是在OLAP(联机分析处理)场景中进行数据批处理。
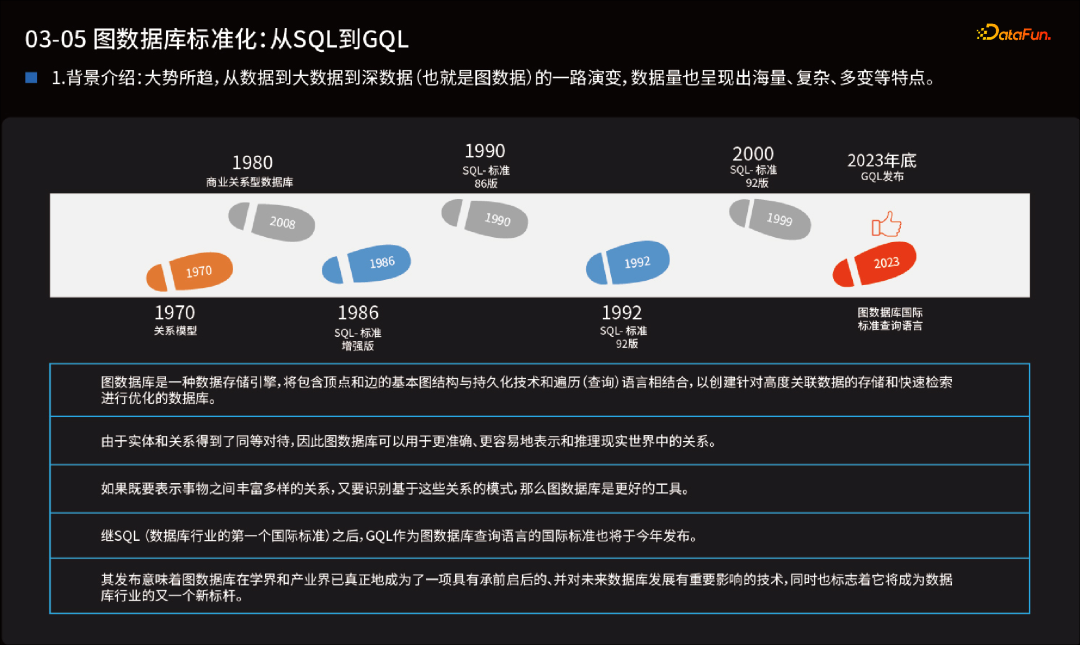
图数据库的出现要晚得多,最早可以称之为图数据库的也要到20世纪90年代,而真正的属性图或原生图技术在2011年后才出现。 图数据库的框架主要功能可以分为三大部分:存储、计算与面向应用的服务(例如数据分析、决策方案提供、预测等)。其中计算部分,包含图计算,但是图数据库通常可以处理AP与TP类操作,也就是说可以兼顾OLAP与OLTP(在线事务处理),两者的结合也衍生出了新的HTAP类型的图数据库,简言之,从功能角度上看,图数据库是图计算的超集。
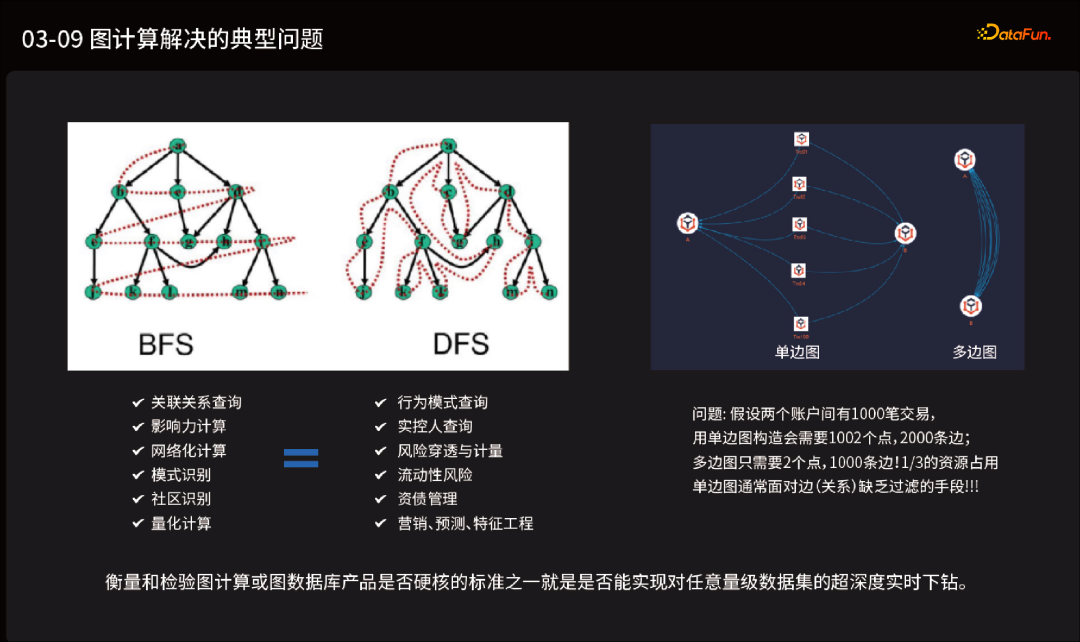
图计算与图数据库有个重要的差异点:图计算通常只关注和处理静态的数据,而图数据库则能处理动态的数据。换言之,图数据库在数据动态变化的同时能保证数据的一致性,并能完成业务需求。这两者的区别基本上也是AP和TP类操作的区别之所在。 多数图计算框架都源自学术界,其关注的要点和场景与工业界的图数据库有很大的不同。前者在创建之初大都面向静态的磁盘文件,通过预处理、加载入磁盘或内存后进行处理;而后者,特别是在金融、通信、物联网等场景中,其数据是不断流动、频繁更新的。静态的计算框架不可能满足各类业务场景的需求,这也催化了图数据库的不断迭代。 再者,图计算框架一般只关注图本身的拓扑结构,并不需要理会图上的点和边的复杂属性问题,而这对于图数据库而言则是必须关注的。事实上,目前很多所谓的图数据库并不具备在下钻查询时(例如路径查询、K 邻查询、图算法等场景下)对点、边属性进行无差别过滤的能力。



K 邻查询是否支持指定某一深度返回其全部邻居,即返回第 K 层的全部邻居。很多图数据库只支持返回 1 到 K 层的邻居,但是不支持第 K 层(或任意其它层级)的邻居!大家应该明白,这两种模式之间有着计算复杂度的天壤之别 —— 支持仅返回第 K 层的模式,需要更强的算力、遍历模式与数据结构支撑,而第 1-至-第 K 层返回的模式,则是典型的一锅烩,其算法复杂度不可同日而语,而且极有可能是实现逻辑错误,无法严格区分某个邻居的最短路径距离。 超级节点是否可以穷举遍历与穿透的问题:某些图数据库系统宣称在遇到超级节点时,采用抽样的逻辑,这是典型的谬误!无论是否是超级节点,如果对其进行穿透,例如查询其 3-hop 邻居,必须采用全量计算的逻辑,岂能“抽样”来糊弄了事?以 Twitter 数据集为例,14.7 亿条边,4200 万顶点,其中有大量顶点存储在百万条以上关联边(关系),在图查询上,遇上这些(超级)顶点的概率很大,图计算是要求精准计算的,岂能采用抽样的方式来返回结果呢?
03.
图学习
1.揭开图的面纱
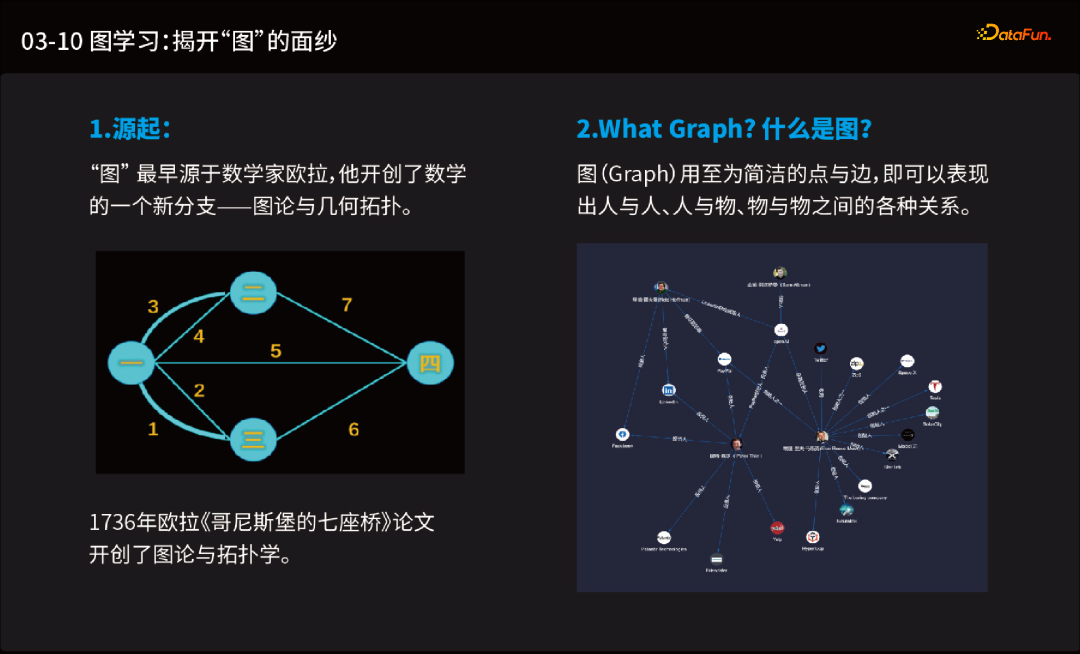


▼
04.
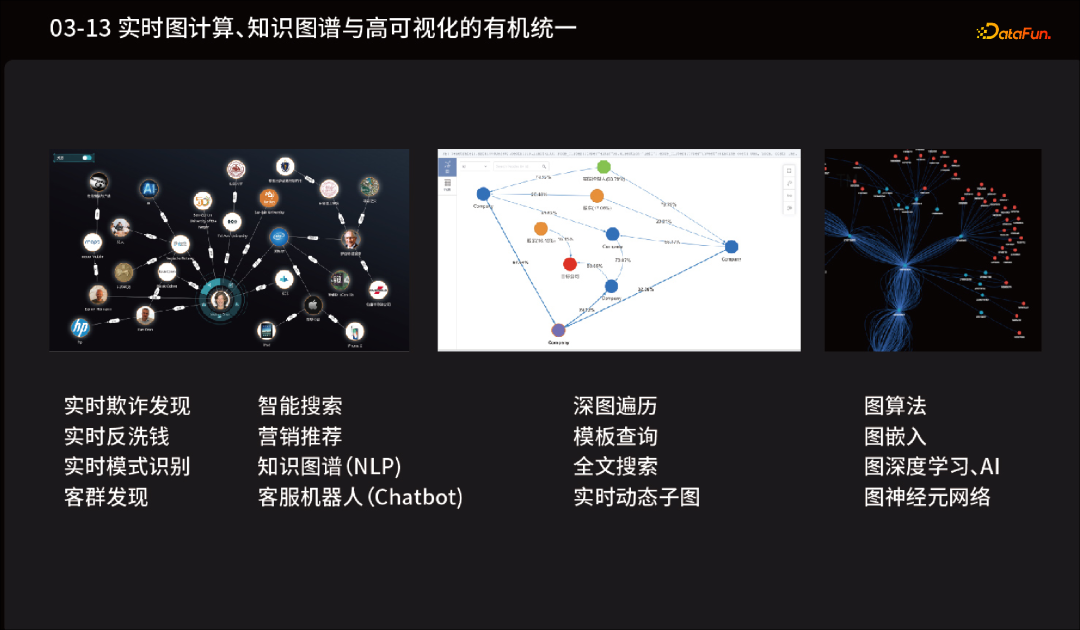
金融服务:金融领域中的许多问题都涉及到复杂的数据关系,如投资组合优化、客户风险评估等。 社交网络:图数据库可以帮助社交网络提供更好的推荐算法,实现更精准的匹配。 医疗保健:医疗保健领域中的数据非常复杂,包括医疗记录、医疗设备、医疗服务等多个方面。 电力与能源:电力和能源行业需要处理大量的设备、供应商、能源来源等数据,图更好地管理和分析这些数据,优化能源生产和分配,提高效率。 物流与供应链:物流和供应链领域涉及大量的供应商、分销商、运输方式等复杂关系。 零售业:可赋能零售商更好地分析和管理客户、产品、库存等数据,实现更精准的推荐算法。 政企:路网规划、智能交通、疫情精准防疫等等。 电商推荐:随着海量数据涌现,图数据库技术可赋能于全行业的各种场景应用中。

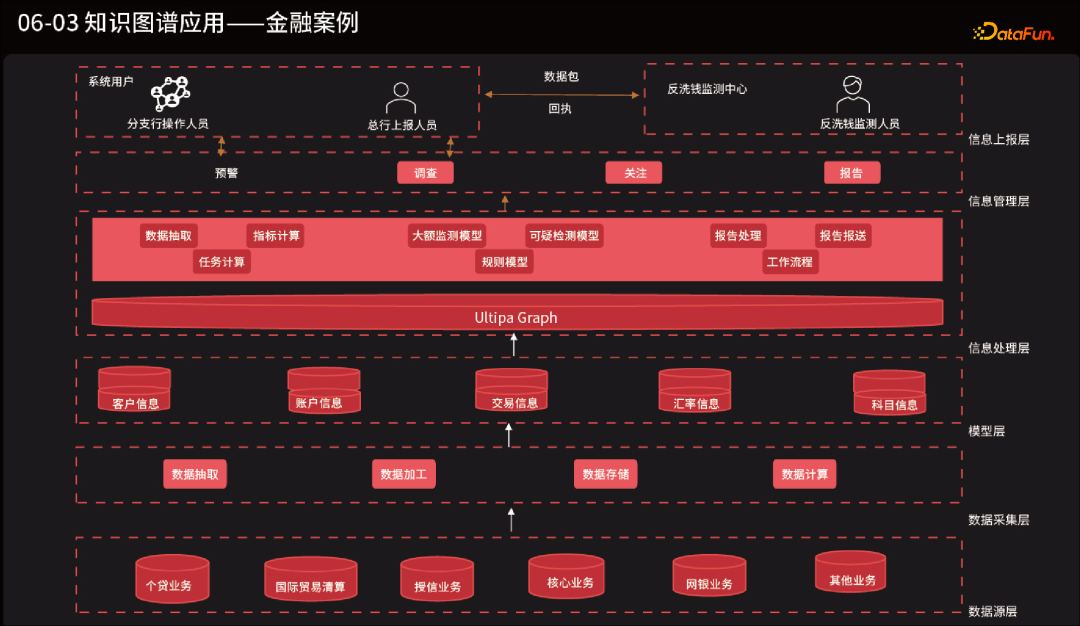
一是金融风险管理。图数据库可以将客户、账户、交易、事件等多维度的数据整合到一个平台,利用计算、图查询、图分析等技术进行风险识别和管理。通过分析客户和账户之间的关联关系、账户之间的资金流转关系等,更好地发现潜在风险,及时采取相应的措施。 二是金融欺诈检测。图数据库可以将金融交易数据存储为点和边的形式,这样可以更方便地发现交易之间的关联关系。例如,同一人在不同时间、不同地点使用不同的账户进行交易,这些行为可能表明欺诈行为的存在。通过对这些关联关系进行分析,可以更高效、更准确地识别和预防欺诈行为。 三是知识图谱构建。金融机构可以利用图数据库技术构建知识图谱,将客户、账户、交易、风险、合规等相关信息进行整合形成一个图谱。这样可以更好地实现对客户360度全景视图,更快地识别客户需求、风险和潜在机会。需要注意的是,尽管很多厂家都可以构造图谱,但是,缺乏图数据库的算力支撑的图谱,效率是非常低下的。 四是市场营销分析。图数据库可以帮助金融机构更好地了解市场、行业、公司之间的关联关系。例如公司之间的合作、竞争、股权交易等。这样可以更好地预测市场趋势,优化投资组合。

3.反洗钱(AML)案例
实体关系分析:图数据库可以用于建立和维护不同实体(如个人、组织、账户等)之间的复杂关系网络。通过这些关系网络,可以检测到洗钱行为中隐藏的模式和连接,如通过虚假账户进行资金转移、多个账户之间的交易模式等。 风险评估:图数据库可以整合和分析来自多个数据源的信息,如交易记录、客户资料、开数据等,以绘制客户和账户的全面画像。通过分析这些数据的关系和属性,可以进行风险评估并识别潜在的洗钱风险。 异常检测:图数据库可以监测和分析大规模的交易数据,以便及时识别异常模式和行为。例如,如果一个账户与大量与洗钱有关的实体有关联,或者账户的交易模式与同类账户明显不同,就可能存在洗钱风险。图数据库可以帮助发现这些异常模式,并提供警报和推荐的行动。 实时分析:图数据库的优势之一是能够处理实时数据,并快速更新和查询图结构。这对于反洗钱来说非常重要,因为洗钱行为可能是动态变化的。图数据库可以通过实时分析来及时发现和应对新出现的洗钱模式和策略。 可视化分析:图数据库可以通过可视化工具将复杂的关系网络呈现给分析人员,帮助他们更好地理解和发现洗钱行为。可视化分析可以揭示隐藏的模式、群组和其他结构,从而帮助分析人员做出更准确的决策。
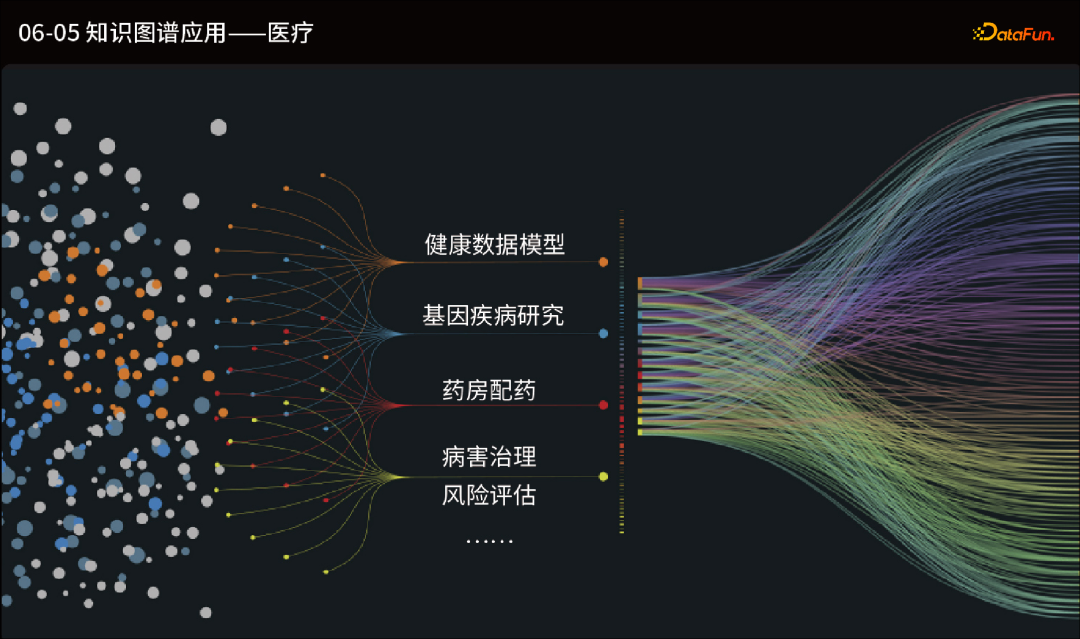
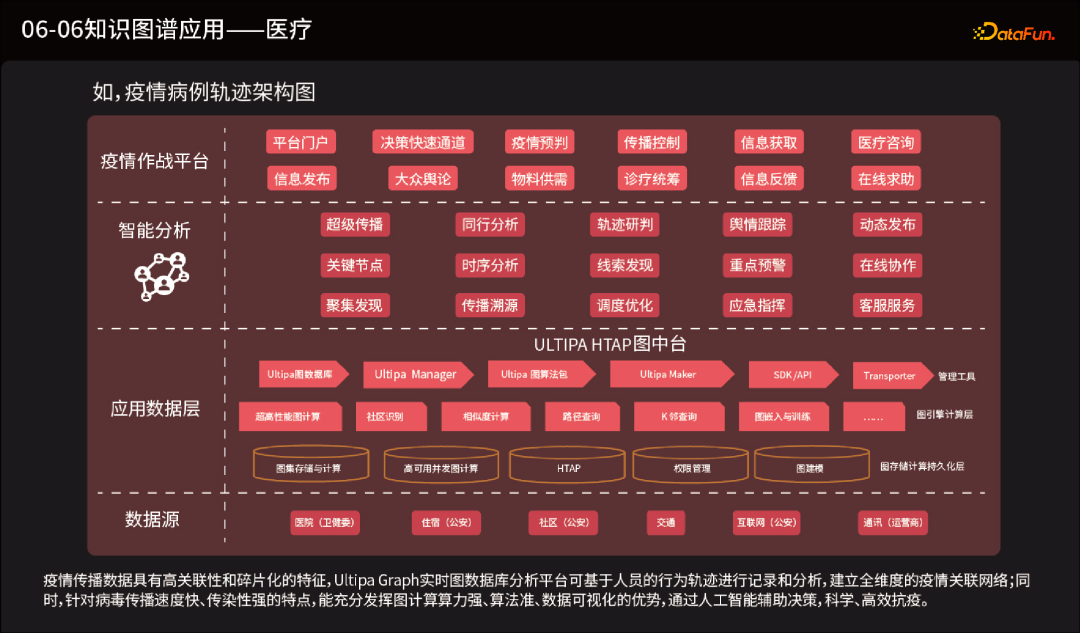
药物研发和发现:图数据库可以帮助科研人员分析药物、疾病和基因之间的关系。通过构建药物-靶标-疾病关联的网络,可以发现新的治疗方法、药物靶点和药物组合,加快药物研发过程。 临床决策支持:图数据库可以整合和分析临床数据、患者数据和医学知识,帮助医生做出更准确的诊断和治疗决策。通过构建患者的健康数据图谱,可以提供个性化的治疗方案和预测风险。 医疗资源管理:图数据库可以用于管理医疗资源,例如医院设施、医生和患者之间的关系。通过分析资源之间的连接和使用情况,可以优化医疗资源的分配和利用,提高医疗服务的效率和质量。 健康监测和预测:图数据库可以整合和分析大规模的健康数据,例如传感器数据、基因组学数据和生物标志物数据。通过构建健康数据图谱,可以监测个体或群体的健康状态,并进行风险预测和疾病预防。 疾病网络分析:图数据库可以用于构建疾病之间的关联网络,帮助医疗专业人员了解疾病之间的关系、风险因素和传播路径。通过分析这些网络,可以提供更好的诊断和治疗决策支持,等等。
分享嘉宾:孙宇熙
视频录音:孙婉怡
文章转载自图谱学苑,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
